- The paper demonstrates GymFG’s integration of FlightGear and JSBSim with the OpenAI Gym API to support advanced RL/IL experiments.
- It introduces a team-based, modular simulation architecture that enables controlled multi-agent interactions and comprehensive state synchronization.
- Empirical results validate robust controller performance, highlighting GymFG’s potential as a reliable framework for aerial autonomy research.
GymFG: An Open-Source Gym Interface for High-Fidelity Autonomous Aerial Agents
Motivation and Context
Development and evaluation of autonomous flight systems face significant hurdles due to a lack of open-source frameworks that support high-fidelity simulation, robust RL/IL experimentation, and seamless optimization workflow integration. Existing deployed systems in aviation predominantly rely on simple autopilot schemes and do not exhibit the levels of sophistication required for full autonomy, largely due to concerns around reliability and trust. Bridging this gap, GymFG presents an integrated platform that couples FlightGear, a high-fidelity open-source flight simulator, with the popular OpenAI Gym API, leveraging JSBSim as the core flight dynamics model. This design enables efficient, repeatable, and reproducible experimentation with advanced learning-based control strategies within realistic aerial environments.
System Architecture and Interface Design
GymFG introduces a team-based architecture for simulation management, where aircraft are grouped into teams, each participating in either cooperative or adversarial tasks within a shared environment. This organizational structure mirrors operational practices, facilitating scenarios with complex interactions and emergent behaviors. Each team, identified by a unique name, contains dynamically configurable rosters of aircraft assigned with individual tasks, supporting both single- and multi-agent paradigms.
Aircraft within GymFG operate under partial observability. State information about opponents is explicitly restricted to physical observables—position and orientation—better reflecting real-world sensing limitations. The environment class defines both the workload distribution (offline, online-k-fixed, and online-open) and visualization options, supporting scalability for large-scale, non-visualized training and fine-grained, visualized analysis.
Centralized state synchronization is accomplished via a state server, which aggregates aircraft state data at each simulation step and disseminates processed opposing team information according to the defined observability constraints. This centralization minimizes connection complexity in distributed experiments while enabling controlled information sharing.
Extensibility, Reward Specification, and Controller Design
A critical attribute of GymFG is its modular approach to state, action, and reward definition. Tasks encapsulate agent observation extraction, bespoke reward computation, and custom termination logic. This encapsulation enables rapid prototyping of new RL and IL evaluation scenarios. Rewards can be specified as temporally dependent functions with access to previous and current states/actions, aligning with typical RL methodologies but still allowing for time-sensitive and trajectory-based adaptations.
The Pythonic interface for team and task specification reflects modern software practices, lowering barriers for rapid environment reconfiguration. Example team and reward configuration scripts demonstrate the flexibility to represent arbitrary aircraft relationships and nontrivial dependencies in reward computation.
