Published 24 Oct 2020 in cs.LG and stat.ML | (2010.12986v1)
Abstract: Adam is a widely used optimization method for training deep learning models. It computes individual adaptive learning rates for different parameters. In this paper, we propose a generalization of Adam, called Adambs, that allows us to also adapt to different training examples based on their importance in the model's convergence. To achieve this, we maintain a distribution over all examples, selecting a mini-batch in each iteration by sampling according to this distribution, which we update using a multi-armed bandit algorithm. This ensures that examples that are more beneficial to the model training are sampled with higher probabilities. We theoretically show that Adambs improves the convergence rate of Adam---$O(\sqrt{\frac{\log n}{T} })$ instead of $O(\sqrt{\frac{n}{T}})$ in some cases. Experiments on various models and datasets demonstrate Adambs's fast convergence in practice.
The paper introduces an enhanced Adam optimizer that employs a multi-armed bandit mechanism to dynamically select the most informative training examples.
It demonstrates improved convergence rates, reducing theoretical complexity from O(√(n/T)) to O(√(log(n)/T)) compared to standard Adam.
Experimental results on benchmarks like MNIST, CIFAR, and IMDB validate faster convergence and increased model accuracy across varied architectures.
"Adam with Bandit Sampling for Deep Learning" (2010.12986)
Introduction
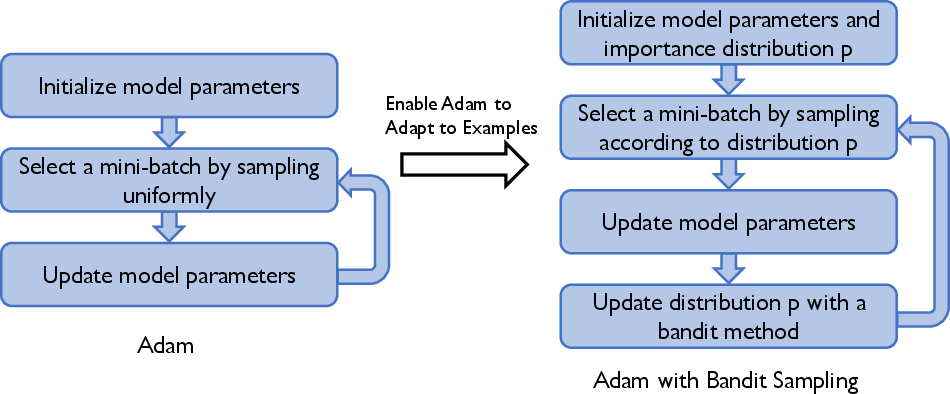
The paper proposes an augmentation to the Adam optimization algorithm, termed Adam with Bandit Sampling (ABS), for deep learning. This method adapts the gradient update process based on the varying importance of different training examples using a multi-armed bandit strategy, rather than uniformly sampling mini-batches. The methodology targets improving convergence rates theoretically relative to standard Adam, particularly when dealing with data heterogeneity.
Figure 1: Adam with Bandit Sampling generalizes Adam with adaptive example selection using a bandit strategy.
Methodology
Adaptive Mini-Batch Selection
The primary innovation of ABS is the incorporation of a distribution over training examples which influences mini-batch selection. This distribution evolves through a bandit-based update mechanism, specifically extending the EXP3 algorithm to select multiple mini-batch actions. The crucial aspect is estimating per-example importance dynamically using partial feedback from sampled mini-batches and adjusting the likelihood of their selection accordingly. This process is computationally designed to scale efficiently with the dataset size.
Convergence Analysis
ABS modifies the convergence rate from O(n/T) to O(log(n)/T) under certain assumptions, determined by sampling based on example significance, which inherently shifts the optimization focus towards influential data points over iterations. The bandit mechanism is theoretically shown to minimize regret compared to an optimal static distribution, thus ensuring sample efficiency.
Experimental Design
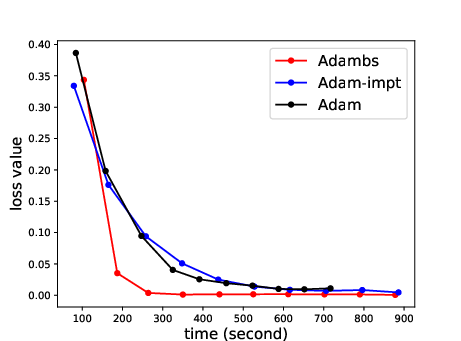
The empirical evaluation includes training on standard benchmarks like MNIST, CIFAR-10, CIFAR-100, and IMDB with architectures such as MLPs, CNNs, and recurrent networks. ABS demonstrates substantial improvements in convergence speeds and model accuracy compared to not only Adam but also other variations like Adam with uninformative sampling, proving its efficacy across datasets and models.
