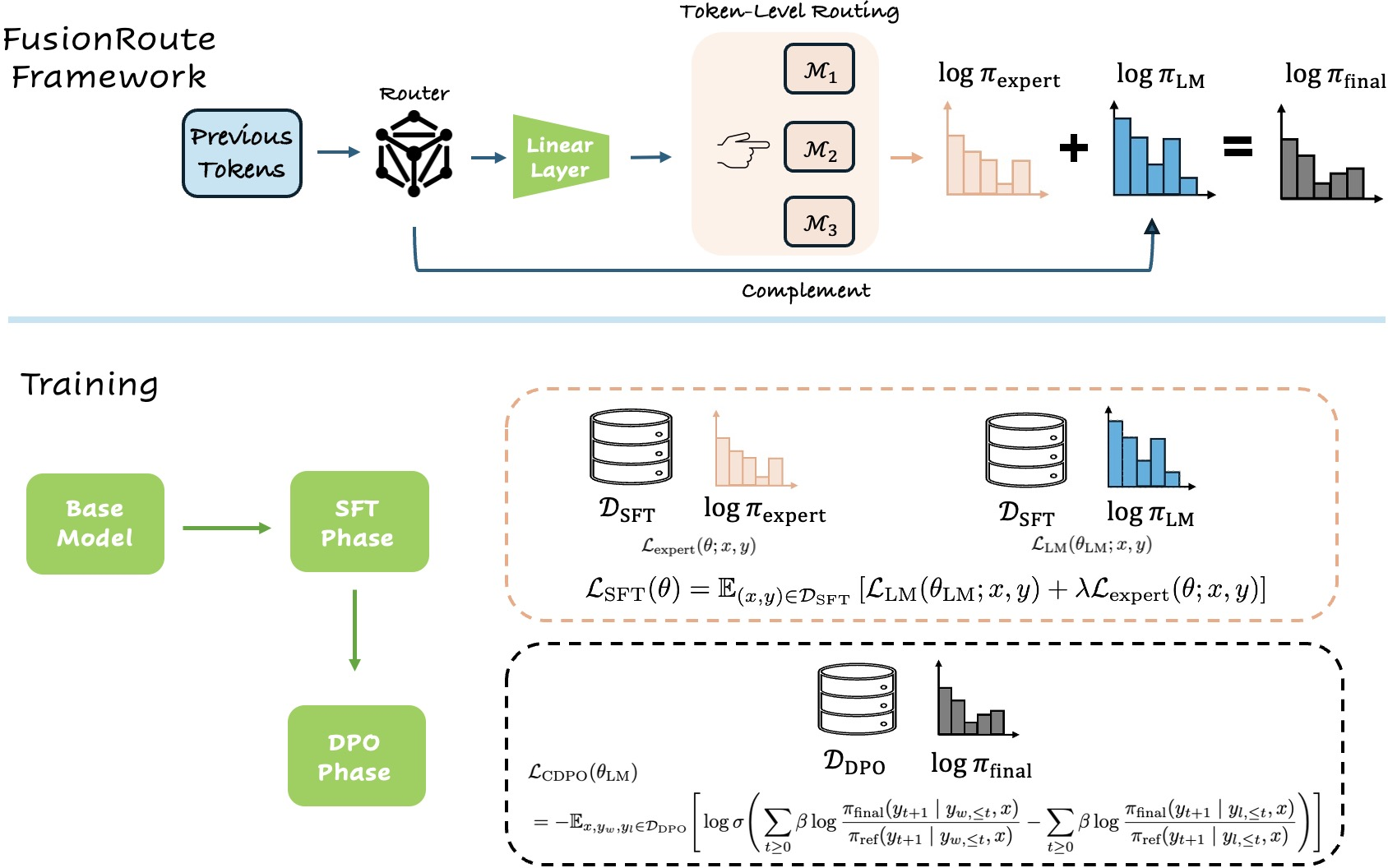
Token-Level LLM Collaboration via FusionRoute
Abstract: LLMs exhibit strengths across diverse domains. However, achieving strong performance across these domains with a single general-purpose model typically requires scaling to sizes that are prohibitively expensive to train and deploy. On the other hand, while smaller domain-specialized models are much more efficient, they struggle to generalize beyond their training distributions. To address this dilemma, we propose FusionRoute, a robust and effective token-level multi-LLM collaboration framework in which a lightweight router simultaneously (i) selects the most suitable expert at each decoding step and (ii) contributes a complementary logit that refines or corrects the selected expert's next-token distribution via logit addition. Unlike existing token-level collaboration methods that rely solely on fixed expert outputs, we provide a theoretical analysis showing that pure expert-only routing is fundamentally limited: unless strong global coverage assumptions hold, it cannot in general realize the optimal decoding policy. By augmenting expert selection with a trainable complementary generator, FusionRoute expands the effective policy class and enables recovery of optimal value functions under mild conditions. Empirically, across both Llama-3 and Gemma-2 families and diverse benchmarks spanning mathematical reasoning, code generation, and instruction following, FusionRoute outperforms both sequence- and token-level collaboration, model merging, and direct fine-tuning, while remaining competitive with domain experts on their respective tasks.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a new way to make several smaller, specialized AI LLMs work together smoothly and smartly. Big “do-everything” models are powerful but very expensive to run. Small “expert” models (like a math model, a coding model, and an instruction-following model) are cheaper and great at their specific jobs, but they can struggle outside their specialty. The authors propose FusionRoute, a system that acts like a coach: it picks the right expert for each next word during writing and adds a tiny correction to keep the text on track.
