- The paper presents a hybrid deep learning framework integrating DNN and GBT to achieve over 92% AUC and better misclassification rates in predicting consumer default.
- The paper employs extensive feature engineering and SHAP analysis to demonstrate the significance of trade counts and debt balances over traditional credit metrics.
- The paper demonstrates economic value through improved risk classification, cost savings for lenders, and enhanced credit scoring for borrowers previously unscorable.
Introduction
This paper presents a comprehensive deep learning framework for predicting consumer default, leveraging anonymized credit bureau data and comparing its efficacy against conventional credit scoring models. The authors develop a hybrid model combining deep neural networks (DNN) and gradient boosted trees (GBT), demonstrating superior predictive accuracy, interpretability, and coverage. The analysis is grounded in a large, nationally representative panel spanning over a decade, enabling robust out-of-sample validation and temporal analysis of systemic risk.
The dataset comprises quarterly Experian credit files from 2004Q1 to 2015Q4, with over 200 features for 1 million households. Features include detailed credit product balances, delinquencies, inquiries, public records, and credit scores. The target variable is a binary indicator of 90+ days delinquency within the subsequent 8 quarters, aligning with industry standards for default risk.
The prediction task is formalized as a supervised classification problem, where the model estimates the conditional probability of default given the feature vector Xt−1i for individual i at time t−1.
Model Architecture
The hybrid model integrates two components:
- Deep Neural Network (DNN): A feed-forward architecture with up to 15 hidden layers, optimized via Tree-structured Parzen Estimator (TPE). RELU activations and dropout regularization are employed to mitigate overfitting and capture complex nonlinear interactions among features.
- Gradient Boosted Trees (GBT): Implemented via XGBoost, this ensemble method addresses high variance and instability inherent in single decision trees, leveraging shrinkage and recursive residual fitting.
The final prediction is the arithmetic mean of the DNN and GBT outputs, selected after empirical comparison with alternative ensemble strategies.
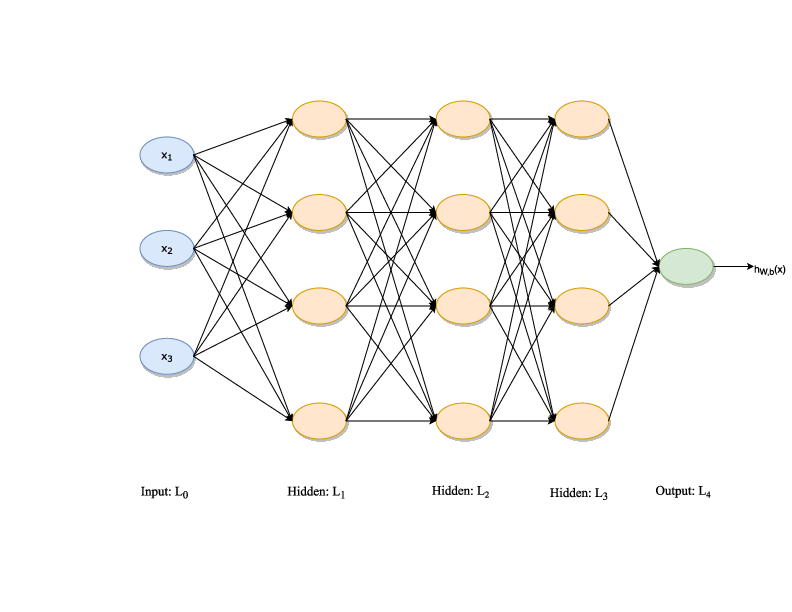
Figure 1: Two Layer Neural Network Example. Illustrates the architecture and parameterization of a feed-forward neural network used in the hybrid model.
Feature Engineering and Implementation
Feature selection is guided by economic theory and regulatory constraints, excluding age, location, and income to comply with the Fair Credit Reporting Act and Equal Opportunity in Credit Access Act. Temporal features are preferred over lagged variables, enabling scoring for all borrowers with non-empty credit records.
Data normalization, train-test splits (with 8-quarter separation to avoid look-ahead bias), and GPU-accelerated training are employed for scalability. Hyperparameters are tuned via cross-validation, and regularization is achieved through dropout, early stopping, and batch normalization.
Empirical Results
Nonlinear and Multidimensional Feature Relationships
The relationship between default and covariates is highly nonlinear and exhibits high-order interactions, motivating the use of deep learning.