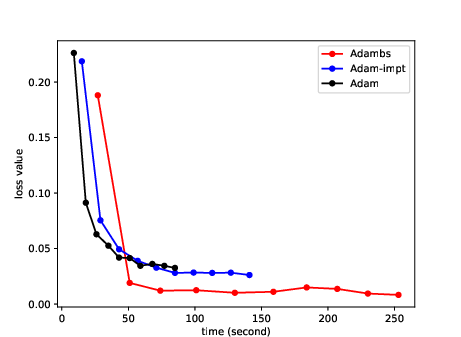
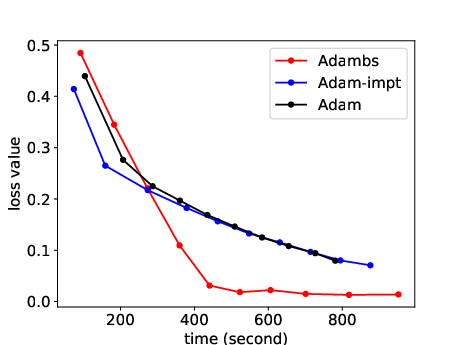
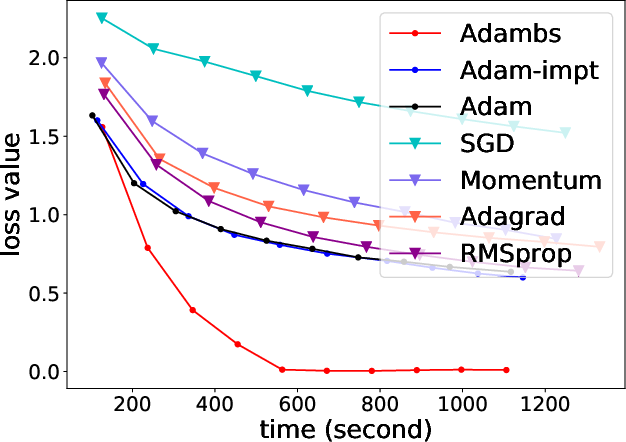
Figure 2: MLP model performance on MNIST underlines ABS's efficiency in decreased training loss.
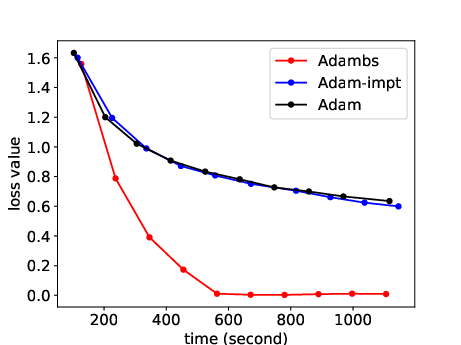
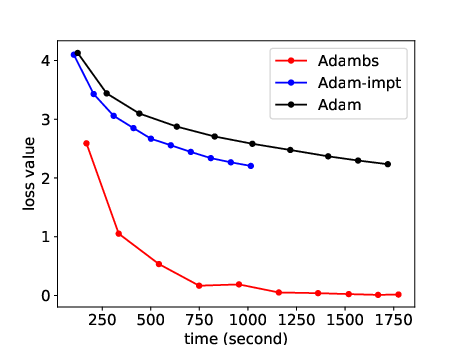
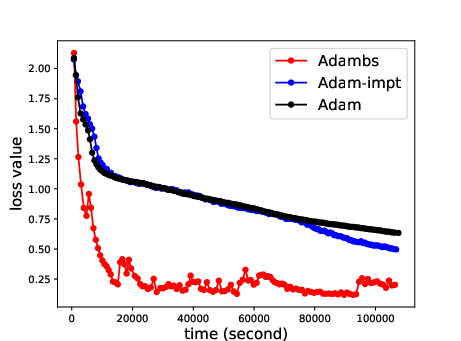
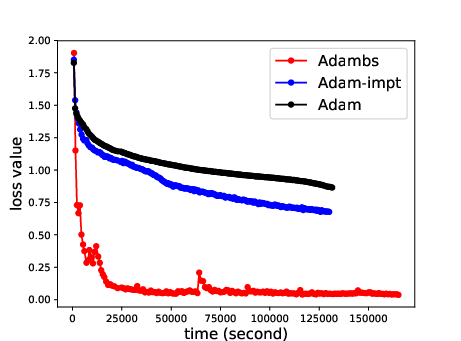
The paper extensivelly contrasts ABS against standard SGD and adaptive variants, emphasizing the exceptional gains in convergence velocity. Supplementary experiments reveal how ABS's loss curves significantly undercut those of its counterparts (e.g., Adam, RMSprop), indicating a pattern of rapid stabilization at lower loss values attributed to its dynamic sampling methodology.
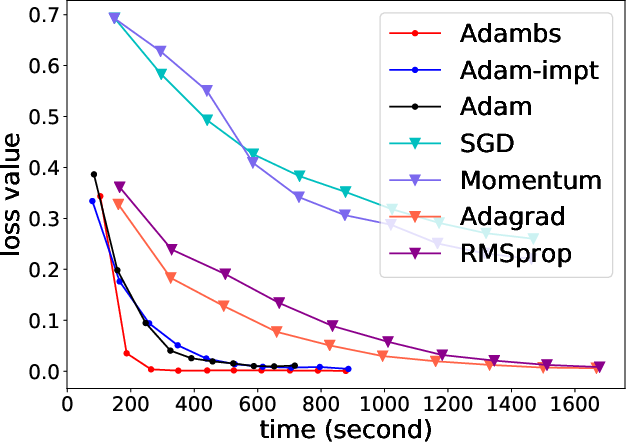
Figure 4: RNN model assessments on MNIST evidence ABS's robust application to varied data paradigms.
Figure 5: Comparative analysis between ABS and SGD variants suggest considerable efficiency in time-constrained training scenarios.
Implications and Future Work
ABS notably advances the optimization landscape by leveraging the adaptive variability in data point significance effectively. The multi-armed bandit approach embedded within the optimization reveals broad potential both theoretically and experimentally. Future work could investigate diversified strategies within deep network architectures or integrate advanced bandit models for enhanced sampling precision and task-specific tuning.
Conclusion
The introduction of Adam with Bandit Sampling redefines adaptability in stochastic gradient optimization by concentrating updates on impactful data slices. The empirical and theoretical findings together establish it as a credible alternative to traditional methods, especially in datasets exhibiting intrinsic imbalances. By leveraging computational learning techniques like multi-armed bandit approaches, ABS opens avenues for refined optimization frameworks in machine learning's progressive fabric.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.