What questions does the paper try to answer?
The paper focuses on three simple questions:
- Can we make multiple small expert models collaborate at the level of each token (each next word) in a sentence?
- Can this collaboration be both efficient (fast and cheap) and robust (works well even when one expert is unsure)?
- What’s missing in older methods, and how does FusionRoute fix those problems?
How does FusionRoute work?
Think of writing a response as a team sport. Each “expert” model is a player skilled at part of the game (math, coding, general instructions). FusionRoute is the coach. For every next word:
- It chooses which expert to trust most for that step.
- It adds a small “nudge” to the expert’s suggestion to refine or correct it if needed.
In everyday terms:
- “Token-level” means deciding one word at a time, not the whole paragraph at once.
- A “router” is a small helper model that picks the best expert for the next word and adds a helpful correction.
- “Logits” are like raw scores each word gets before turning into probabilities; adding the router’s logits is like giving a slight bonus to the better word options.
- “Greedy decoding” means always picking the highest-scoring next word.
Training in two steps
To make the coach (router) smart and stable, the authors train it in two stages:
- Supervised Fine-Tuning (SFT): The router learns two things: 1) How to predict good next words in general. 2) How to pick the right expert at the moments that matter.
Important detail: it mostly trains routing on “informative” tokens—places where experts actually disagree—so it learns real differences instead of wasting time on tokens where everyone picks the same word.
- Complemented Direct Preference Optimization (CDPO): The router learns to add useful corrections when experts are shaky. Here, the training nudges the router to improve the final result without messing up its skill at expert selection. Practically, they mix SFT data with preference pairs (examples where humans preferred one answer over another) so the router stays good at both choosing experts and fixing small mistakes.
What did they find?
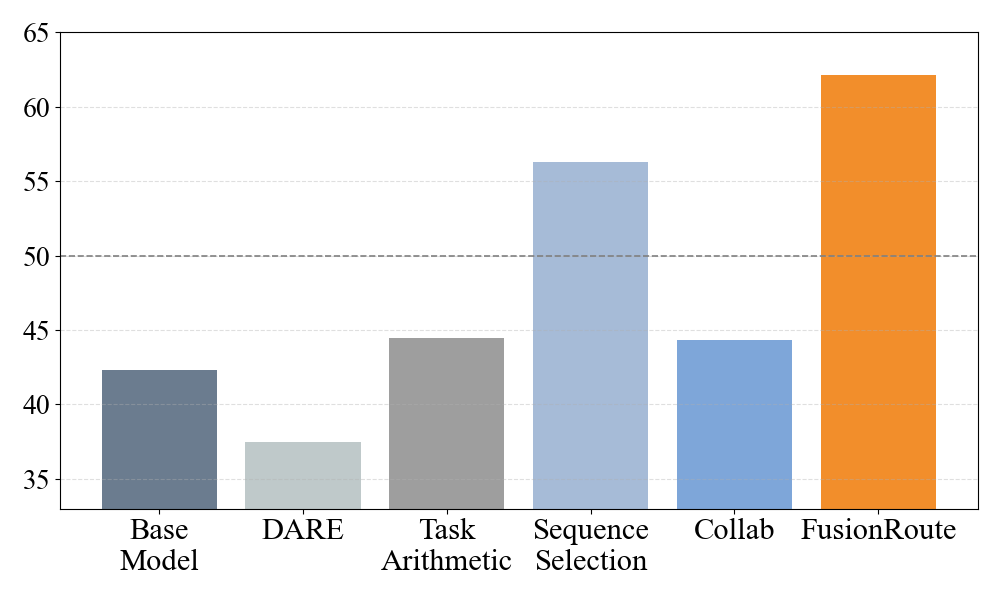
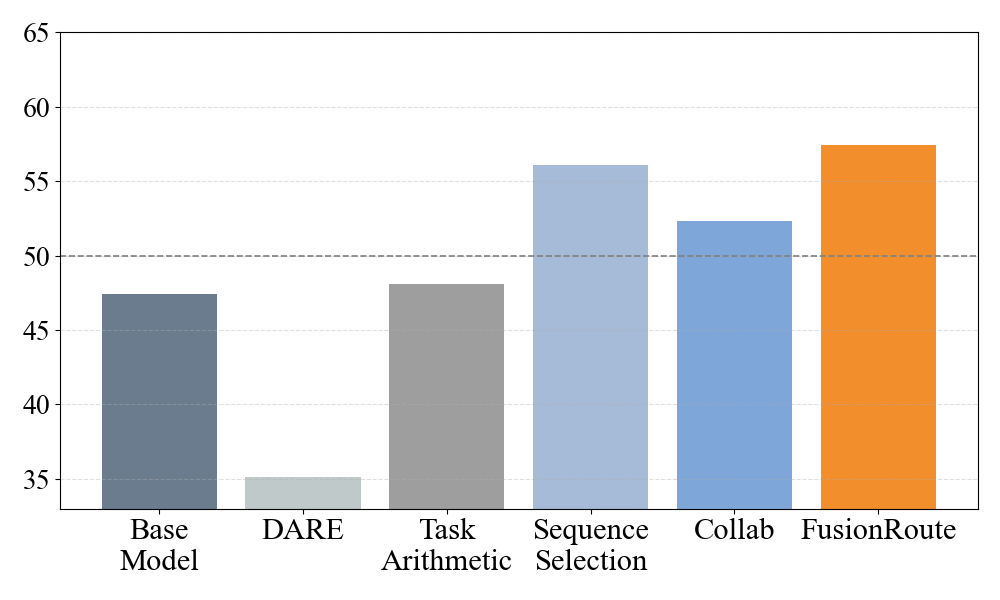
Across many tests and model families (Llama-3 and Gemma-2), FusionRoute beat or matched strong baselines:
- It outperforms:
- Sequence-level collaboration (where each expert writes an entire answer and a winner is picked at the end).
- Previous token-level methods that only choose between expert outputs without corrections.
- Model merging (combining expert weights into one model), which often blurs each expert’s strengths.
- Direct fine-tuning of a single general model, which can’t adapt per-token to different domains.
- It stays competitive with experts on their home turf:
- On math tasks (GSM8K, MATH500), coding tasks (MBPP, HumanEval), and instruction-following (IfEval), FusionRoute often matches or beats the best expert while remaining strong across all tasks.