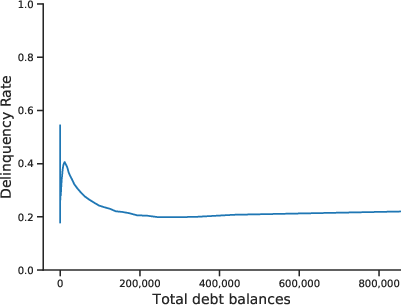
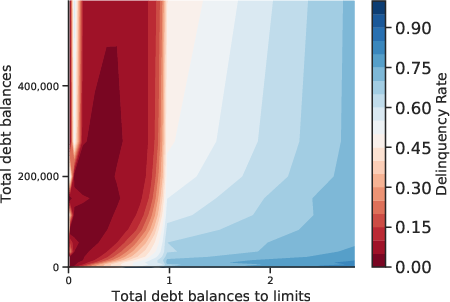
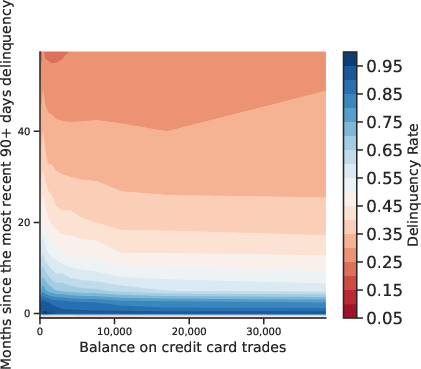
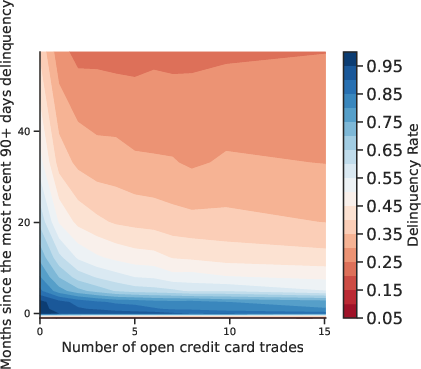
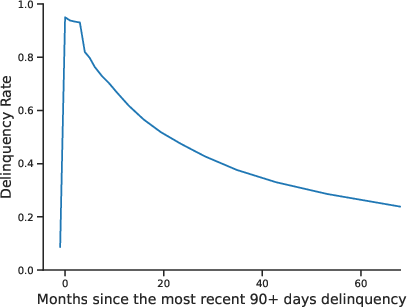
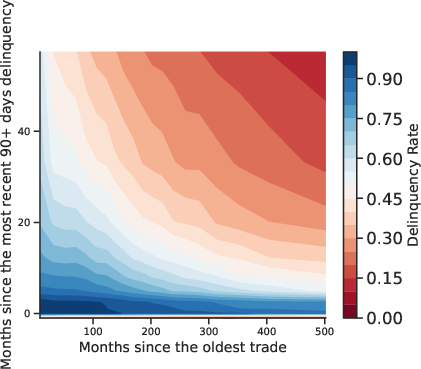
Figure 2: Nonlinear Relation Between Default and Covariates. Demonstrates the complex, non-monotonic dependence of default rates on key financial features.
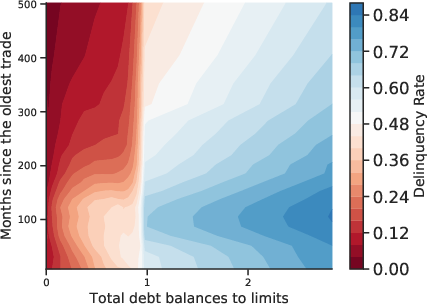
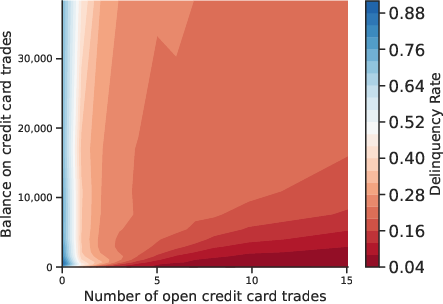
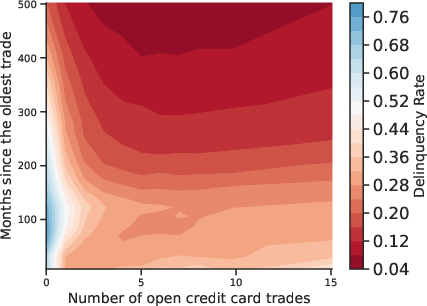
Figure 3: Multidimensional Relation Between Default and Covariates. Contour plots reveal joint effects of feature pairs on default incidence.
Out-of-sample accuracy consistently exceeds 86%, with AUC scores above 92%. The hybrid model outperforms logistic regression, random forests, and standalone DNN/GBT models across all temporal splits.
