- The paper demonstrates that the Momentum Transformer significantly improves risk-adjusted performance, enhancing the Sharpe ratio by over 100%.
- The architecture fuses self-attention with LSTM layers to capture long-term dependencies and address abrupt market regime shifts effectively.
- It offers interpretability through variable importance analysis and changepoint detection, facilitating robust and cost-efficient trading strategies.
This paper introduces the Momentum Transformer, a novel deep-learning architecture designed for executing momentum-based trading strategies. Unlike conventional LSTM architectures traditionally employed for time-series momentum trading, the Momentum Transformer leverages attention mechanisms to directly access past time-steps, allowing the model to learn longer-term dependencies. This hybrid approach, combining attention with LSTM layers, enhances adaptability to abrupt market regime shifts, such as the SARS-CoV-2 crisis, while maintaining superior returns net of transaction costs.
Architecture and Design
The Momentum Transformer integrates several key components:
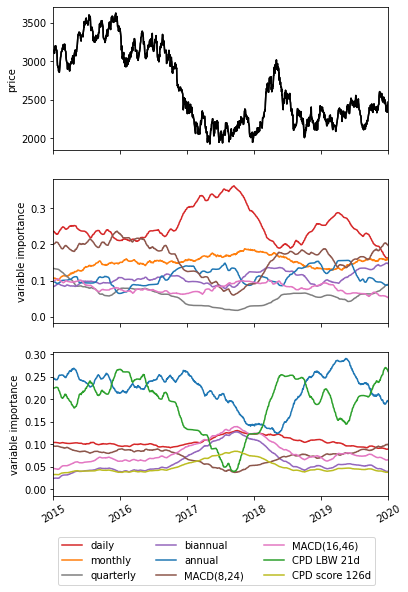
- Attention Mechanisms: The architecture incorporates self-attention layers that provide direct links to previous time-steps, enabling the learning of long-term dependencies and dynamic market changes (Figure 1).
- LSTM Integration: Combining attention with LSTM layers addresses the limitations of sequential LSTM architectures that struggle with global patterns due to their inherent tendency to forget prior information (Figure 2).
- Variable Selection Network: This component filters inputs, retaining only those most significant for prediction, thus enhancing model interpretability and efficiency.
- Changepoint Detection (CPD): Optional inclusion of a CPD module provides preprocessing features that signal structural shifts in the data over multiple timescales, further improving model response to regime changes.
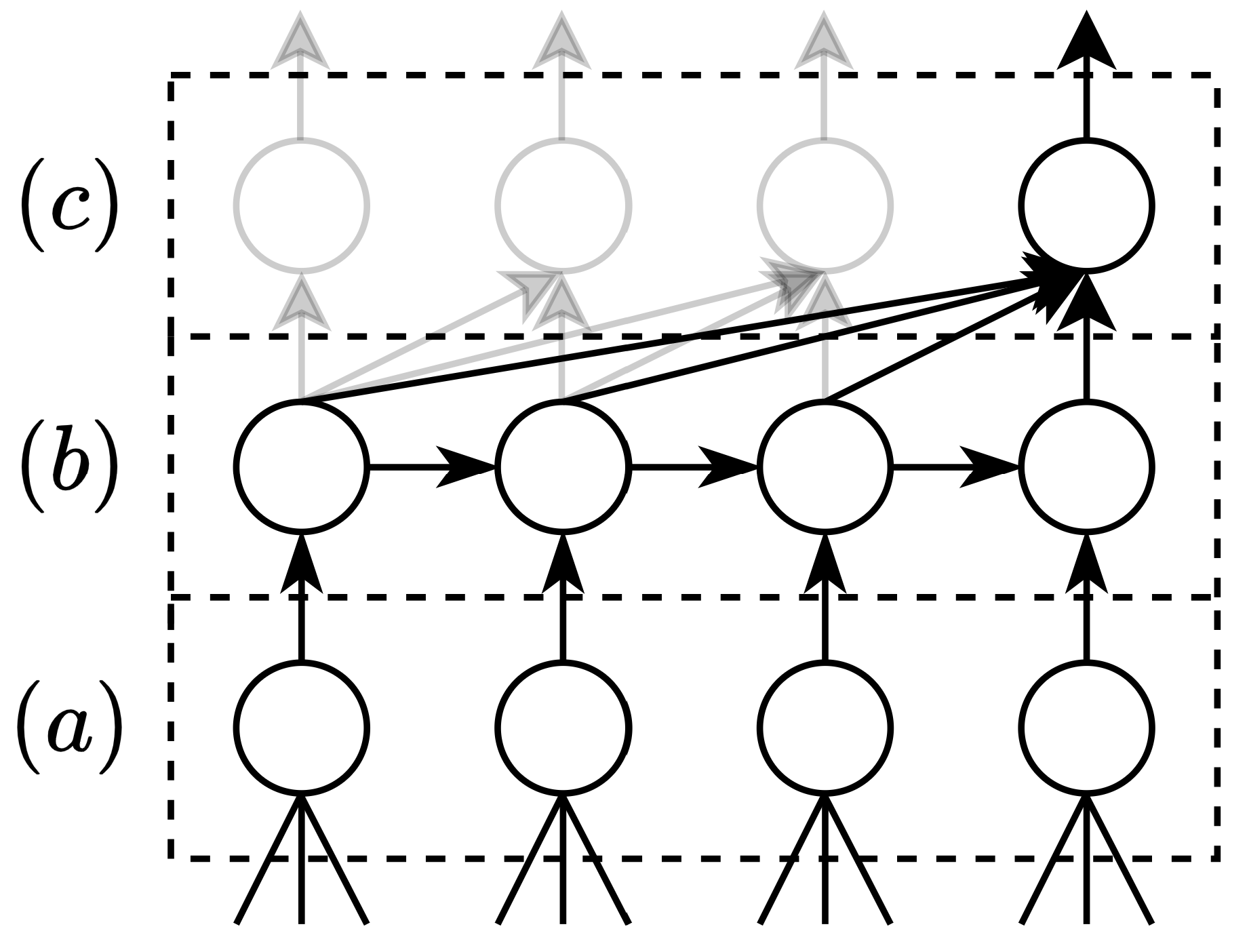
Figure 2: A (simplified) Momentum Transformer architecture, corresponding to g(⋅), pieces together (a) Variable Selection Network, (b) LSTM, and (c) self-attention mechanism.