- It improves overall response quality:
- FusionRoute achieves higher average accuracy across mixed-domain benchmarks.
- It also shows better win rates against strong references like GPT-4o on general datasets compared to just fine-tuning.
Why does this matter?
There’s a key theoretical insight: methods that only pick an expert’s output at each token (without adding corrections) can’t guarantee the best possible text unless your expert set covers every situation perfectly—which is unrealistic. FusionRoute’s “complementary correction” expands what the system can do, helping it stay close to optimal even when no single expert is perfect for a given moment.
In practice, this means:
- You can build a general-purpose system from cheaper, smaller expert models.
- The system is more reliable because the router corrects shaky expert predictions.
- It’s more efficient: no need to generate full answers from multiple experts before choosing; FusionRoute decides per token with minimal overhead.
- It’s flexible and automatic: users don’t have to pick which expert to use. The router does it on the fly.
Bottom line and future impact
FusionRoute shows a promising path to powerful, cost-effective AI systems by smartly coordinating small expert models at the level of each word. This can make AI assistants more accurate across many topics while staying fast and affordable. Looking ahead, this approach could support more expert types, plug-and-play expert additions, and better safety or reliability checks—all while keeping the collaboration simple and robust.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Efficiency and system-level metrics are not quantified:
- No measurements of inference latency, throughput, GPU memory footprint, or serving cost when running a router plus multiple experts per token.
- Training overhead for computing “informative tokens” (requiring per-token forward passes of all experts to detect disagreements) is not reported.
- Scalability to many experts is unclear:
- The router is evaluated with three experts; there is no analysis of performance, stability, or cost with larger expert sets (e.g., 10–100 experts).
- Memory and scheduling strategies for loading/switching among many experts at inference are not discussed.
- Vocabulary/tokenizer compatibility is not addressed:
- Logit addition requires aligned vocabularies; the approach is only demonstrated within a single family (e.g., Llama-3 or Gemma-2). Cross-architecture collaboration (different tokenizers or vocabularies) is not explored.
- Logit calibration and combination strategy is under-specified:
- Adding raw logits from two different models can cause miscalibration; there is no study of temperature/scale normalization, learned mixing coefficients, or alternative combination schemes (e.g., mixture-of-probabilities, gating weights on logits).
