- The paper introduces an architecture with four modular experts inspired by language, logic, social reasoning, and world knowledge.
- It employs a three-stage curriculum that induces enduring, interpretable functional specialization via token-level routing.
- Ablation studies and behavioral benchmarks demonstrate that specialized modules improve domain-specific performance with causal control.
Modular Reasoning in LLMs via Brain-Like Specialization
Introduction
The paper "Mixture of Cognitive Reasoners: Modular Reasoning with Brain-Like Specialization" (2506.13331) introduces a transformer architecture explicitly partitioned into modular experts reflecting key cognitive networks found in the human brain: language, logic, social reasoning (theory of mind), and world knowledge (default mode). Unlike prior mixture-of-experts (MoE) models that emerge specialization implicitly, this framework aligns modules with well-studied neural substrates and induces functional specialization through a staged curriculum. The work demonstrates that such architectures are interpretable, allow for causal ablation, enable inference-time steering, and competitively align model outputs both with human reasoning benchmarks and with behavioral metrics from cognitive psychology.
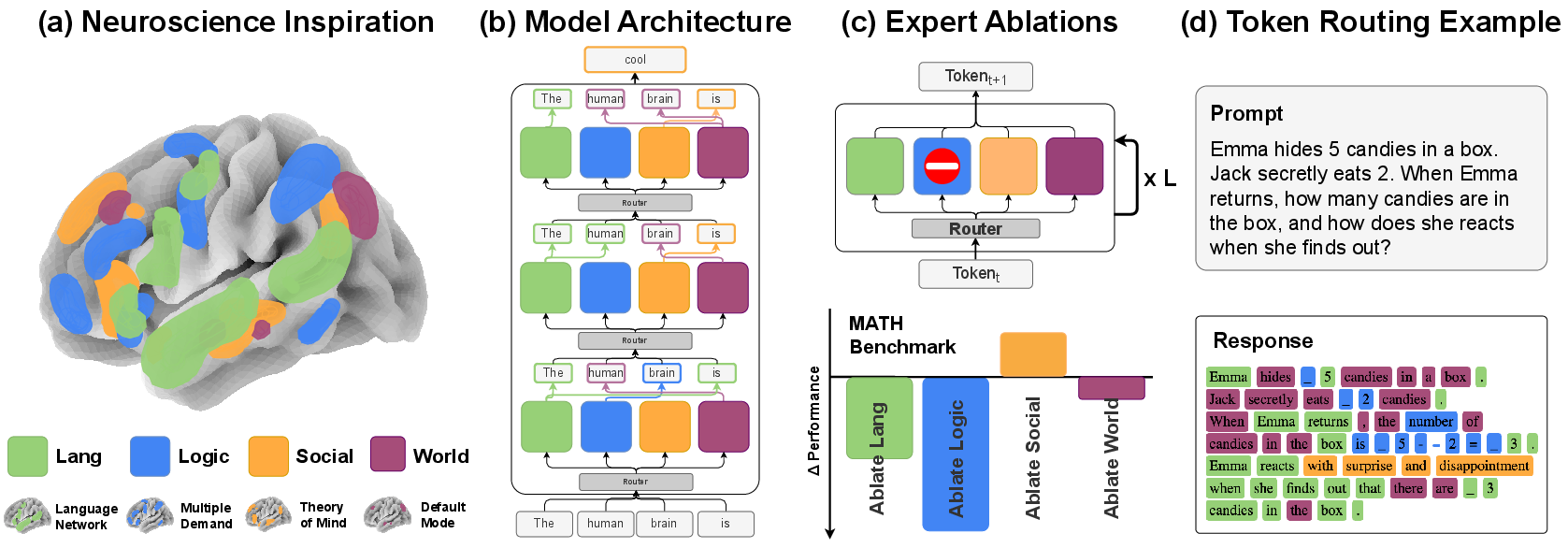
Figure 1: Brain-inspired Mixture of Cognitive Reasoners (\ourmodel) partitions transformer blocks into four modular experts, each reflecting a distinct cognitive network; a router dynamically assigns tokens per layer.
