EvoFSM: Controllable Self-Evolution for Deep Research with Finite State Machines
Abstract: While LLM-based agents have shown promise for deep research, most existing approaches rely on fixed workflows that struggle to adapt to real-world, open-ended queries. Recent work therefore explores self-evolution by allowing agents to rewrite their own code or prompts to improve problem-solving ability, but unconstrained optimization often triggers instability, hallucinations, and instruction drift. We propose EvoFSM, a structured self-evolving framework that achieves both adaptability and control by evolving an explicit Finite State Machine (FSM) instead of relying on free-form rewriting. EvoFSM decouples the optimization space into macroscopic Flow (state-transition logic) and microscopic Skill (state-specific behaviors), enabling targeted improvements under clear behavioral boundaries. Guided by a critic mechanism, EvoFSM refines the FSM through a small set of constrained operations, and further incorporates a self-evolving memory that distills successful trajectories as reusable priors and failure patterns as constraints for future queries. Extensive evaluations on five multi-hop QA benchmarks demonstrate the effectiveness of EvoFSM. In particular, EvoFSM reaches 58.0% accuracy on the DeepSearch benchmark. Additional results on interactive decision-making tasks further validate its generalization.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
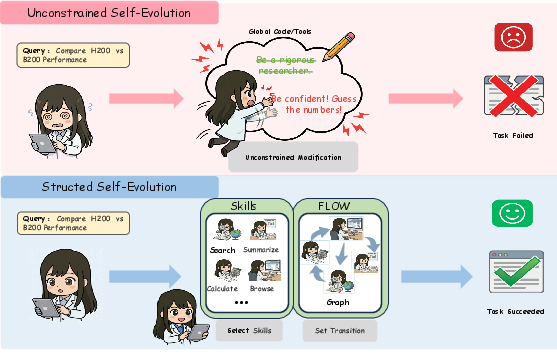
This paper introduces EvoFSM, a new way to help AI “research assistants” work better on complex questions. These assistants use LLMs to read, search, and reason, but they often follow rigid, fixed plans or try to rewrite themselves in messy ways that can break things. EvoFSM gives them a clear, structured plan they can safely improve over time, so they become smarter without becoming unstable.
Objectives and Questions
The paper tries to solve three simple problems:
- How can AI research assistants adapt their strategy to tricky, open-ended questions?
- How can they improve themselves without causing chaos, like drifting away from the task or hallucinating facts?
- How can they reuse what worked before and avoid past mistakes on future tasks?
How It Works (Methods)
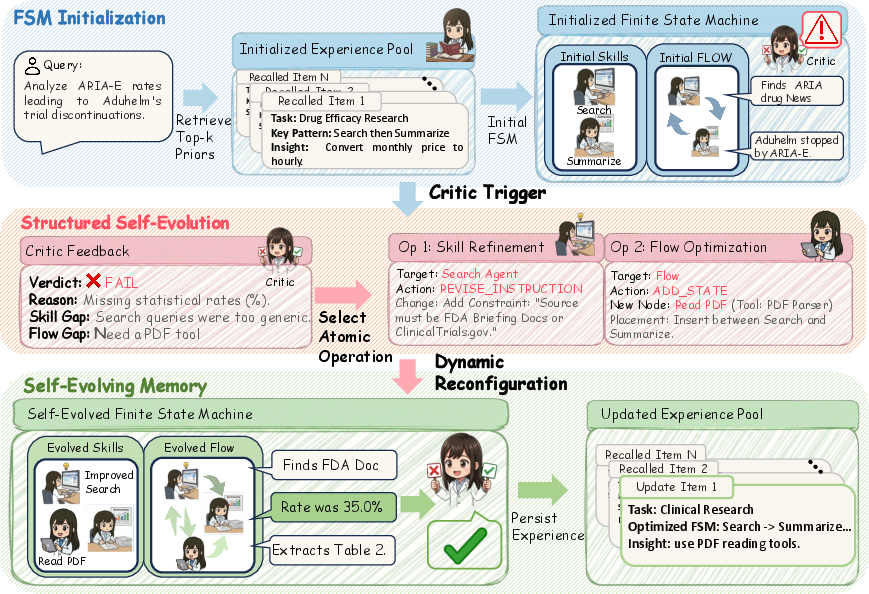
Think of EvoFSM like a flowchart for solving problems, with boxes and arrows. In computer science, this is called a Finite State Machine (FSM). Each “box” is a step (a state) like “Search,” “Read,” or “Analyze,” and each arrow says when to move to the next step.