- No ablations on how complementary logit strength (e.g., an alpha parameter) affects performance and stability.
- Training objective and theoretical guarantees are misaligned:
- Theory assumes token-level rewards and uses greedy decoding; training uses sequence-level preferences (DPO). A formal link between the CDPO objective and the theoretical TV-distance bound is missing.
- Guarantees are derived under deterministic policies and fixed-length responses; practical LLM decoding (stochastic sampling, variable lengths) is not covered.
- Inference behavior mismatch between training and deployment:
- SFT trains routing with weighted logit aggregation across experts, whereas inference uses hard selection (argmax expert) plus router logits. The impact of this train–test mismatch is not evaluated.
- Router architecture design space is not explored:
- The router uses a single linear projection on the final hidden state. There are no ablations comparing deeper gating networks, attention over experts, token-wise vs. prefix-wise gating, or context-aware gating features.
- Stability of token-level expert switching is not analyzed:
- Frequent expert switching may introduce stylistic inconsistency or coherence issues within responses. Switching frequency, its effect on fluency, and mitigation strategies are not reported.
- Robustness to weak or adversarial experts:
- Claims of robustness are not backed by stress tests where one or more experts are severely miscalibrated, adversarial, or domain-mismatched. Worst-case performance and failure modes are not characterized.
- Generalization beyond three domains:
- Evaluations focus on math, code, and instruction following. No tests on other domains (e.g., multilingual tasks, factual QA, reasoning under uncertainty, safety-critical instruction following) to assess coverage and generality.
- Preference data alignment is limited:
- CDPO uses OpenHermes preferences mainly geared toward instruction following. The impact of domain-specific preference data for math/code or mixed-domain preference datasets is not studied.
- Decoding strategy constraints:
- Only greedy decoding is used. Performance, stability, and calibration under standard sampling strategies (top-p/top-k, temperature) and beam search are not evaluated.
- Quantitative efficiency vs. sequence-level collaboration:
- While FusionRoute is claimed to be more efficient than multi-agent full-sequence generation, there are no concrete comparisons of wall-clock generation time, token/sec, or context-length overhead versus sequence-level baselines.
- Safety, alignment, and guardrails are not examined:
- Combining logits from experts may inadvertently weaken safety filters or induce undesirable behaviors. Safety benchmarks, jailbreak robustness, and toxicity measurements are absent.
- Impact of routing during CDPO and parameter freezing choices:
- The routing layer is frozen during CDPO to avoid instability, but the trade-off between routing refinement vs. complementary correction is not analyzed. Alternative multi-objective or constrained optimization strategies remain unexplored.
- “Informative tokens” selection may bias training:
- Routing supervision is limited to disagreement tokens, risking neglect of semantically important but high-agreement tokens. The effect on routing quality and downstream performance is not quantified.
- Fairness and strength of baselines:
- Model merging hyperparameters are set to defaults; sensitivity analyses are missing. Collab’s reward models differ across families; the effect of stronger/weaker reward models is not controlled.
- Per-token cost of expert selection at training:
- Computing each expert’s argmax per token to detect disagreements can be expensive. Methods to approximate or cache disagreements, and their impact on accuracy, are not evaluated.
- Routing interpretability and auditability:
- There is no analysis of which expert is selected when, how often complement logits dominate, or why certain decisions are made. Tools or metrics for auditing routing decisions are missing.
- Long-context and memory constraints:
- Performance with long prompts/history and the impact on routing reliability and expert switching are not studied. Memory and KV-cache sharing strategies are not discussed.
- Incremental extensibility:
- How to plug in new experts post-deployment (without full retraining), update the router to accommodate them, or retire underperforming experts is an open question.
- Distillation to a single deployable model:
- Whether the fused policy (expert + router) can be distilled into a single model to reduce serving complexity is not explored.
- Multi-modal settings:
- The paper references GPT-4o win rates but the method is text-only. Extension to multi-modal experts, routing across modalities, and evaluation in multi-modal tasks are unexplored.
- Calibration and confidence estimation:
- The effect of logit addition on probability calibration (ECE, Brier score), confidence-quality correlation, and downstream risk-aware decision-making is not measured.
- Error analysis and failure taxonomy:
- There is no qualitative or quantitative error analysis (e.g., where FusionRoute fails vs. experts/fine-tuning, domain-specific pitfalls, types of errors introduced by expert switching or complementary logits).
- Comprehensive ablations and sensitivity:
- No ablations on λ (routing-vs-LM loss balance), β (preference strength), learning rates, disagreement thresholds, or router initialization; sensitivity to these choices remains unknown.