GymFG ships with a library of physics-based controllers for canonical flight tasks—altitude hold, roll angle targeting, and individual surface (aileron, elevator, rudder, throttle) regulation. These controllers provide baselines for evaluating learned policies and facilitate IL data collection.
Empirical Demonstration and Visualization
The efficacy of GymFG’s interfaces and primitives is established by evaluating two reference controllers: one for achieving target altitudes and one for achieving target roll angles. Each controller is benchmarked over several episodes with randomized or fixed targets.
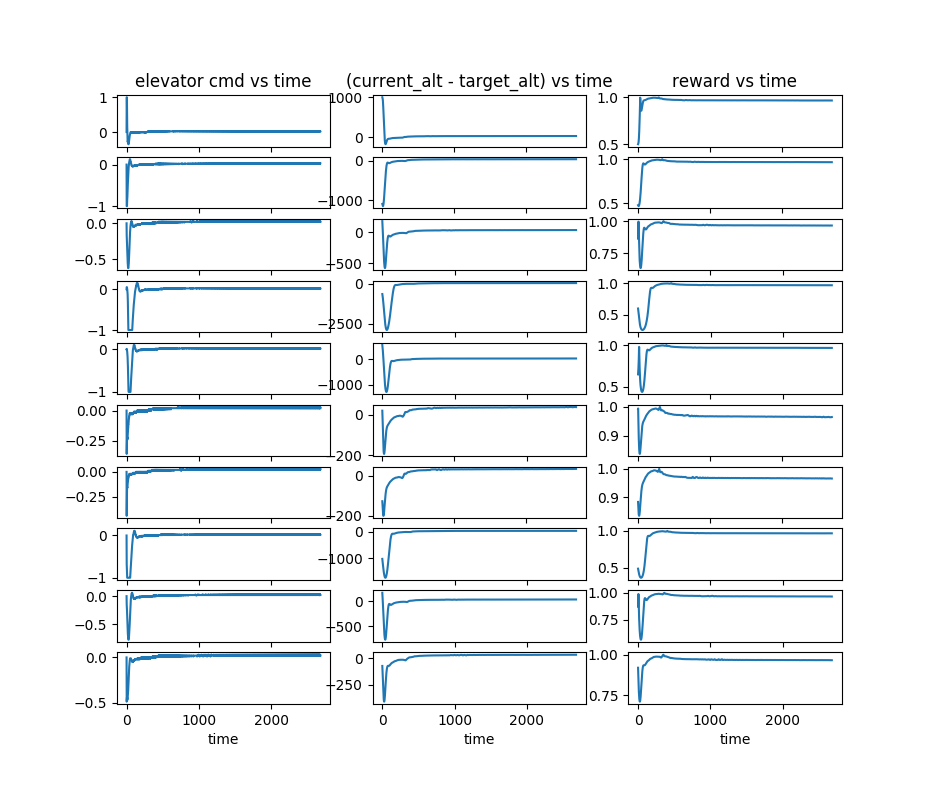
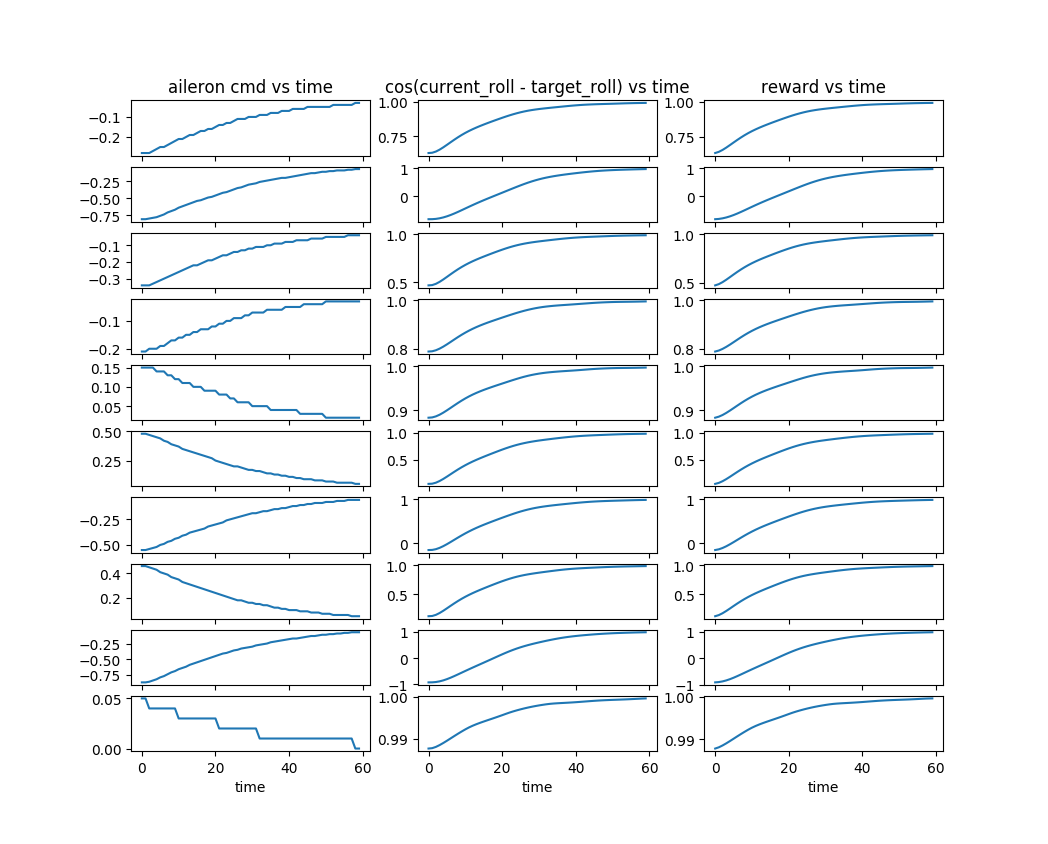
Figure 1: Trajectories of a physics-based elevator controller achieving target altitude (left) and a roll controller reaching target roll angle (right), with distinct control, target, and reward signal plots per episode.
The experimental results show that the controllers robustly achieve their underlying tasks, as reflected in stable convergence of controlled variables to their targets and corresponding positive reward trends. The platform's trajectory recording and visualization utilities further facilitate both post-hoc performance analysis and detailed agent diagnostics.
Feature Set and Usability
GymFG supports manual operation (keyboard and joystick, with future mouse support), essential for IL dataset generation when automating complex, hard-to-script maneuvers. The platform can record full state-action-reward trajectories, providing artifacts necessary for offline imitation and behavior cloning. Integrated visualization tools enable real-time introspection of control inputs and state evolution at each simulation step.
The Gym interface is preserved with minimal modifications; the main distinction lies in per-reset team configuration management—optimizing for multi-agent and multi-team workflow compatibility.
Future Directions
Proposed expansions for GymFG include:
- Online multiplayer via FlightGear’s native infrastructure: This would facilitate agent interaction with human pilots, dramatically increasing scenario realism and complexity.
- Direct video capture for state representation: Enables research in vision-based control and perception-driven RL, aligning with trends in end-to-end policy learning.
- Reward functions leveraging arbitrary-length past state/action histories: Essential for non-Markovian environments and tasks with delayed or sparse rewards.
- Scalability in aircraft models and scenario initialization: Including the full suite of JSBSim/FlightGear aircraft and support for joint initial conditions would unlock more realistic coordinated behaviors, such as formation flight.
- Support for dynamic team membership during simulation: Would broaden applicability to fault-tolerant and adversarial multi-agent learning contexts.
These advancements aim to position GymFG as the de-facto open-source standard for high-fidelity aerial autonomy research.
Conclusion
GymFG constitutes a significant advance for reproducible, high-fidelity RL/IL research in the aerial autonomy domain. By integrating FlightGear and JSBSim within the OpenAI Gym ecosystem and emphasizing flexible team/task specification, robust state synchronization, and comprehensive visualization/recording, GymFG addresses critical gaps in the research infrastructure landscape. The framework enables rigorous benchmarking of learning-based flight controllers and paves the way for future work at the intersection of control, perception, and human-AI interaction in aviation autonomy.