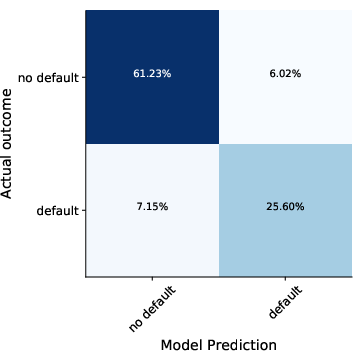
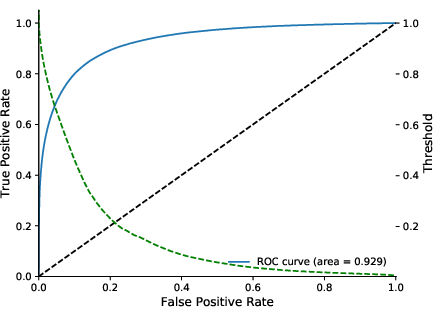
Figure 4: Confusion matrix and ROC curve for out-of-sample forecasts of 90+ days delinquencies over the 8Q horizon, calibrated on 2011Q4 and tested on 2013Q4.
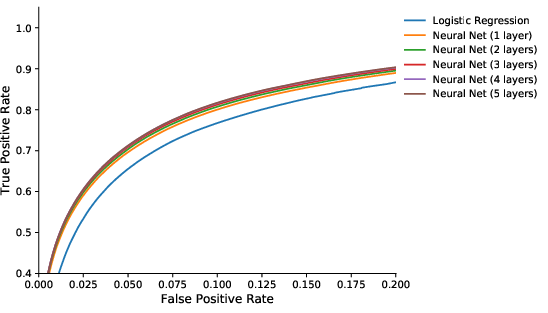
Figure 5: Out-of-sample ROC curves for various models with dropout, highlighting the dominance of deep architectures over shallow baselines.
Model Interpretation
Feature importance is assessed via permutation analysis and SHAP values. The most influential predictors are the number of trades, balances on outstanding loans, recent delinquencies, and length of credit history. Notably, debt balances and trade counts are more salient than utilization rates, contradicting conventional credit scoring heuristics.
Temporal Dynamics
SHAP analysis across pre-crisis, crisis, and post-crisis periods reveals stability in the importance of debt balances and trade counts, with some temporal variation in delinquency-related features.
Comparison with Credit Scores
The hybrid model achieves near-perfect rank correlation (0.999) with realized default rates, compared to 0.98–0.99 for credit scores. The Gini coefficient for the model is stable at ~0.86, while the credit score's Gini drops during the Great Recession. Misclassification rates for risky borrowers are substantially lower with the hybrid model.
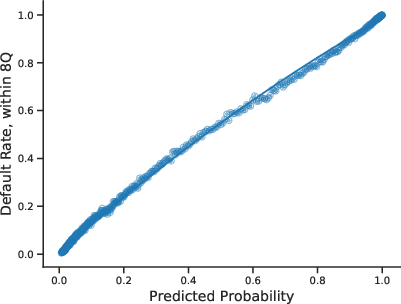
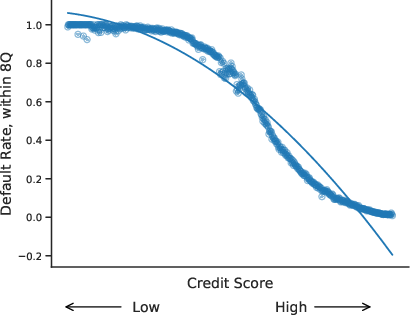
Figure 6: Scatter plot of realized default rates against model predicted default probability and credit score for 2008, with polynomial fits.
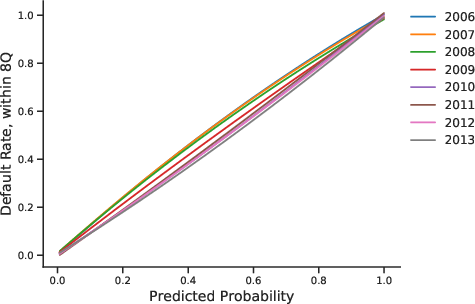
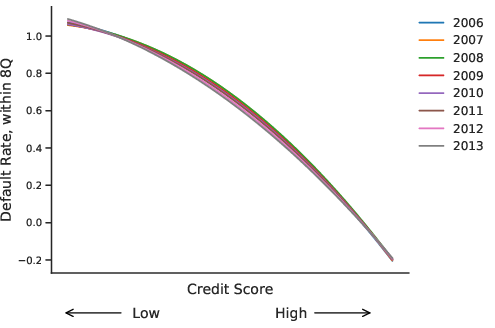
Figure 7: Polynomial approximation of realized default rates vs. model predictions and credit score for selected years.