- Hardware and deployment constraints:
- Practical serving architectures (single vs. multiple GPUs, model parallelism, batching across experts, cache sharing) and their impact on throughput and cost are not covered.
- Theoretical coverage beyond strong assumptions:
- The impossibility result and recovery via complementation rely on stylized assumptions. Extending guarantees to stochastic policies, non-greedy decoding, and realistic reward structures remains open.
Practical Applications
Immediate Applications
Below are practical, deployable use cases that can be built with current models, tooling, and infrastructure based on FusionRoute’s token-level multi-LLM collaboration with complementary logits (SFT + CDPO), as evaluated on math, code, and instruction-following experts.
- General-purpose enterprise assistant assembled from domain experts (industry: software, enterprise IT)
- What: A single assistant that routes token-by-token between internal math, coding, and instruction experts, improving accuracy and robustness without requiring a monolithic large model.
- Tools/products/workflows: Router-as-a-microservice; inference middleware that loads experts + router; KV-cache scheduling to run router + selected expert per step; observability dashboard for per-token routing decisions.
- Assumptions/dependencies: Access to expert logits and same/compatible tokenizer vocabulary; low-latency inference stack (e.g., vLLM/TensorRT-LLM) to co-schedule router and expert; on-prem deployment for data/IP protection.
- IDE code assistant with token-level expert fusion (industry: software engineering)
- What: Per-token routing between a code LLM and a general LLM for comments, tests, or documentation; complementary logits stabilize outputs when the code expert is uncertain.
- Tools/products/workflows: IDE extension highlighting the active expert per token; CI bots that switch experts for test writing, refactoring, or patch explanation; offline cache to reduce latencies.
- Assumptions/dependencies: Consistent tokenization and vocab mapping; repository policy constraints and secure handling of proprietary code.
- Customer support copilots across heterogeneous product lines (industry: customer service, retail, telecom)
- What: Unified bot that dynamically leverages domain-specific experts (billing, technical troubleshooting, policy/QoS) at token level to reduce handoffs and full-sequence ensemble overhead.
- Tools/products/workflows: Integration with CRM/knowledge bases; router telemetry for case auditing; fallbacks to human agents when expert disagreement is high.
- Assumptions/dependencies: Domain-adapted experts and sufficient coverage in SFT/DPO data; latency budgets for real-time chat.
- Mixed-domain educational tutor (sector: education)
- What: Tutor that explains math, generates code examples, and provides general writing feedback in the same session by token-level routing; complementary logits reduce failure cascades.
- Tools/products/workflows: LMS plugin; auto-grading that routes to math/code experts for solutions and to instruct expert for feedback style; per-problem routing logs for instructors.
- Assumptions/dependencies: Age-appropriate guardrails; curated preference data to align tone and pedagogy; logging for academic integrity.
- Technical writing and analytics assistant (industry: finance, consulting, manufacturing)
- What: Drafts narratives, inserts calculations, and generates analytic code by switching between math/code/instruction experts within one response.
- Tools/products/workflows: Spreadsheet/BI plugin that routes to math expert for formula tokens and to narrative expert for surrounding prose; change tracking of which expert produced each span.
- Assumptions/dependencies: Data governance for client data; tokenizer harmonization and numeric stability checks for calculations.
- Clinical documentation copilot (sector: healthcare)
- What: Assists with summarizing visits, coding (ICD/CPT), and patient messaging by fusing a clinical specialist with a general communicative model; complementary logits temper specialist brittleness.
- Tools/products/workflows: EHR integration; PHI handling; token-level audit trail; human-in-the-loop sign-off.
- Assumptions/dependencies: Regulated deployment (HIPAA/GDPR); vetted medical experts; careful evaluation on clinical tasks before activation.
- Contract and policy drafting assistant (industry: legal, public sector)
- What: Combines a legal-domain expert for terminology/citations with a general model for structure and readability, switching per token to maintain style while preserving legal precision.
- Tools/products/workflows: Redline mode with expert provenance per clause; retrieval plug-in for jurisdiction-specific precedents.
- Assumptions/dependencies: Access to legal-domain expert weights (on-prem preferred); explainability and provenance logging for review.
- Cost/latency optimization for multi-expert stacks (industry: MLOps)
- What: Replace sequence-level multi-agent generation with token-level selection to cut redundant full generations and context bloat; run only one expert per step plus the router.
- Tools/products/workflows: Inference scheduler that pins router on a small GPU and streams the selected expert; KV reuse to minimize cache thrash.
- Assumptions/dependencies: Effective batching yields; robust backpressure and timeout policies for expert switches.
- Model marketplace orchestration (industry: AI platforms)
- What: A platform feature letting customers register specialized models and a router that composes them at token level for general-purpose chat.