EvoFSM separates two big ideas:
- Flow: the overall plan—what steps to take and in what order.
- Skill: how each step is done—specific instructions for the “Search” step, the “Read” step, and so on.
When the AI works on a question, a “critic” (like a coach or referee) checks the answer. If it’s wrong or weak, the critic points out the problem, and EvoFSM makes small, controlled fixes. Instead of rewriting everything, it uses a careful set of tiny changes:
- Flow tweaks:
- ADD_STATE: insert a new step, like a “Verify” step to double-check sources.
- DELETE_STATE: remove an unhelpful step.
- MODIFY_TRANSITION: adjust when to move between steps (for example, go back to “Search” if evidence is thin).
- Skill tweak:
- REVISE_INSTRUCTION: improve the instructions for a specific step (like telling “Read” to prefer official PDFs over random blogs).
EvoFSM also keeps a memory, like a playbook. It saves:
- What worked well (successful strategies) so future tasks can start with a good plan.
- What failed (bad patterns) so the AI avoids those mistakes next time.
What They Found (Results)
The authors tested EvoFSM on five tough “multi-hop” question-answering benchmarks (these are questions that require gathering linked facts from several sources). EvoFSM consistently beat other strong methods, including “Agentic RAG” and “Search-o1,” across different LLMs (like GPT-4o and Claude-4).
Highlights:
- On the DeepSearch benchmark—a very challenging test—EvoFSM reached 58% accuracy with Claude-4, clearly higher than the baselines.
- The performance gains held across multiple models, showing the approach isn’t tied to one specific AI.
- An ablation study (turning off parts to see their impact) showed both the structure (the FSM) and the controlled evolution are crucial. For example, removing the structured evolution led to a big drop (about 15% lower accuracy on DeepSearch). Removing the FSM structure also hurt performance.
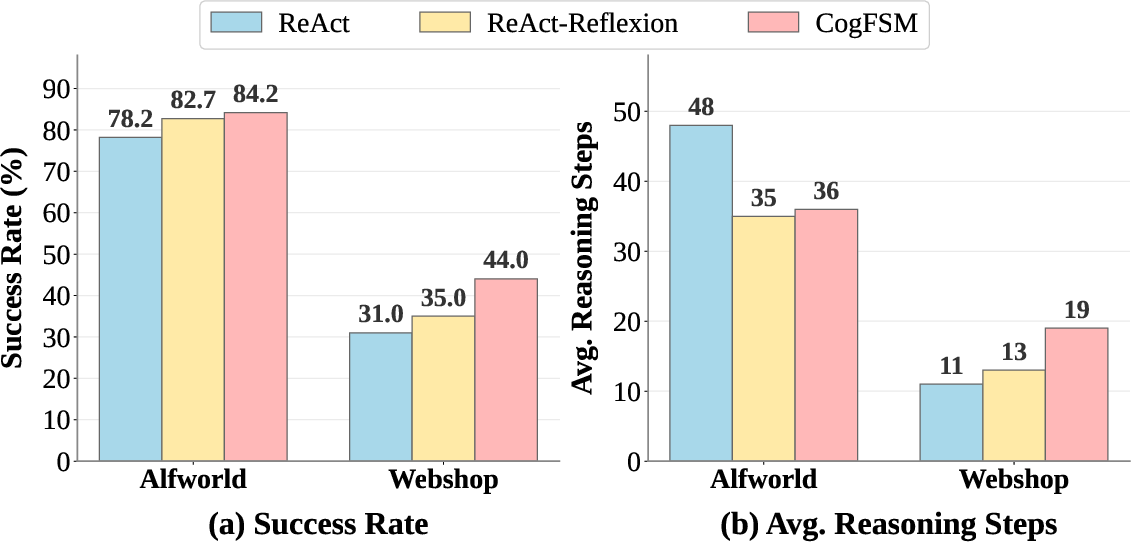
They also tried EvoFSM on interactive tasks like ALFWorld (text-based household tasks) and WebShop (online shopping with many products). EvoFSM not only solved more tasks but did so more reliably, even if it sometimes took a few extra steps to double-check its work.
