- The paper introduces a DRL-driven strategy using DDQN to adjust the robot's camera viewpoint in real time for improved self-localization and ball visibility.
- The method formulates the task as a POMDP and employs prioritized experience replay in simulated Webots environments, yielding measurable improvements in success rate and response time.
- The approach outperforms traditional entropy-based techniques by maintaining reliable performance even with localization errors, enhancing both landmark detection and continuous ball tracking.
Real-time Active Vision for a Humanoid Soccer Robot Using Deep Reinforcement Learning
Introduction
This paper presents an active vision methodology tailored for a humanoid soccer-playing robot utilizing Deep Reinforcement Learning (DRL). The method optimizes the robot's viewpoint dynamically to enhance self-localization by capturing the most informative landmarks while simultaneously keeping the soccer ball visible within its field of view. Traditional entropy-based methods are highly reliant on localization accuracy, presenting challenges when errors occur. This research formulates the problem as an episodic reinforcement learning (RL) challenge, employing Deep Q-learning to govern the robot's viewpoint adjustments using raw camera images.
Methodology
Task Specifications
The task involves a humanoid robot with a constrained field of view on a RoboCup soccer field. The robot's camera is mounted on its head, and the objective is to optimize the camera's viewpoint to include the ball and significant landmarks for improved localization. The agent-environment interaction is modeled as a Partially Observable Markov Decision Process (POMDP) with elements such as observations from grayscale images, a state represented by sequences of observations, a discrete action space, and a reward function emphasizing optimal head positioning.
Goal Determination
The optimal camera viewpoint is established based on the robot and ball positions by discretizing the camera's pan and tilt angles. Each potential position is evaluated through an entropy-based method, with the goal being the viewpoint that minimizes belief entropy while ensuring ball visibility.
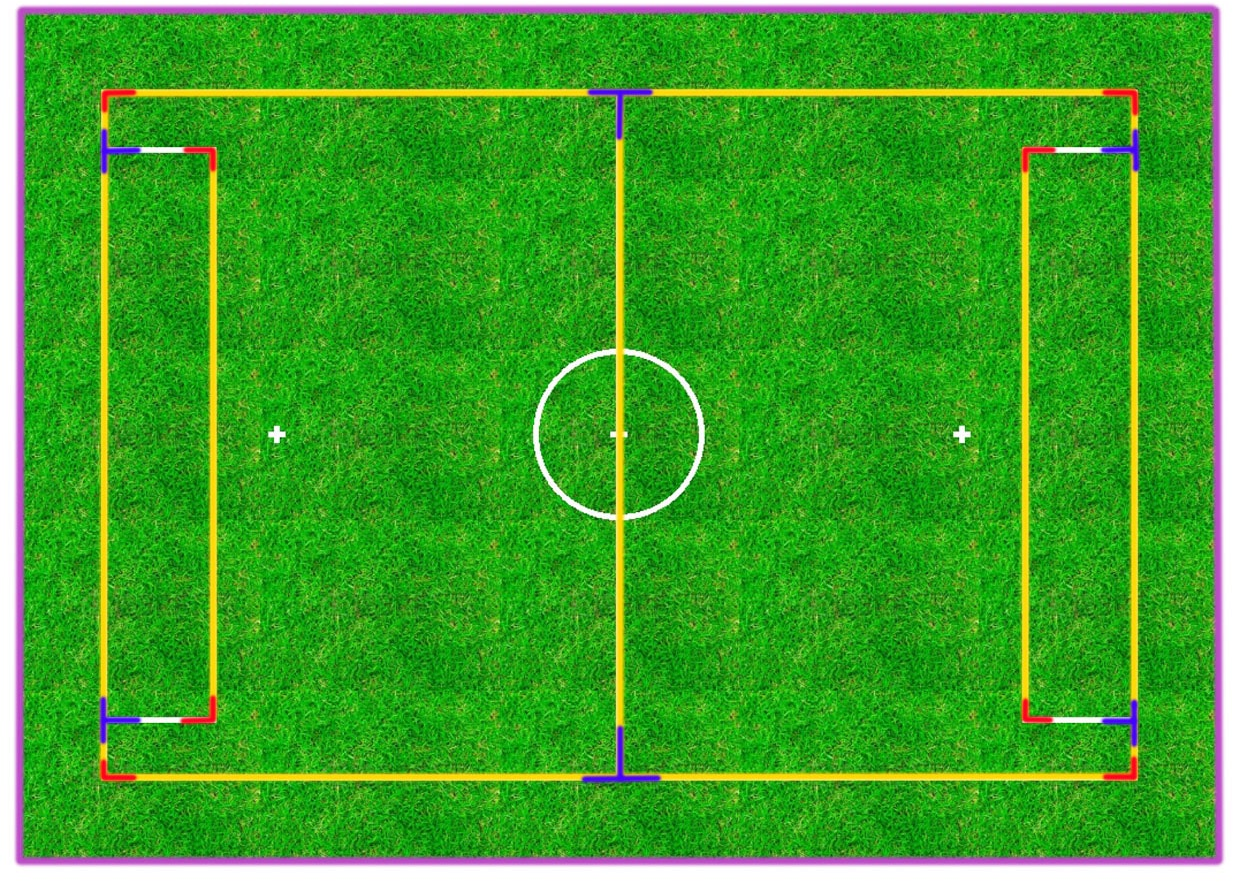
Figure 1: Different parts of the soccer field markings, colored and categorized by type.
Neural Network Architecture and Training
The training employs a Double Deep Q-Network (DDQN) model enhanced with Prioritized Experience Replay (PER). The network architecture consists of convolutional layers followed by fully connected networks, and ReLU is used as the activation function across layers except for the output (Figure 2).
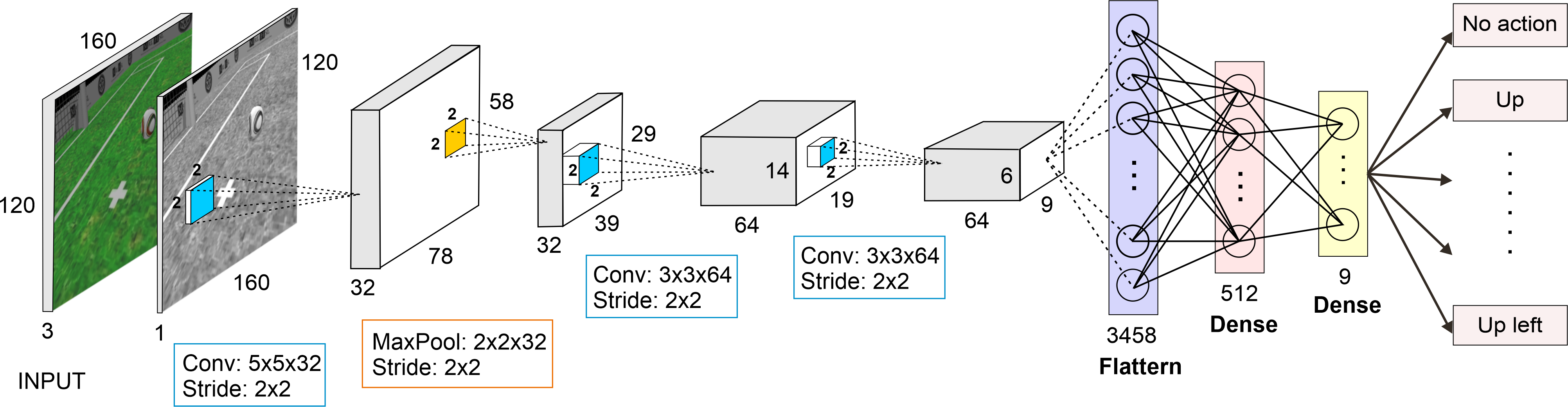
Figure 2: Neural network architecture deploys ReLU for all layers except the max-pooling and output layers.
The training environment is simulated in Webots, utilizing Tensorflow for implementation. The network's optimization leverages the Adam optimizer with a fixed learning rate. The model outputs Q-values corresponding to action efficacy derived from grayscale input images.