- Tools/products/workflows: Simple API (register_expert, set_tokenizer_map, stream_generate); usage-based billing by expert token share; dashboards for expert win rates.
- Assumptions/dependencies: Model licenses allowing logit access; standardized tokenizer adapters; isolation across tenants.
- Research assistant for mixed-methods work (sector: academia)
- What: Token-level fusion of math reasoning (derivations), code (experiments), and prose (write-ups) for papers and lab notebooks.
- Tools/products/workflows: Notebook plugin; per-cell routing summaries; reproducible seeds and routing logs for scholarly transparency.
- Assumptions/dependencies: Domain data for SFT/DPO that match lab domains; optional alignment with lab writing style.
- Retrieval-augmented generation with expert fusion (industry: software, enterprise search)
- What: Combine a retrieval-aligned expert with math/code/instruct experts; router complements expert logits to stabilize out-of-domain queries.
- Tools/products/workflows: RAG pipeline step that exposes retrieved-context expert as an “expert”; heuristic throttles when experts disagree.
- Assumptions/dependencies: Quality retriever and chunking; guardrails to prevent over-trusting retrieved noise.
- Privacy-preserving on-device assistants (daily life)
- What: Local mixture of small models (e.g., Gemma-2B, Llama-3 small variants) for offline coding/math/help tasks; router adds safety/consistency.
- Tools/products/workflows: Lightweight GPU/CPU builds; quantized experts; fast tokenizer alignment; battery-aware scheduling.
- Assumptions/dependencies: Hardware constraints; quantization-aware calibration; reduced expert count to fit memory.
Long-Term Applications
These opportunities are promising but depend on further research, scaling, standardization, or infrastructure maturation.
- Cross-provider, low-latency token streaming across heterogeneous APIs (industry: cloud AI, telecom)
- What: Token-level routing across proprietary/open experts hosted by different providers with sub-100 ms step latencies.
- Tools/products/workflows: Streaming logits APIs; cryptographic channels; network-level QoS for token interleave.
- Assumptions/dependencies: Providers must expose logits and compatible vocabularies, or standardized adapters; tight network SLOs.
- Multimodal expert fusion (sector: healthcare, robotics, media)
- What: Token-level routing across text, vision, and audio experts with complementary logits for cross-modality grounding (e.g., radiology report with image grounding).
- Tools/products/workflows: Unified tokenizer/feature space; per-modality complementary heads; safety filters for hallucination.
- Assumptions/dependencies: Multimodal tokenization compatibility; reliable calibration across modalities; regulatory validation in high-stakes domains.
- Safety-critical autonomous coding agents (industry: software security, embedded/robotics)
- What: Agents that route between code generation, static analysis, and security experts per token, with formal verification loops.
- Tools/products/workflows: Integrated theorem provers/SMT solvers; toolformer-style APIs; explainable routing with proof obligations.
- Assumptions/dependencies: Verified toolchains; mature integration of formal methods; certified workflows for high assurance.
- Adaptive, online expert discovery and retirement (industry: MLOps, foundation model R&D)
- What: Systems that automatically identify where new experts are needed, train them, and update the router’s expert set over time.
- Tools/products/workflows: Continual learning pipelines; expert lifecycle management; budget-aware routing policies.
- Assumptions/dependencies: Catastrophic forgetting mitigation; robust evaluation to avoid regressions; governance of auto-generated experts.
- Federated/cross-silo expert collaboration (sector: healthcare, finance, public sector)
- What: Token-level fusion across organizations where each party hosts a domain expert; router composes outputs without sharing raw data.
- Tools/products/workflows: Secure enclaves, SMPC, or federated inference; auditable routing; data residency controls.
- Assumptions/dependencies: Privacy-preserving logit sharing; legal agreements; acceptable latency with crypto overhead.
- Regulatory-grade explainability and auditing (sector: governance, compliance)
- What: Token-level lineage tracing of which expert influenced each token and by how much (weights + complementary contribution) to meet audit requirements.
- Tools/products/workflows: Immutable logs; per-token attribution reports; red-teaming of routing decisions.
- Assumptions/dependencies: Standardized reporting schemas; acceptance by regulators; organizational processes for review.
- Domain-specific copilots in critical infrastructures (sector: energy, transportation, manufacturing)
- What: Assistants for grid operations, PLC code generation, or maintenance manuals that route among control, safety, and narrative experts.
- Tools/products/workflows: Digital twin simulation-in-the-loop; gated deployment with shadow mode; alarm integration.
- Assumptions/dependencies: Rigorous validation in simulators; incident response protocols; fail-safe fallbacks.