Why It Matters (Implications)
EvoFSM shows a way for AI assistants to get better on their own—carefully and safely. Instead of blindly rewriting their entire strategy (which can lead to errors and weird behavior), they make small, meaningful changes inside a clear structure. That makes them:
- More reliable: fewer hallucinations and less “getting lost.”
- More adaptable: they can adjust plans for each new problem.
- More experienced: they remember what worked before and reuse it.
In the future, this could lead to AI tools that help scientists, journalists, and students do deeper, more trustworthy research. The paper also points out limits to fix next, like making the critic more robust, compressing the growing memory, and training smaller specialized models so the system runs faster and cheaper.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that future researchers could address to strengthen, validate, and extend EvoFSM.
- Formalization and learning of the transition function (): Specify how transition conditions are represented (symbolic rules vs. LLM-generated predicates), learned, and updated; investigate training methods (supervised, RL, or program synthesis) to reliably derive and refine from data.
- Critic mechanism reliability: Quantify critic false positives/negatives, calibrate confidence, and benchmark against programmatic/verifier-based checks (e.g., citation validation, numerical consistency, factuality audits); develop hybrid critics that combine LLM judgments with deterministic validators.
- Theoretical guarantees for evolution: Provide proofs or empirical guarantees of termination (no infinite loops), boundedness (state growth), and monotonic improvement (or conditions under which it holds); analyze convergence behavior and stability under repeated evolution.
- Completeness and granularity of atomic operations: Expand the operator set beyond ADD_STATE/DELETE_STATE/MODIFY_TRANSITION/REVISE_INSTRUCTION (e.g., MERGE_STATES, SPLIT_STATE, PARAMETERIZE_TRANSITION, TOOL_SWAP); measure per-operator impact and failure-mode coverage via controlled studies.
- Evolution control policy: Learn or design a policy to decide when to apply flow vs. skill operations, with cost-aware trade-offs (tokens, latency, API calls); replace the fixed 3-iteration cap with adaptive stopping criteria that predict diminishing returns.
- Memory management and scalability: Implement consolidation, abstraction, deduplication, and forgetting for the experience pool; study retrieval latency and quality as grows; evaluate alternative indexing (e.g., dense/sparse embeddings, case-based reasoning) and selection strategies beyond top‑k.
- Experience contamination and test leakage: Assess whether storing successful trajectories risks leaking answers across evaluation splits; enforce strict train/validation/test separation for memory retrieval and report leakage controls.
- Evidence-level evaluation: Complement accuracy with metrics for citation correctness, evidence sufficiency, reasoning faithfulness, and step-level validity; adopt standardized evidence audits (e.g., source verifiability, quote fidelity).
- Statistical rigor: Report variance across runs, confidence intervals, and significance tests; control for temperature, seeds, and tool nondeterminism to ensure robust, reproducible improvements.
- Efficiency and cost profiling: Provide comprehensive token, latency, and tool-call budgets across benchmarks; quantify overhead introduced by FSM phases (e.g., verification states) and the critic; evaluate cost-performance Pareto frontiers.
- Tool dependence and robustness: Test across diverse search and crawling stacks (e.g., different engines, scrapers, paywalled/dynamic sites); measure robustness to noisy, adversarial, or non-standard web content; compare against offline corpora settings.
- Multilingual and domain robustness: Systematically evaluate cross-lingual generalization (beyond DeepSearch’s Chinese context), and domain-specific performance (legal, biomedical, software) with tailored failure analyses.
- Safety and security under self-evolution: Examine resistance to prompt injection, tool misuse, and jailbreak attempts during evolution; integrate and evaluate shield mechanisms (e.g., policy constraints, tool access controls) and their interaction with atomic operations.
- Human-centered research quality: Assess end-to-end research deliverables (reports, bibliographies) with human evaluations for clarity, rigor, and reproducibility; measure traceability and auditability of evidence chains.
- Training and distillation pathways: Explore fine-tuning smaller specialized agents to internalize FSM logic; train , , and via RL/SFT/DPO; study multi-agent curriculum learning to reduce reliance on proprietary general-purpose models.
- Adaptive stopping and rollback: Design principled criteria to stop evolution (e.g., predicted marginal gain) and implement reversible versioning/rollback policies with safety checks to prevent harmful modifications.
- Initial topology discovery: Automate FSM initialization from prior corpora/trajectories via structure induction or graph search; compare manual vs. learned initial topologies and their downstream impact.