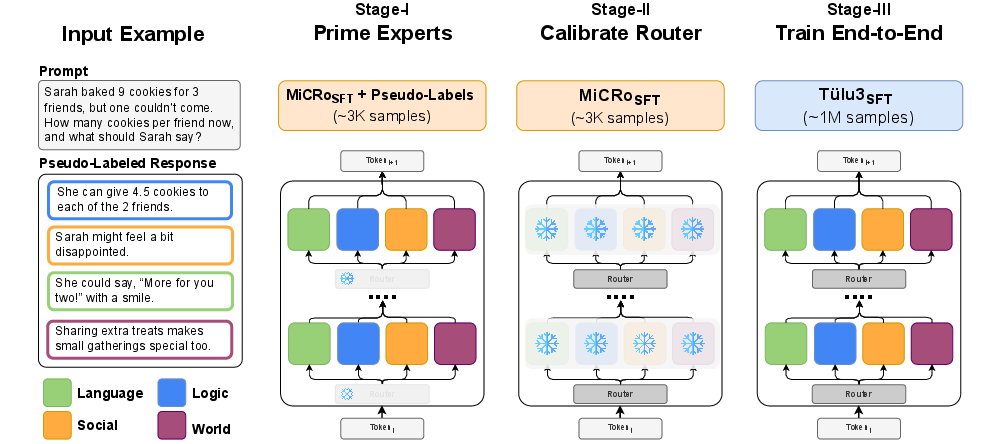
Architectural Design and Curriculum Training
The model uses a Mixture-of-Blocks (MoB) scheme: at each layer, the transformer block is cloned fourfold, with each resulting expert assigned a cognitive domain. A token-level router module chooses the appropriate expert for each token at each layer via top-1 routing, preserving computational efficiency and parameter parity with the dense baseline.
The specialization is induced via a three-stage curriculum:
This pipeline provides a robust inductive bias: even after substantial Stage III training, the specialization seeded in earlier stages persists, yielding stable and interpretable routing patterns throughout checkpoints.
Functional Specialization and Token Routing Dynamics
Routing analyses reveal that the model assigns tokens to experts in a semantically coherent manner, mirroring the selective engagement of neural networks in the brain. For example, arithmetic reasoning prompts activate the logic expert, while theory-of-mind scenarios route tokens preferentially to the social expert. Early layers consistently ground linguistic content via the language expert, while deeper layers transition to domain-specific experts according to prompt structure, closely paralleling hierarchical cortical dynamics observed in neuroimaging.
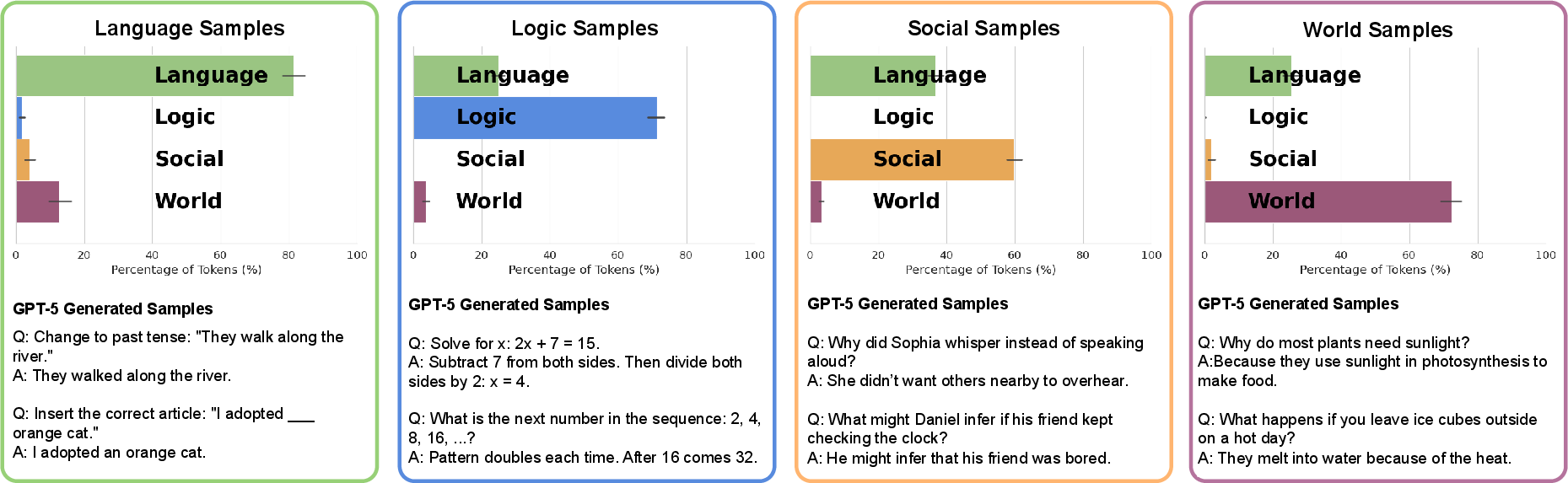
Figure 3: Token routing patterns in MiCRo-Llama-1B show domain-consistent expert selection, aligning with intended cognitive specialization across layers.
Further, router assignment probabilities correlate meaningfully with human behavioral annotations; for instance, the activation probability of the social expert tracks mental state content ratings (r≈0.7), and language expert probabilities align with ratings of plausibility and grammaticality.
