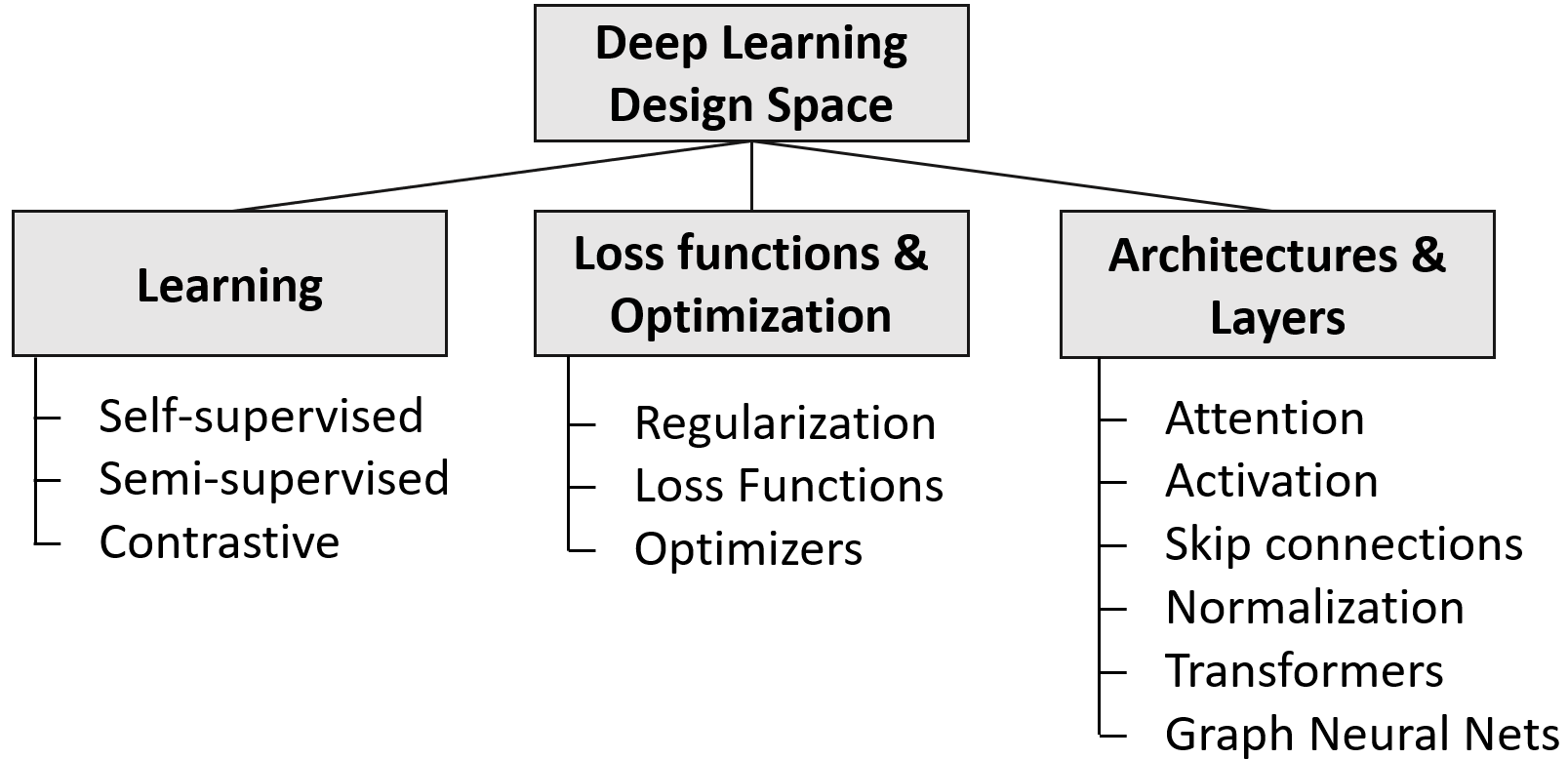
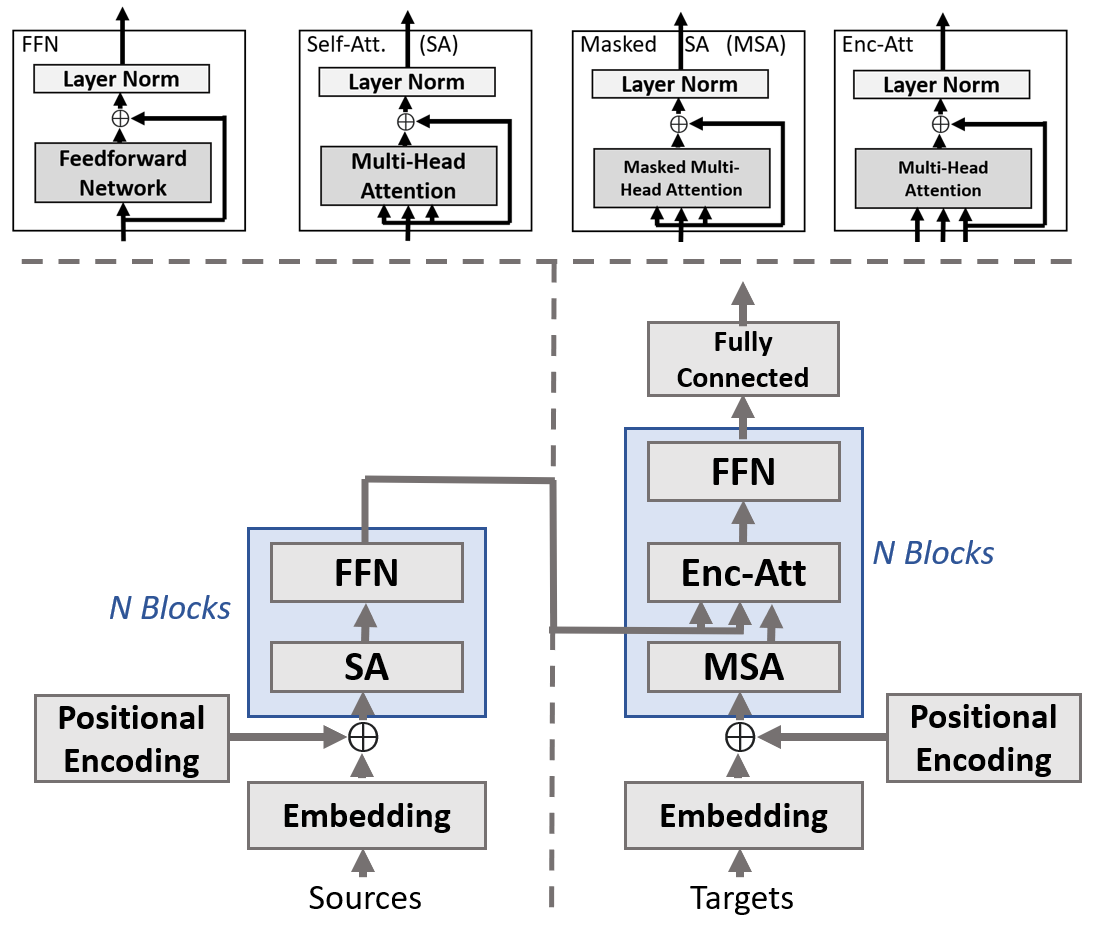
A Survey of Deep Learning: From Activations to Transformers
Abstract: Deep learning has made tremendous progress in the last decade. A key success factor is the large amount of architectures, layers, objectives, and optimization techniques. They include a myriad of variants related to attention, normalization, skip connections, transformers and self-supervised learning schemes -- to name a few. We provide a comprehensive overview of the most important, recent works in these areas to those who already have a basic understanding of deep learning. We hope that a holistic and unified treatment of influential, recent works helps researchers to form new connections between diverse areas of deep learning. We identify and discuss multiple patterns that summarize the key strategies for many of the successful innovations over the last decade as well as works that can be seen as rising stars. We also include a discussion on recent commercially built, closed-source models such as OpenAI's GPT-4 and Google's PaLM 2.
- A state-of-the-art survey on deep learning theory and architectures. electronics.
- Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. Journal of big Data.
- A survey on modern trainable activation functions. Neural Networks.
- Layer normalization. arXiv:1607.06450.
- Tucker: Tensor factorization for knowledge graph completion. arXiv:1901.09590.
- Longformer: The long-document transformer. arXiv:2004.05150.
- A general survey on attention mechanisms in deep learning. Transactions on Knowledge and Data Engineering.
- Language models are few-shot learners. Advances in neural information processing systems.
- A simple framework for contrastive learning of visual representations. In Int. Conf. on machine learning.
- Generating long sequences with sparse transformers. arXiv:1904.10509.
- Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
- Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805.
- A survey on deep learning and its applications. Computer Science Review.
- Triplet loss in siamese network for object tracking. In European Conf. on computer vision (ECCV).
- An image is worth 16x16 words: Transformers for image recognition at scale. arXiv:2010.11929.
- A generalization of transformer networks to graphs. arXiv:2012.09699.
- Self-supervised representation learning: Introduction, advances, and challenges. Signal Processing Magazine.
- Sharpness-aware minimization for efficiently improving generalization. arXiv:2010.01412.
- Dropblock: A regularization method for convolutional networks. Advances in neural information processing systems.
- Google (2023). Palm 2 technical report. https://ai.google/static/documents/palm2techreport.pdf.
- Bootstrap your own latent-a new approach to self-supervised learning. Adv. in neural information processing systems.
- node2vec: Scalable feature learning for networks. In ACM SIGKDD Int. Conf. on Knowledge discovery and data mining.