- State-space scalability: Investigate dynamic state merging/splitting and complexity controls to prevent combinatorial blow-up as tasks and domains expand; formalize trade-offs between granularity and manageability.
- Baseline breadth and fairness: Include additional strong baselines (e.g., WebAgent‑R1, Search‑R1) under matched tool budgets and constraints; verify identical retrieval stacks and fair optimization loops across methods.
- Reproducibility and artifacts: Ensure the GitHub repository, prompts, tool configurations, seeds, and logs are complete and functional; provide evaluation harnesses and dataset splits to enable third-party replication.
Practical Applications
Immediate Applications
Below are applications that can be deployed now with the methods and components described in the paper, leveraging existing LLMs, web tools (e.g., Serper, Jina Reader), and multi-agent orchestration (e.g., AutoGen).
- Enterprise deep-research assistant for market and competitive intelligence — Sector: software/knowledge management. Uses an FSM to structure multi-hop web/document research with
ADD_STATEverification nodes andMODIFY_TRANSITIONto escape search loops; Tools/Workflow: AutoGen-based orchestration, critic dashboard to flag missing evidence, experience pool to warm-start strategies for specific industries; Assumptions/Dependencies: reliable access to web and internal repositories, LLM quality, human-in-the-loop for sensitive deliverables. - Legal research and memo drafting with source QA — Sector: legal. Introduces a fact-verifier state, citation normalization via
REVISE_INSTRUCTION(e.g., prefer case law and statutes, enforce Bluebook-like citation), and failure-pattern constraints to avoid unreliable sources; Tools/Workflow: legal database connectors, critic prompts tailored to legal logic checks, memory of successful legal workflows; Assumptions/Dependencies: access to legal databases, auditing requirements, critic accuracy on subtle legal reasoning. - Biomedical literature review and systematic evidence synthesis — Sector: healthcare/biotech. FSM phases for search, screening (PDF prioritization), extraction, and verification; memory initializes disease- or mechanism-specific strategies; Tools/Workflow: PubMed/Preprint APIs, “Reason-in-Documents” style summarization within Analysis state, reusable priors for systematic reviews; Assumptions/Dependencies: source quality filters, provenance tracking, clinical disclaimers and oversight.
- Customer support knowledge retrieval and escalation — Sector: software/customer operations. Structured states for query triage, KB search, resolution synthesis, and escalation;
MODIFY_TRANSITIONto revisit search when gaps are detected by critic; Tools/Workflow: connectors to ticketing/KB, critic identifies missing steps and triggers tailoredREVISE_INSTRUCTION; Assumptions/Dependencies: access to internal KBs, security/privacy controls, model grounding in product-specific terminology. - Software repository exploration and bug triage — Sector: software engineering. FSM integrates code search, doc reading, test execution and verification states;
ADD_STATEfor unit-test or reproduction logs; Tools/Workflow: Repo/CI integration, critic checks repro evidence before concluding root cause; Assumptions/Dependencies: tool execution sandboxing, codebase access, safety guardrails for tool calls. - E-commerce product search and recommendation — Sector: commerce. From WebShop-style tasks, adopts states for requirements parsing, search, filter, verify (meets constraints), and final selection; memory stores failure patterns (e.g., misleading product titles) to constrain transitions; Tools/Workflow: marketplace APIs, critic ensures constraints (price, features) are satisfied; Assumptions/Dependencies: up-to-date catalog data, stable APIs, clear requirement capture.
- Financial analyst assistant for filings and earnings calls — Sector: finance. FSM sequences EDGAR search, multi-document cross-checking, numeric consistency verification; Tools/Workflow: evidence-verifier state to check figures across 10-K/10-Q/transcripts; Assumptions/Dependencies: access to filings/transcripts, critic trained to detect quantitative inconsistencies, compliance review.
- Academic literature review and study support — Sector: education/academia. States for topic decomposition, scholarly search, evidence extraction, citation formatting;
REVISE_INSTRUCTIONenforces DOI/peer-reviewed source preference; Tools/Workflow: Google Scholar/Crossref connectors, memory priors for subfields; Assumptions/Dependencies: access to scholarly databases, transparency on non-peer-reviewed sources, instructor oversight for graded work. - Government and policy fact-checking briefs — Sector: public policy. FSM imposes transitions that prioritize official sources and adds verification states before synthesis; Tools/Workflow: critic templates to flag unsupported claims, experience pool with negative constraints (E⁻) for known misinformation pathways; Assumptions/Dependencies: source whitelists/blacklists, public-sector privacy and auditability requirements, human review.