Causal Interpretability: Ablations and Behavioral Steering
Expert ablation experiments provide causal evidence for functional specialization. Removing the logic expert results in marked drops on mathematics-heavy benchmarks (e.g., GSM8K, MATH), indicating that modular specialization is necessary for domain-specific performance. Conversely, ablating the social expert can in some cases yield small improvements on non-social tasks, reflecting well-differentiated contributions.
Test-time steering is achievable by restricting expert activation: prompts processed solely through the social expert produce empathetic or perspective-taking responses, whereas restricting to the logic expert induces analytically focused answers.
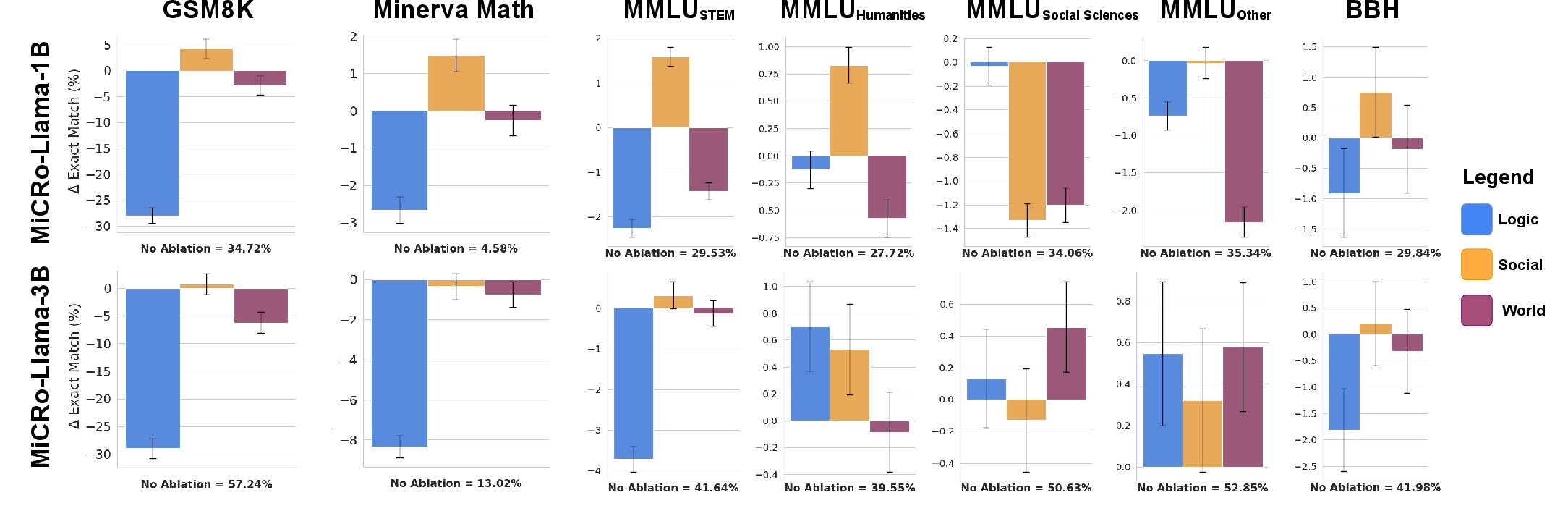
Figure 4: Performance impacts of ablating individual experts: removing logic expert drastically reduces math reasoning accuracy; language expert ablation incurs pervasive deficits.
Neuroscientific Alignment and Functional Localization
Applying functional localizer techniques from cognitive neuroscience shows that the induced experts map onto analogous domains: the language localizer identifies early-layer language experts; the multiple demand localizer isolates logic experts; theory-of-mind (ToM) localization is less robust but improves with model scale and dataset coverage. This correspondence validates the architectural design and offers a framework for computationally probing hypotheses about cognitive network contributions.

Figure 5: Neuroscience-inspired localizers recover functionally specialized experts, corroborating architectural alignment with cognitive neuroscience findings.
Behavioral Benchmarking: Human Alignment Metrics
On CogBench—a battery of behavioral tasks distilled from cognitive psychology—the MiCRo models outperform dense and generic MoB baselines, achieving higher similarity scores (SBRE) across behavioral dimensions, including risk assessment, meta-cognition, directed exploration, and more.
