- The paper introduces PRANC, which reparameterizes deep models as a linear combination of fixed pseudo-random basis networks to drastically reduce storage.
- The methodology optimizes coefficients via standard backpropagation, enabling efficient training and inference on memory-constrained devices.
- Experiments demonstrate that PRANC maintains competitive accuracy in image classification and compression while reducing parameters nearly 100-fold.
PRANC: Pseudo RAndom Networks for Compacting Deep Models
Introduction
This paper introduces PRANC, a framework designed to reparameterize deep models as linear combinations of pseudo-randomly initialized networks, termed "basis networks." The motivation behind PRANC is to effectively compact deep models, making them easier to store and communicate in environments with limited resources. This approach is particularly beneficial for multi-agent learning, federated systems, and edge devices. By leveraging the linear combination of frozen random models, PRANC can condense a model to just the seed of a pseudo-random generator and the learned coefficients, allowing a nearly 100-fold reduction in storage requirements without sacrificing performance.
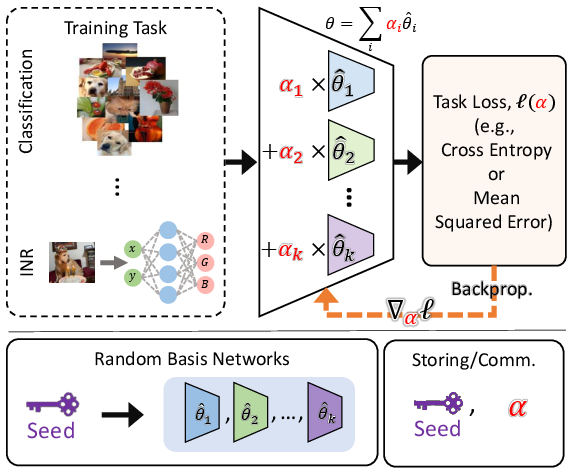
Figure 1: We restrict the deep model to be a linear combination of k randomly initialized models. Since the number of models is much less than the size of the model, it is much less expensive to communicate or store the coefficients compared to the model or data itself. We tune α to minimize the loss of the task using standard backpropagation.
Methodology
Model Reparameterization
The core of PRANC is to represent a deep model θ as a linear combination of k basis models: θ=∑j=1kαjθ^j. These basis models are initialized randomly and remain fixed during training. By optimizing the coefficients α, PRANC can effectively perform training and reduce the model's storage requirements.
Optimization and Efficiency
PRANC optimizes the coefficients α using standard backpropagation, which is efficient because the derivative of the loss with respect to α involves simple computations with the fixed basis models. The framework ensures both training and inference efficiencies by segmenting the basis networks into manageable chunks and using a pseudo-random generator to create them on the fly. This reduces memory usage considerably, an advantage when reconstructing models on-demand or on memory-constrained devices.
Security and Privacy
The pseudo-random basis networks generated by PRANC enable private and secure model communications. Altering the seed value results in entirely different basis models, rendering intercepted coefficients (α) virtually useless without the correct seed.
Applications
Image Classification
In image classification, PRANC excels by compacting models such as ResNet into a fraction of their original parameter counts while maintaining competitive accuracy levels. The framework outperforms traditional methods like pruning and distillation by a significant margin, demonstrating its utility in reducing model size drastically without architectural changes.
Image Compression
PRANC's robust framework also extends to image compression. By compacting the weights of implicit neural representations (INRs) for images, PRANC allows for more efficient storage and transmission of image data. Performance comparisons show consistent improvements over established methods like JPEG, particularly in PSNR and MS-SSIM evaluations.
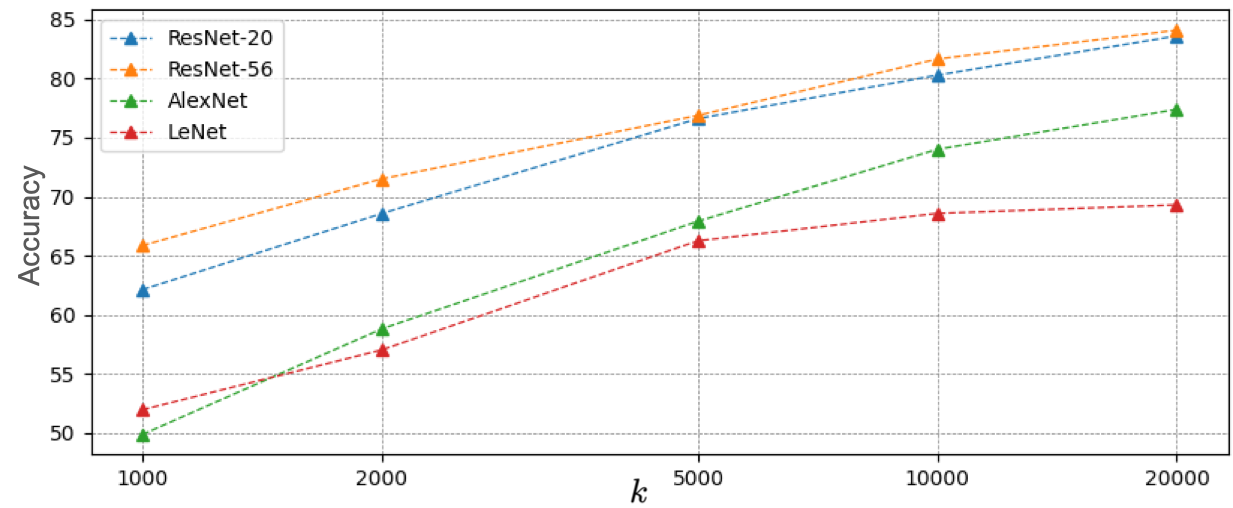
Figure 2: Illustration of impact of k in accuracy of different architectures on CIFAR-10. The accuracy improves by increasing the number of basis models. However, the architecture plays a more critical role in accuracy compared to the number of bases.