- Marketplace standard for tokenizer/lexicon interoperability (industry: AI platforms)
- What: A de facto standard enabling logit addition across heterogeneous models via shared or mapped vocabularies.
- Tools/products/workflows: Open adapters, dynamic vocab alignment, precision-aware remapping; certification tests.
- Assumptions/dependencies: Community adoption; IP/licensing clarity; negligible accuracy loss from mapping.
- Human factors–aware routing (sector: HCI, education, healthcare)
- What: Router objectives that incorporate user preferences, cognitive load, or reading level, not just task accuracy.
- Tools/products/workflows: Preference learning tied to user profiles; controllable style experts; A/B frameworks for human outcomes.
- Assumptions/dependencies: Longitudinal preference data; privacy-preserving personalization; robust generalization.
- Multi-objective, cost-aware routers (industry: MLOps)
- What: Routers that optimize accuracy, latency, and dollar cost jointly, learning to select cheaper experts or rely more on complementary logits when adequate.
- Tools/products/workflows: Cost-latency-accuracy Pareto optimization; dynamic scaling; spot instances for non-urgent workloads.
- Assumptions/dependencies: Reliable telemetry; policy constraints from SREs; robust behavior under load.
- Curriculum and standards for collaborative LLM systems (sector: academia, standards bodies)
- What: Benchmarks and courses focusing on token-level collaboration, identifiability limits, and preference-augmented routing (CDPO).
- Tools/products/workflows: Open datasets for informative-token routing; challenge tracks for heterogeneous expert fusion; reproducible baselines.
- Assumptions/dependencies: Community curation; sustained funding; cross-institution collaboration.
- Personalized local assistants with modular experts (daily life)
- What: Home/phone assistants that evolve a set of personal experts (e.g., home finance, fitness, hobbies) and a router that composes them seamlessly.
- Tools/products/workflows: On-device training for niche experts; privacy-respecting preference optimization; per-token provenance for user trust.
- Assumptions/dependencies: Efficient on-device fine-tuning; energy constraints; user consent and control.
Notes on Feasibility and Cross-Cutting Dependencies
- Logit access and tokenizer compatibility are foundational for logit addition; cross-architecture fusion needs robust vocab mapping or shared tokenizers.
- Latency and memory constraints: inference must co-run the router plus one expert per step; KV-cache and scheduling optimizations are critical.
- Data alignment: SFT on informative tokens and CDPO preference data should match deployment domains to prevent routing drift.
- Safety and governance: complementary logits can override experts; guardrails, audits, and human-in-the-loop checkpoints are recommended for high-stakes use.
- Licensing and IP: ensure expert models can be co-hosted and their logits combined under applicable licenses; protect proprietary data during inference.
Glossary
- Autoregressive policy: A probabilistic model that generates sequences by predicting each next token conditioned on previous tokens. "We formalize the decoding process of a LLM as sampling from an autoregressive policy ."
- Behavior cloning: An imitation learning method that learns a policy by mimicking expert actions from demonstrations. "because this is essentially equivalent to use behavior cloning for learning the actions that maximize the optimal value function ."
- BradleyâTerry model: A statistical model for pairwise comparisons used to derive preference-based objectives. "DPO derives a closed-form objective from the BradleyâTerry model, enabling policy updates through a purely supervised loss:"
- Complemented Direct Preference Optimization (CDPO): A training stage that applies preference optimization to the router’s base model while keeping expert outputs fixed, enabling complementary corrections. "We refer to this preference-optimization stage as Complemented Direct Preference Optimization (CDPO)."
- Controlled decoding: A generation strategy that evaluates candidate tokens against an external reward signal to guide token selection. "which performs controlled decoding by evaluating candidate tokens from multiple models using an external reward signal;"
- Direct Preference Optimization (DPO): A preference-based alignment method that optimizes a model using pairs of preferred and dispreferred responses. "we introduce a preference-optimization objective that applies Direct Preference Optimization (DPO)~\citep{rafailov2023direct} to the router's base model parameters $\theta_{\mathrm{LM}$."
- Domain-specific training distributions: Data distributions tailored to particular task domains, which can limit generalization. "due to inductive biases~\citep{levine2021inductive, si2023measuring} and domain-specific training distributions~\citep{yuan2023revisiting}."
- Greedy decoding: A decoding strategy that selects the highest-probability token at each step. "In both the empirical part and the theoretical part of our paper, we consider the greedy decoding, since it is the simplest and effective way for decoding."
- Identifiability failure: A situation where available observations do not uniquely determine the optimal actions or model selection. "The impossibility in Theorem~\ref{theorem:path} stems from an identifiability failure, where observing optimal values along trajectories generated by is insufficient to determine which expert actions actually realize those values."
