- The paper introduces PRPO, a method that aligns dense process rewards with sparse outcome signals to optimize policies for complex reasoning tasks.
- It employs entropy-driven token-level segmentation and PRM normalization to deliver stable token-wise guidance, effectively addressing credit assignment issues.
- Experimental results on MATH500 demonstrate accuracy gains from 61.2% to 64.4%, showcasing PRPO's improved performance and scalability over critic-free methods.
PRPO: Aligning Process Reward with Outcome Reward in Policy Optimization
Introduction to Problem and RLHF Limitations
LLMs powered by reinforcement learning (RL) have shown promise in performing complex reasoning tasks such as mathematics problem-solving, but conventional RL-based approaches often struggle with sparse reward signals. Critic-free methods like GRPO depend heavily on outcome-based reward mechanisms that standardize final responses, failing to provide adequate guidance for intermediate steps in multi-step tasks. This predicament amplifies the credit assignment problem leading to unstable optimization and inefficient training.
The inadequacy of sequence-level rewards becomes evident in tasks where solution correctness depends upon intermediate decisions rather than end results. Purely outcome-based rewards lack the ability to distinguish reasoning paths leading to the same answers via differing processes, thus restricting models from internalizing generalizable reasoning strategies. Addressing these inefficiencies requires a shift towards richer, process-oriented supervision mechanics that fill this instructional gap.
Figure 1: Comparison between outcome-level and process-level reward in RLHF.
Innovations and Methodology
To address these challenges, the paper proposes Process Relative Policy Optimization (PRPO), an advanced extension of critic-free policy optimization frameworks that integrates dense Process Reward Models (PRMs) with sparse outcome-based signals through semantic segmentation and distribution alignment. The PRPO approach effectively merges outcome reliability with intermediate guidance, offering a more holistic method to optimize policy reinforcement without overburdening the computational constraints associated with increased complexity.
Semantic-Based Segmentation
PRPO introduces an entropy-driven token-level segmentation mechanism that reliably identifies segments in reasoning sequences via semantic clues. The entropy peaks are chosen to formulate segments that are autonomously evaluated by PRMs. This segmentation ensures dense feedback aligns properly with token-level decisions, providing fine-grained supervision that outcome-based models often lack. This semantic strategy proves advantageous by avoiding the pitfalls of arbitrary segment formation, thereby ensuring relevant segments receive appropriately calibrated feedback.
Aligning Process and Outcome Rewards
The alignment framework bridges PRMs and outcome rewards to deliver stable token-wise guidance. By normalizing PRM outputs and aligning them with outcome advantages, PRPO ensures coherent distribution that keeps process rewards in sync with final outcomes. This process avoids premature reward collapse and accommodates for variations in token-level credit assignments, leading to improved model accuracy.
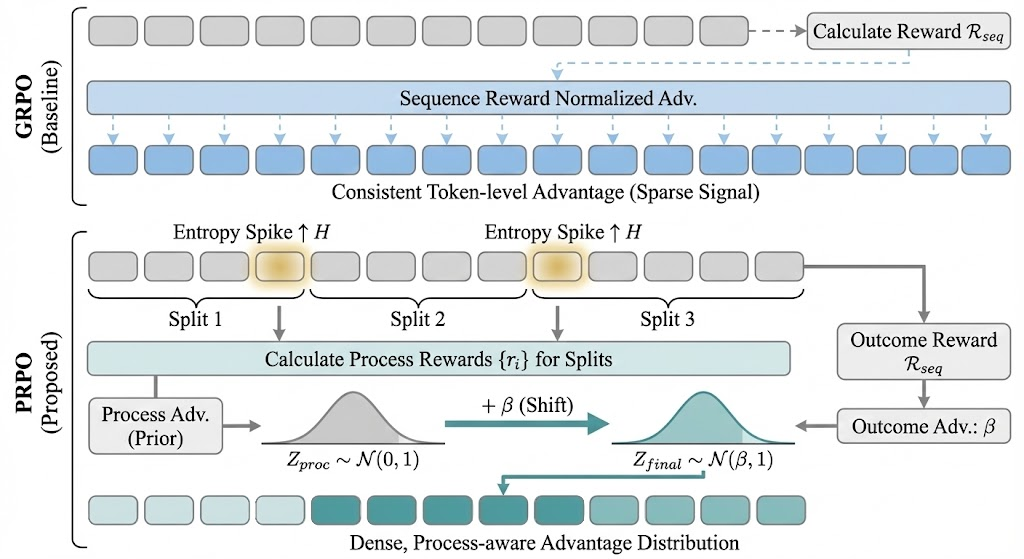
Figure 2: Comparison between GRPO and PRPO.
Experimental Validation
Extensive experiments demonstrate PRPO’s efficacy across mathematical reasoning benchmarks, revealing significant accuracy gains against competing methods. In specific benchmarks like MATH500, PRPO exhibited improvement in accuracy from 61.2% to 64.4%, outperforming GRPO with comparable rollout efficiency. The method also proved highly scalable, accommodating dense PRM feedback within critic-free optimization frameworks without excessive computational costs.
Performance comparisons confirm PRPO’s capacity to mitigate the drawbacks associated with purely outcome-based or process-only rewards; it delivers significant improvements regardless of task complexity or model capacity limitation. The robustness of PRPO, evidenced across datasets, demonstrates its applicability beyond theoretical constructs, making it a valuable approach in refining LLM alignment strategies.
Conclusion
PRPO introduces a transformative approach to policy optimization by integrating dense process rewards within sparse outcome frameworks, enhancing the instruction fidelity for LLMs tackling complex reasoning tasks. The process-level segmentation and reward distribution alignment collectively anchor PRPO as a reliable method to address reward sparsity issues, proving its practical value in real-world applications. Future work aims to integrate adaptive PRM evaluation strategies to further enhance policy optimization dynamics.
PRPO establishes significant strides in aligning task-level fidelity with process-level precision, marking a pivotal step towards scalable, efficient policy optimization in AI model training.