Long-Term Applications
Below are applications that are promising but likely require additional research, integration, scaling, or validation (e.g., fine-tuning specialized agents, robust critics, memory management).
- Fine-tuned FSM-aware small agents and trained critics — Sector: software/AI platforms. Distill FSM logic and atomic operations into smaller models; train domain-specific critics to reduce hallucinations and improve failure diagnosis; Tools/Workflow: supervised RL/finetuning on trajectories and critic labels; Assumptions/Dependencies: labeled datasets of good/bad trajectories, MLOps for continual updates.
- Clinical decision support integrated with EHRs — Sector: healthcare. FSM blends guideline retrieval, patient-context alignment, and verification with clinical constraints; Tools/Workflow: HL7/FHIR integrations, formal verifier nodes for contraindications; Assumptions/Dependencies: rigorous clinical validation, regulatory approval, robust safety guardrails, bias and liability management.
- Robotics task planning with self-evolving high-level FSM — Sector: robotics. Use evolution operations to adapt task plans (navigation, manipulation) based on sensor feedback; memory stores failure patterns (e.g., grasp failures) to adjust transitions; Tools/Workflow: coupling with motion planners and perception stacks; Assumptions/Dependencies: real-time reliability, safety constraints, sim-to-real transfer.
- Energy grid incident diagnosis and response playbooks — Sector: energy. FSM-driven workflows for alarm triage, root-cause analysis, and verification against telemetry; Tools/Workflow: SCADA data connectors, critic checks for contradictory signals; Assumptions/Dependencies: secure access to operational data, high availability, domain-specific validation.
- Enterprise AgentOps platform with workflow governance — Sector: software/enterprise IT. Productize FSM authoring, atomic-operation editors (
ADD_STATE,MODIFY_TRANSITION,REVISE_INSTRUCTION), audit logs, and A/B testing of flows; Tools/Workflow: versioned workflow compiler, change approval workflows, policy guardrails (E⁻ constraints); Assumptions/Dependencies: organizational buy-in, integration with IAM/compliance, UX for non-technical authors. - Self-evolving memory at scale with summarization, pruning, and knowledge-graph fusion — Sector: software/knowledge management. Build retrieval-efficient, deduplicated memory that abstracts strategies and links to a knowledge graph; Tools/Workflow: embeddings, clustering, graph construction and query; Assumptions/Dependencies: robust forgetting/merging algorithms, privacy-preserving storage, evaluation of memory quality over time.
- Formal safety and compliance verification of agent workflows — Sector: AI safety/policy. Map FSM transitions to machine-checkable properties and run automated compliance checks (e.g., source provenance, sensitive data handling); Tools/Workflow: formal specs for allowed transitions, verifiers integrated into critic; Assumptions/Dependencies: accepted standards for agent compliance, tooling for formal verification in LLM pipelines.
- Co-evolving multi-agent organizations across departments — Sector: enterprise operations. Decentralized teams of FSM agents that adapt via interaction rewards and shared memory (akin to CoMAS), coordinating research, procurement, and compliance; Tools/Workflow: inter-agent reward mechanisms, conflict resolution policies; Assumptions/Dependencies: robust coordination protocols, data sharing agreements, monitoring for emergent risks.
- Policy-making evidence synthesis at national scale (“living” reports) — Sector: public policy. Agents continuously ingest new evidence, evolve workflows, and maintain auditable chains-of-evidence; Tools/Workflow: periodical evolution cycles, source credibility scoring, stakeholder review portals; Assumptions/Dependencies: governance frameworks, public transparency, resilience against coordinated misinformation.
- Finance research and compliance copilots integrated with internal data and models — Sector: finance. FSMs that combine public filings with proprietary risk models and transaction logs, verifying outputs against internal controls; Tools/Workflow: secure data connectors, critic trained on financial logic; Assumptions/Dependencies: strict access control, regulatory audits, robust quantitative verification.
Glossary
- ADD_STATE: An atomic flow-edit operation that inserts a new intermediate state into the FSM to fix a workflow gap. "ADD_STATE inserts an intermediate state (e.g., a verification state) to bridge a workflow gap."