- Inductive biases: Built-in assumptions or tendencies of a model that influence learning and generalization. "due to inductive biases~\citep{levine2021inductive, si2023measuring} and domain-specific training distributions~\citep{yuan2023revisiting}."
- Linear projection: A learned linear transformation used to map hidden states to routing weights. "The routing weights are generated via a lightweight linear projection applied to the final hidden state"
- Logit addition: Combining two distributions by summing their logits before normalization to refine predictions. "contributes a complementary logit that refines or corrects the selected expert's next-token distribution via logit addition."
- Markov Decision Process (MDP): A formal framework for sequential decision-making with states, actions, transitions, and rewards. "We formulate the decoding process as a token-level Markov Decision Process (MDP) "
- Mixture-of-experts (MoE): An architecture that routes inputs to different expert models within a unified system. "A natural direction toward such collaboration is mixture-of-experts (MoE), in which multiple experts are integrated into a unified architecture and trained jointly with a routing network~\citep{zhou2022mixture, xue2024openmoe, jiang2024mixtral, zengs}."
- Model merging: A technique that combines parameters from multiple specialized models into a single model. "A third direction is model merging~\citep{yang2024model, he2025mergebench}, which combines multiple specialized models into a single set of parameters."
- Multi-agent systems (MAS): Frameworks where multiple models or agents collaborate, often with distinct roles. "Another line of work aims to combine the strengths of specialized models through multi-agent systems (MAS),"
- Optimal decoding policy: The strategy for token generation that maximizes expected performance or reward. "it cannot in general realize the optimal decoding policy."
- Performance Difference Lemma (PDL): A result that relates the performance gap between two policies to their action-value differences across states. "we establish a conceptual connection between the Performance Difference Lemma (PDL)~\citep{kakade2002approximately} and our token-level routing training"
- Preference optimization: Training methods that align models to human or task preferences using comparative feedback. "we employ an additional preference optimization phase to encourage the router to actively learn complementary logit contribution while treating expert outputs as fixed."
- Preference pairs: Labeled pairs of responses indicating which is preferred and which is dispreferred for a given prompt. "Given preference pairs where and represent the preferred and dispreferred response respectively,"
- Policy class: The set of possible policies a system can represent; expanding it increases expressiveness. "FusionRoute expands the effective policy class and enables recovery of optimal value functions under mild conditions."
- Q function: The expected cumulative reward for taking an action in a state and following a policy thereafter. "Similarly, for , the Q function can be defined as"
- Reward model: An auxiliary model used to score or evaluate generated outputs. "and an external reward model selects the highest-scoring output."
- Routing loss: An objective that trains the router to prefer experts whose predictions align with ground truth at informative tokens. "To enable the token-level routing ability, we introduce a routing loss that"
- Routing network: A component that learns to select or weight experts based on context. "trained jointly with a routing network~\citep{zhou2022mixture, xue2024openmoe, jiang2024mixtral, zengs}."
- Routing weights: The learned coefficients that indicate the preferred expert(s) at a given token. "produces two outputs: a vector of routing weights "
- Sequence-level collaboration: Approaches where each model generates a full response and results are combined or selected afterwards. "Sequence-level collaboration is coarse and inefficient, while prior token-level methods are unstable."
- Supervised Fine-Tuning (SFT): Training a model to imitate high-quality responses using supervised learning before preference alignment. "Supervised Fine-Tuning (SFT) serves as the initialization stage of fine-tuning the LLM, where the model is trained to imitate human-written demonstrations using supervised learning."
- Token-level collaboration: Methods that allow multiple models to jointly decide each token during generation. "Empirically, % comprehensive evaluations across multiple domains and general datasets demonstrate that our approach achieves state-of-the-art cross-domain performance and the highest GPT win rate on general datasets. across both Llama-3 and Gemma-2 families and diverse benchmarks spanning mathematical reasoning, code generation, and instruction following, FusionRoute outperforms both sequence- and token-level collaboration, model merging, and direct fine-tuning, while remaining competitive with domain experts on their respective tasks."
- Token-level Markov Decision Process: An MDP formulation where each token generation step is a decision state-action transition. "We formulate the decoding process as a token-level Markov Decision Process (MDP) "
- Token-level reward function: A function that assigns rewards at the granularity of individual tokens or prefixes. "the reward function is a token-level reward function that maps any text to a real number."
- Total Variation (TV) distance: A measure of divergence between probability distributions used to bound policy differences. "we can assume that the TV distance of the policy is bounded."
- Transition kernel: The function defining state transitions given actions in an MDP. "and is the transition kernel"
- Value function: The expected cumulative reward from a state when following a policy. "the value function for a state can be defined as"
Collections
Sign up for free to add this paper to one or more collections.