Experiments and Results
Training Environment
Simulations within the Webots platform enable evaluation under varied random initial conditions for the robot and ball positions. The agent learns to adjust the camera viewpoint over 20 time steps per episode, with success being reaching the optimal viewpoint or maintaining the ball in view.
Key performance metrics during training include success rate, success duration, and ball loss duration. The success rate quantifies the percentage of desired landmarks observed, while success duration measures the time taken to achieve the optimal viewpoint. Training demonstrated a continuous improvement in the model's efficacy to quickly and accurately adjust viewpoints for optimal visual coverage (Figure 3, Figure 4, Figure 5).





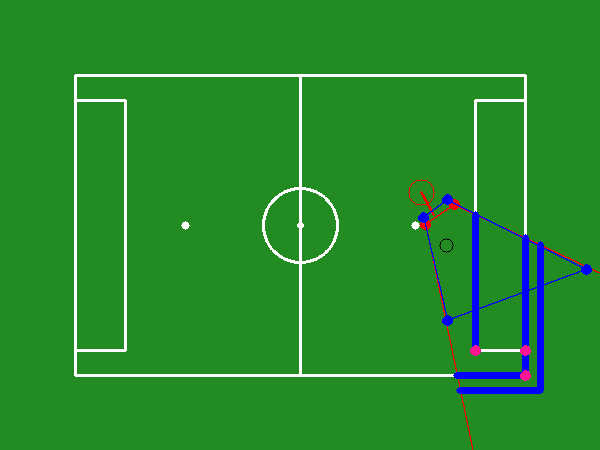
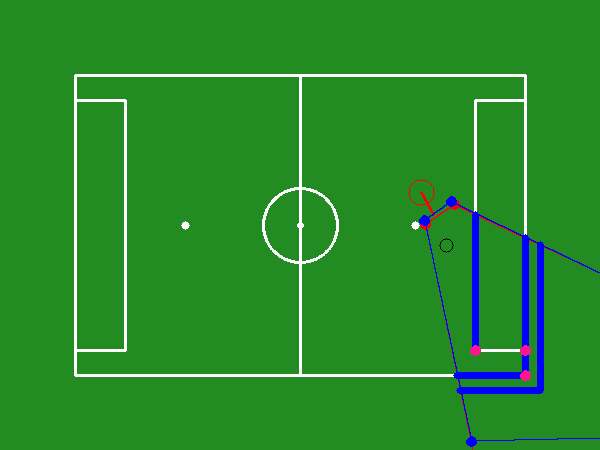
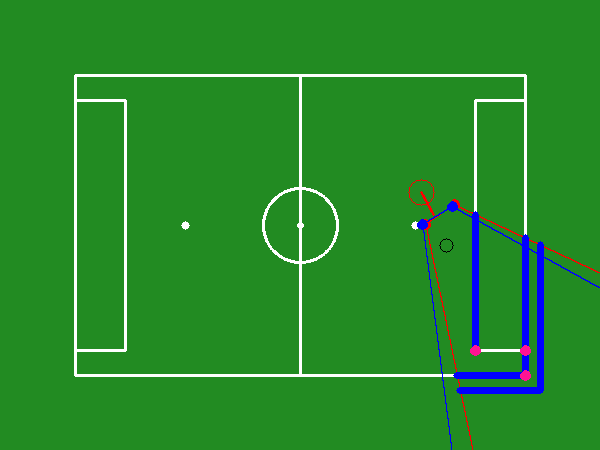




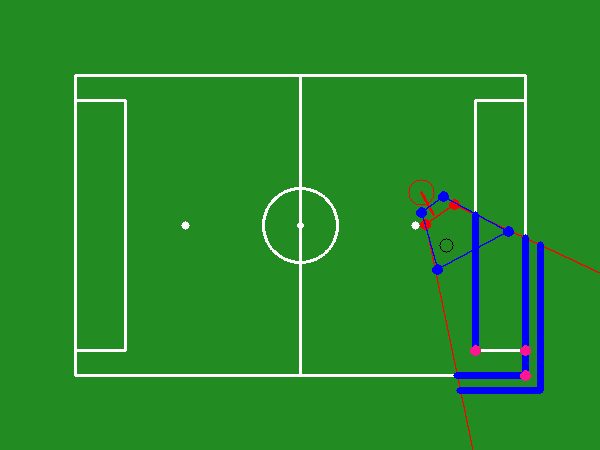
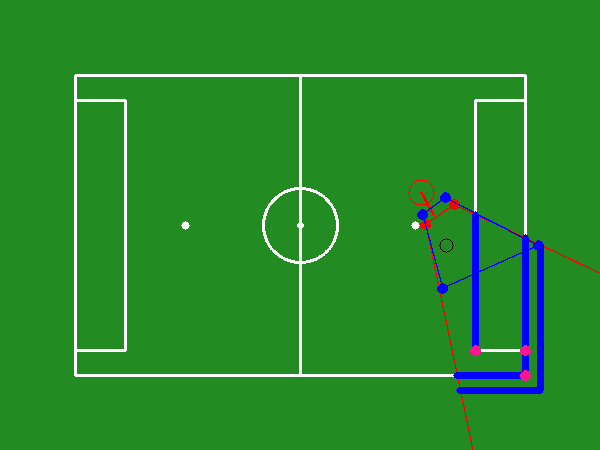
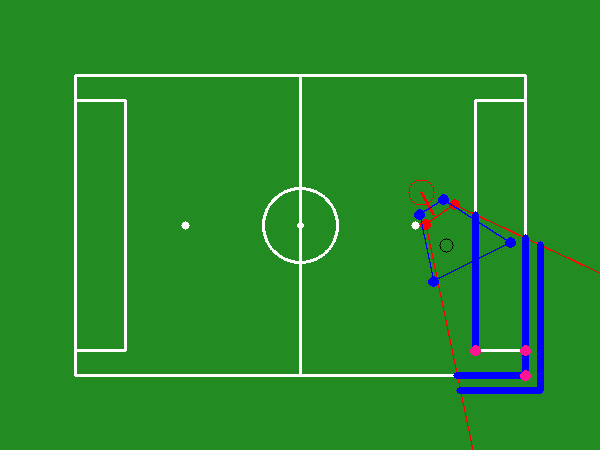
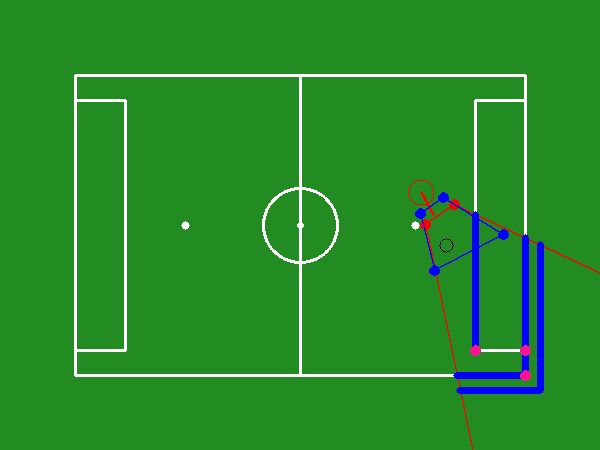
Figure 3: Total reward gained per episode during the training course.
Figure 4: Loss function of the model during the training course.
Comparison with Entropy-based Method
The proposed method significantly mitigates the impacts of self-localization errors seen in entropy-based solutions. Unlike these traditional methods, the DRL approach maintains consistent performance regardless of localization inaccuracies, operating solely based on current visual inputs (Figure 6).