Experiments and Results
PRANC's empirical success is evidenced through various trials on both image classification and compression tasks across several datasets and architectures. Notably, its comparison against state-of-the-art model pruning and dataset distillation techniques highlights its superior performance in accuracy versus parameter efficiency. In large-scale tests on ImageNet100 using ResNet-18, PRANC achieves impressive accuracy with less than 1% of the parameters, showcasing its scalability and effectiveness.
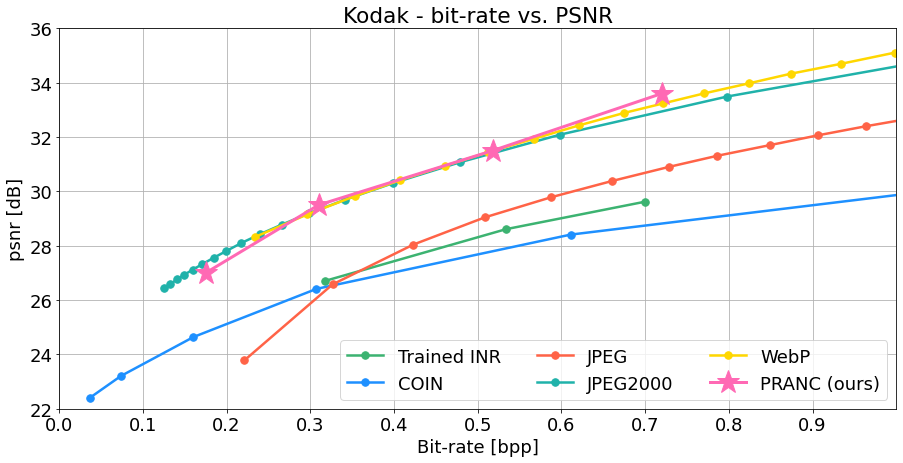
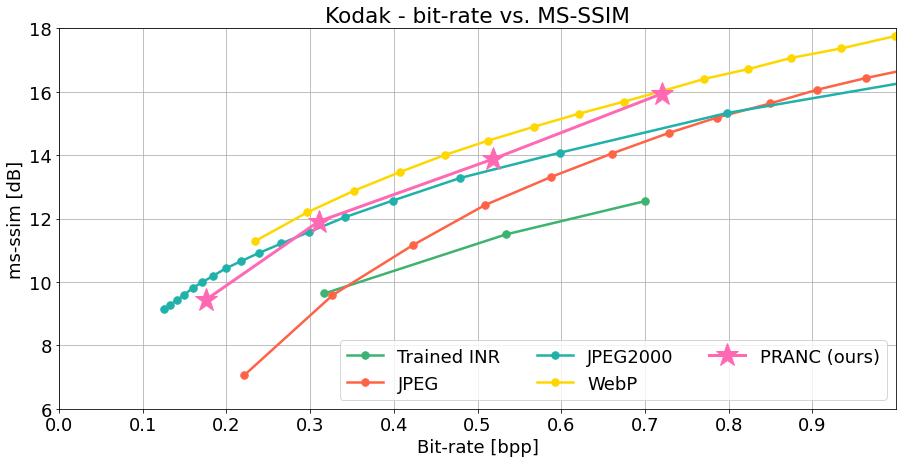
Figure 3: Kodak Dataset Image Compression: Our method outperforms JPEG and `trained INR' on both PSNR and MS-SSIM evaluations at various bitrates. Note that, unlike the other baselines, our method is learned on a single image and is not hand-crafted, except for the architecture of the INR model, which is a simple MLP.
Conclusion and Future Directions
The PRANC framework offers a novel and effective approach to model compaction, crucial for applications requiring efficient model storage and communication. While there are limitations in its current scope, such as potential inefficiency with exceedingly large basis counts, PRANC sets a foundation for further exploration in model compression and distributed learning.
Future avenues for PRANC include enhancing its progressive compaction capabilities and extending its applicability to generative models in memory-replay scenarios. Moreover, a deeper investigation into its theoretical aspects regarding solution space confinement can yield broader implications for optimizing overparametrized systems.