- Visual attention network. arXiv:2202.09741.
- Attention mechanisms in computer vision: A survey. Computational Visual Media.
- A survey on vision transformer. transactions on pattern analysis and machine intelligence.
- Momentum contrast for unsupervised visual representation learning. In Conf. on computer vision and pattern recognition.
- Deep residual learning for image recognition. In Conf. on computer vision and pattern recognition.
- Gaussian error linear units (gelus). arXiv:1606.08415.
- Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems.
- Densely connected convolutional networks. In Conf. on computer vision and pattern recognition.
- Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Int. Conf. on machine learning.
- Averaging weights leads to wider optima and better generalization. arXiv:1803.05407.
- Analyzing and improving the image quality of stylegan. In Conf. on computer vision and pattern recognition.
- A survey of the recent architectures of deep convolutional neural networks. Artificial intelligence review.
- Transformers in vision: A survey. ACM computing surveys (CSUR).
- Supervised contrastive learning. Advances in neural information processing systems.
- Stochastic estimation of the maximum of a regression function. The Annals of Mathematical Statistics.
- Adam: A method for stochastic optimization. arXiv:1412.6980.
- Semi-supervised classification with graph convolutional networks. arXiv:1609.02907.
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880.
- Focal loss for dense object detection. In Int. Conf. on computer vision.
- On the variance of the adaptive learning rate and beyond. arXiv:1908.03265.
- Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys.
- Generating wikipedia by summarizing long sequences. arXiv:1801.10198.
- Roberta: A robustly optimized bert pretraining approach. arXiv:1907.11692.
- Swin transformer: Hierarchical vision transformer using shifted windows. In Int. Conf. on computer vision.
- Decoupled weight decay regularization. arXiv:1711.05101.
- Which training methods for GANs do actually converge? In Int. Conf. on machine learning.
- Recent advances in natural language processing via large pre-trained language models: A survey. arXiv preprint arXiv:2111.01243.
- Misra, D. (2019). Mish: A self regularized non-monotonic activation function. arXiv:1908.08681.
- Asynchronous methods for deep reinforcement learning. In Int. Conf. on machine learning.
- A survey of regularization strategies for deep models. Artificial Intelligence Review.
- Rectified linear units improve restricted boltzmann machines. In Int. Conf. on machine learning (ICML-).
- OpenAI (2022). Chatgpt: Optimizing language models for dialogue. https://openai.com/blog/chatgpt/.
- OpenAI (2023). Gpt-4 technical report.
- Training language models to follow instructions with human feedback. arXiv:2203.02155.
- Improving language understanding by generative pre-training.
- Language models are unsupervised multitask learners. OpenAI blog.
- Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research.
- Searching for activation functions. arXiv preprint arXiv:1710.05941.
- On the convergence of adam and beyond. arXiv:1904.09237.
- Mobilenetv2: Inverted residuals and linear bottlenecks. In Conf. on computer vision and pattern recognition.
- DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv:1910.01108.
- Learning a distance metric from relative comparisons. Advances in neural information processing systems, 16.
- Is normalization indispensable for training deep neural network? Advances in Neural Information Processing Systems.
- Adafactor: Adaptive learning rates with sublinear memory cost. In Int. Conf. on Machine Learning.
- Review of deep learning algorithms and architectures. IEEE access.
- Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Advances in neural information processing systems.
- Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research.
- Sun, R.-Y. (2020). Optimization for deep learning: An overview. Operations Research Society of China.
- Rotate: Knowledge graph embedding by relational rotation in complex space. arXiv:1902.10197.
- Going deeper with image transformers. In Int. Conf. on Computer Vision.
- Instance normalization: The missing ingredient for fast stylization. arXiv:1607.08022.
- Attention is all you need. Advances in neural information processing systems.
- Graph attention networks. arXiv:1710.10903.
- Residual attention network for image classification. In Conf. on computer vision and pattern recognition.
- A comprehensive survey of loss functions in machine learning. Annals of Data Science.
- Function optimization using connectionist reinforcement learning algorithms. Connection Science.
- A comprehensive survey on graph neural networks. Transactions on neural networks and learning systems.
- Self-training with noisy student improves imagenet classification. In Conf. on computer vision and pattern recognition.
- Aggregated residual transformations for deep neural networks. In Conf. on computer vision and pattern recognition.
- A survey on deep semi-supervised learning. Transactions on Knowledge and Data Engineering.
- Xlnet: Generalized autoregressive pretraining for language understanding. Advances in neural information processing systems.
- Large batch optimization for deep learning: Training bert in 76 minutes. arXiv:1904.00962.
- Barlow twins: Self-supervised learning via redundancy reduction. In Int. Conf. on Machine Learning.
- Unpaired image-to-image translation using cycle-consistent adversarial networks. In Int. Conf. on computer vision.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.