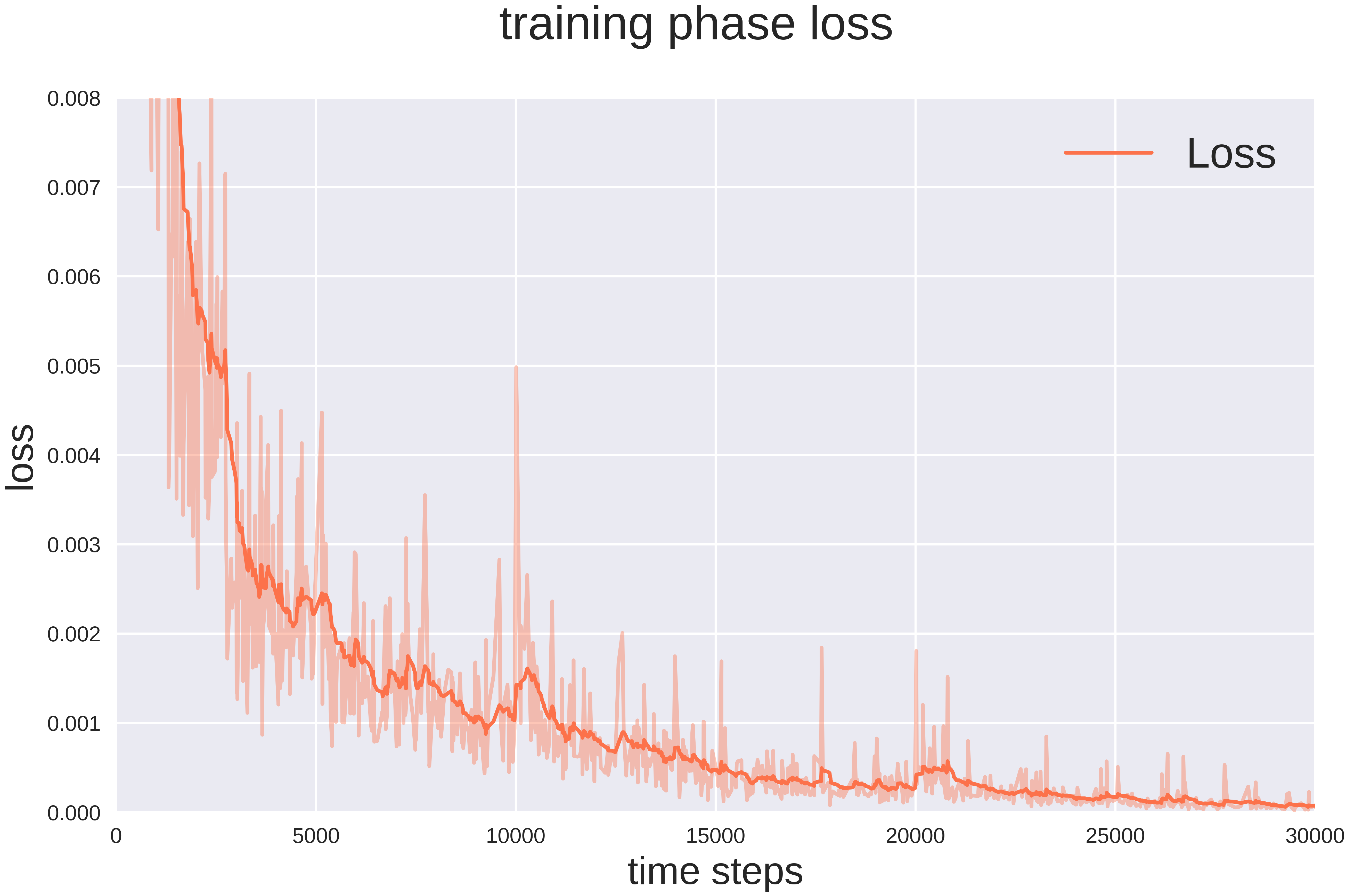
Figure 6: Comparison of the proposed method's success rate against entropy-based method amid increasing localization errors.
Conclusion
This paper outlines a method for real-time active vision adjustment in humanoid soccer robots using DRL. By formulating the task as a POMDP and employing DDQN, the approach overcomes limitations inherent in entropy-based solutions, particularly under conditions of localization error. Future work proposes extending the model to continuous action spaces and refining performance with additional environmental cues to address symmetrical visual inputs.
Future directions could explore integrating continuous action space algorithms and enhancing the model's robustness to symmetrical visual field ambiguities.