Empirical Findings
The Momentum Transformer noticeably outperforms traditional LSTM architectures on several risk-adjusted performance metrics, particularly during periods exhibiting significant nonstationarity. Notable improvements include:
- Sharpe Ratio: Enhanced by over 100% during recent years characterized by heightened volatility (Figure 3).
- Robustness to Regime Shifts: Demonstrated resilience during the SARS-CoV-2 crisis through layered attention and changepoint identification, capturing both crashing and bull market dynamics effectively (Figure 4).
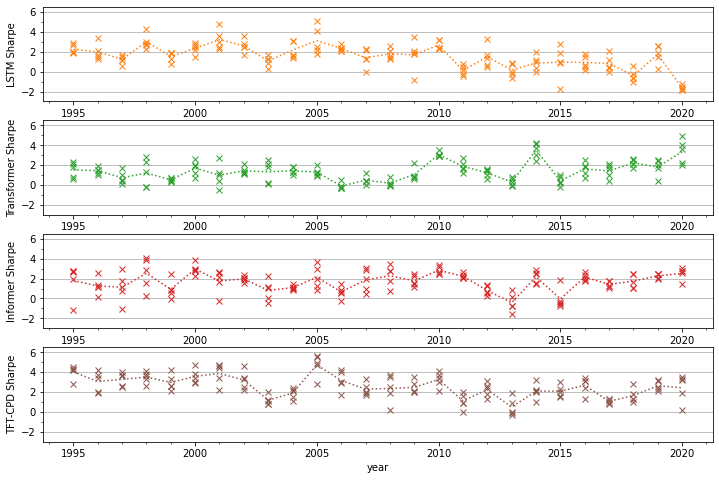
Figure 3: Average annual Sharpe ratio by year, including the results for each of the five experiment repeats.
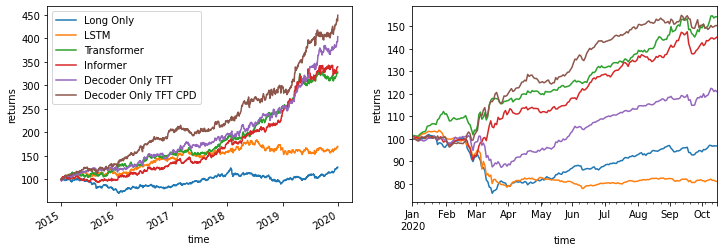
Figure 4: These plots benchmark our strategy performance for the 2015–2020 scenario (left) and the SARS-CoV-2 scenario (right). For each plot we start with \$100 and we re-scale returns to 15% volatility.
Interpretability
The architecture isn't merely adept at performance but also excels in interpretability:
Transaction Costs Considerations
While deep learning networks often struggle with profitability net of transaction costs, the Momentum Transformer mitigates this through emphasising long-term trend capturing, thus minimizing frequent trading and associated costs:
- Simulation Results: Indicates robust performance maintaining feasible Sharpe ratios even at higher transaction costs during challenging market conditions (Table 1).
Conclusion
The Momentum Transformer represents a substantial leap in applying deep learning to financial trading strategies, specifically momentum trading. Its architectural design adeptly balances localized short-term insights and broader long-term trends, demonstrating adaptability and robust performance even during tumultuous market periods.
Future research could extend this framework to encompass broader asset classes and factor-based strategies, potentially enhancing diversified portfolio management. Additionally, exploring ensemble learning as a practical adaptation could yield further performance improvements across varied trading environments.