Coverage and Systemic Risk
The model provides default probabilities for all borrowers with non-empty credit records, including those unscorable by traditional models (~8% of borrowers). Aggregated predictions closely track realized systemic default rates, capturing macroeconomic shocks and recovery dynamics.
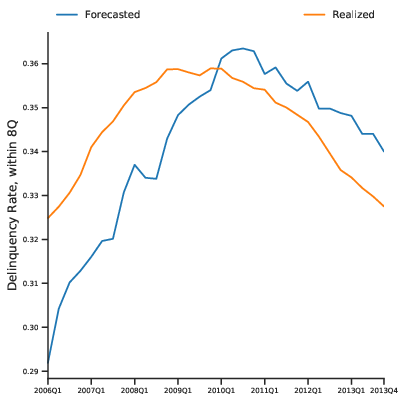
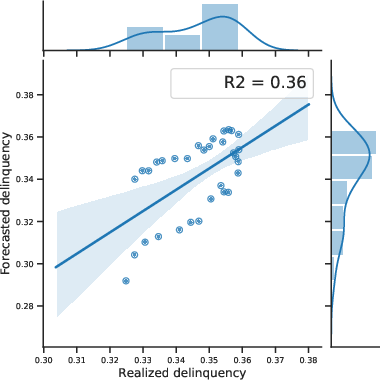
Figure 8: Fraction of consumers with 90+ days delinquency within the subsequent 8 quarters, predicted and realized, demonstrating aggregate tracking.
Figure 9: Aggregate 90+ days delinquency rates within 8Q, relation with predicted.
Economic Value Added
For lenders, the hybrid model yields cost savings of 1–9% over logistic regression and up to 75% over no forecast, depending on interest rates and run-up assumptions. For borrowers, reclassification into lower risk categories results in annual interest savings up to \$1,465, particularly for Subprime and Near Prime segments.
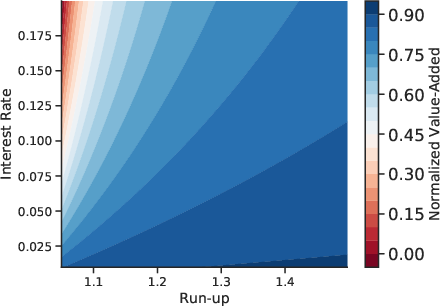
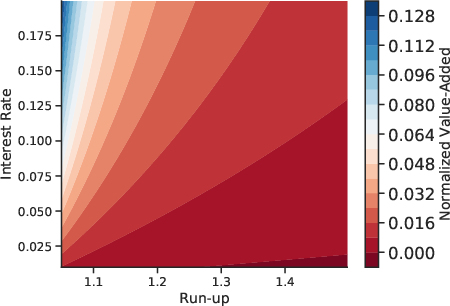
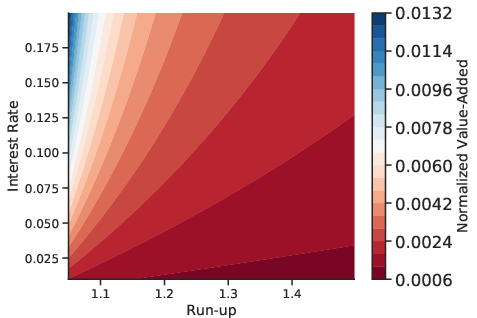
Figure 10: Value-added of machine-learning forecasts of 90+ days delinquency over 8Q forecast horizons, quantifying lender and borrower gains.
Theoretical and Practical Implications
The findings challenge the primacy of utilization rates in default prediction, emphasizing the role of trade counts and balances. The model's interpretability supports regulatory compliance and individualized risk disclosure. Its ability to score previously unscorable borrowers enhances financial inclusion. At the macro level, accurate systemic risk estimation informs macroprudential policy and stress testing.
Future Directions
Potential extensions include incorporating alternative data sources (subject to regulatory constraints), exploring causal inference for policy design, and adapting the framework to other credit products (e.g., mortgages, auto loans). Further research may investigate dynamic retraining strategies to adapt to evolving economic conditions and borrower behavior.
Conclusion
The hybrid deep learning approach substantially improves consumer default prediction over conventional credit scoring, both at the individual and systemic levels. Its interpretability, coverage, and economic value make it a compelling candidate for industry adoption and policy analysis. The empirical evidence supports a paradigm shift in credit risk modeling, with implications for financial stability, consumer welfare, and regulatory practice.