- Agentic RAG: A retrieval-augmented approach where an agent iteratively retrieves and reasons, autonomously issuing new retrievals as needed. "Agentic RAG\footnote{We follow the implementation details in \cite{li2025searcho1}.} introduces an iterative retrieveâreason loop, allowing the model to autonomously issue additional retrieval requests when the current evidence is insufficient."
- Atomic Operations: Minimal, discrete edits that evolve the FSM in a controlled, interpretable manner. "The framework evolves the FSM exclusively through a strictly defined set of Atomic Operations."
- AutoGen: A framework for orchestrating multi-agent LLM systems with reliable communication and stateful execution. "Our system builds on AutoGen \citep{wu2023autogenenablingnextgenllm} for multi-agent orchestration, enabling reliable inter-agent communication and stateful execution."
- Critic Mechanism: A supervisory evaluator that checks outputs against the query and triggers targeted evolution. "Critic Mechanism, a supervisory module that evaluates the final output against the user query."
- DELETE_STATE: An atomic flow-edit operation that removes redundant or low-utility states to streamline execution. "DELETE_STATE removes redundant or low-utility states to streamline execution."
- Experience Pool: A memory store of past successful and failed trajectories used to initialize and guide future evolutions. "the framework first retrieves the top- relevant historical strategies from the Experience Pool "
- Flow Operators: Atomic operations that modify the FSM’s collaboration topology and transition logic. "Flow Operators, denoted as , reconfigure the collaboration topology governed by the transition function ."
- Hallucination: When an LLM produces content not supported by evidence or reality. "which frequently leads to hallucination and instruction drift."
- Instruction Drift: Deviation of an agent’s behavior from its original instructions during evolution or iteration. "mitigating the instruction drift and instability"
- Jina Reader: A tool/API for extracting web-page content used by the agent. "the Jina Reader\footnote{\url{https://jina.ai} API for web-page content extraction."
- Long-horizon reasoning: Multi-step reasoning over extended sequences with delayed validation or feedback. "long-horizon reasoning."
- MODIFY_TRANSITION: An atomic flow-edit operation that changes conditions for moving between states. "MODIFY_TRANSITION adjusts transition conditions (e.g., revisiting Search when the retrieved evidence is insufficient)."
- Multi-hop QA: Question answering that requires combining evidence across multiple documents or steps. "five multi-hop QA benchmarks"
- Negative constraints: Retrieved failure patterns used to forbid or discourage harmful transitions or tools. "serve as negative constraints"
- Reason-in-Documents: A stage/module that performs structured reasoning within retrieved passages. "Reason-in-Documents stage"
- REVISE_INSTRUCTION: An atomic skill-edit operation that updates the prompt/instructions of a specific state. "REVISE_INSTRUCTION updates the guidelines or constraints for a single state (e.g., instructing the browsing state to prioritize PDFs over news sources to improve evidence quality)."
- ReAct: A prompting framework that interleaves reasoning steps with actions in the environment. "ReAct \citep{yao2023react}"
- Reflexion: A self-improvement method where agents critique and refine their behavior via feedback. "Reflexion \citep{shinn2023reflexion}"
- Retrieval-Augmented Generation (RAG): Generative modeling augmented by fetching external documents as context. "Standard RAG performs a single web-search round and appends the top retrieved documents to the prompt as additional context."
- Search-verify loop: A workflow pattern alternating between retrieving evidence and verifying it before proceeding. "initializing with a search-verify loop for medical diagnoses"
- Self-Evolution: The agent’s capability to modify itself (prompts, tools, or structure) based on feedback. "``Self-Evolution'' mechanisms"
- Self-evolving memory: A memory mechanism that accumulates strategies and failure patterns to guide future tasks. "a self-evolving memory mechanism that stores successful strategies as priors and failure patterns as constraints for future queries."
- Skill Operators: Atomic operations that refine state-specific instructions without altering global topology. "Skill Operators "
- Tool budget: A constraint on the number or cost of external tool uses during problem solving. "under the same tool budget."
- Unconstrained rewriting: Free-form self-modification of prompts/tools without structural guardrails. "unconstrained rewriting"
- Verifier node: A dedicated FSM state inserted to check source quality or validate evidence. "deploying a Verifier node to enforce source quality"
Collections
Sign up for free to add this paper to one or more collections.