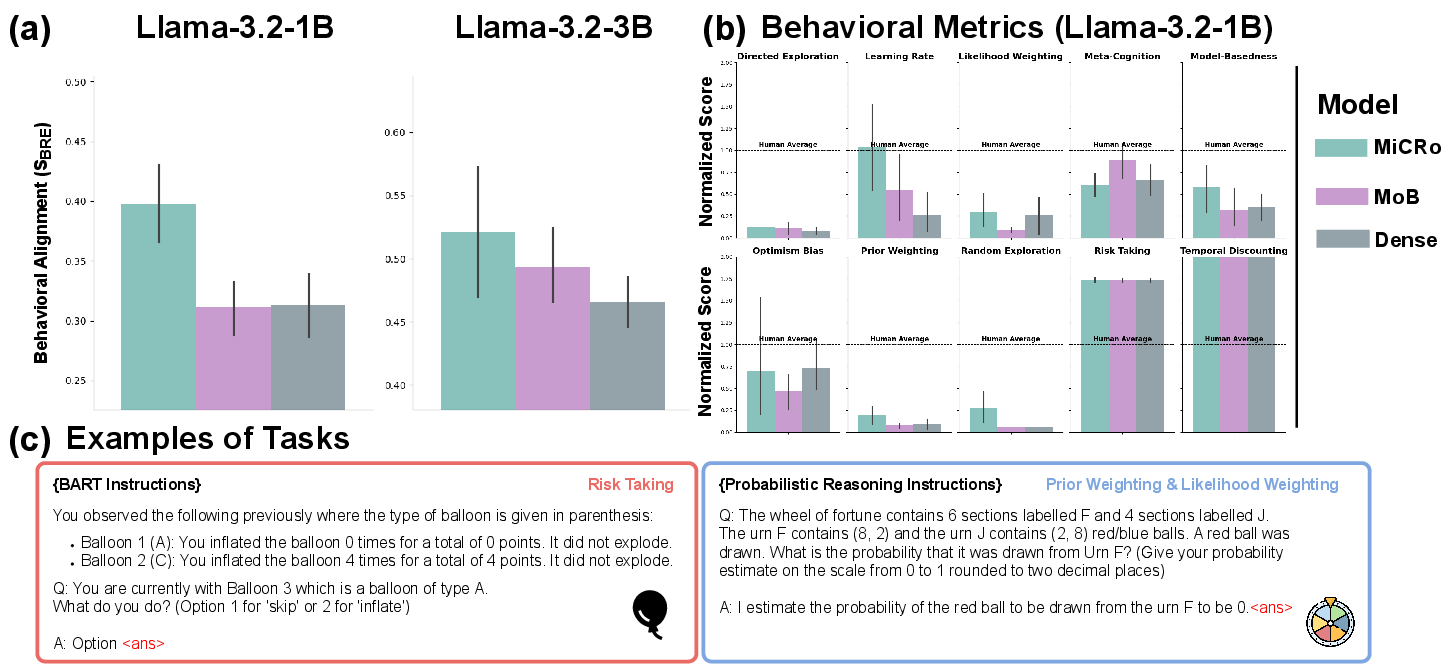
Figure 6: MiCRo-Llama models obtain superior alignment with human performance on CogBench metrics, exceeding baseline modular and dense counterparts.
Across reasoning benchmarks (GSM8K, MATH, MMLU, BBH), MiCRo models match or outperform both dense and generic modular baselines, despite explicit modularization. Domain-ablation further demonstrates that selectively retaining relevant experts can lead to continued gains (e.g., improved math accuracy when social expert is ablated on math benchmarks).
Implementation Considerations and Scaling
- Model Instantiation: Clone base transformer blocks per layer; implement top-1 router as an individual MLP for each layer.
- Token Labeling: Leverage SOTA models (e.g., GPT-4o) for token-level expert domain annotation; this demands scalable pseudo-labeling infrastructure.
- Training Pipeline: Use staged learning schedules with small batch domain-aligned data for specialization, then freeze parameters as needed per stage, culminating in full-scale supervised instruction tuning.
- Resource Requirements: The approach is computationally efficient due to top-1 routing, but memory footprint scales with the number of expert blocks.
- Scalability: MoB specialization persists robustly through models of moderate size (≤3B params); MoE specialization is less reliable, especially at higher scale in this framework.
Theoretical and Practical Implications
- Interpretability & Control: Induced specialization enables direct causal interventions and reasoning-domain steering. Fine-grained control at inference—through ablation or targeted routing—supports domain-specific deployment requirements.
- Neuroscience Modeling: Provides a computational substrate for simulating hypotheses about neurocognitive modularity, potentially guiding future experimental designs and analysis in systems and cognitive neuroscience.
- Extension to Other Domains: The approach generalizes beyond language, with infrastructure capable of scaling to additional cognitive modules as neuroanatomical or behavioral evidence emerges (e.g., intuitive physics, pragmatic reasoning).
- Efficient Inductive Bias: Demonstrates that minimal domain-aligned supervision (∼3k examples) suffices for enduring modular specialization, offering practical gains in data efficiency for architecture-conditioned learning.
Conclusion
The Mixture of Cognitive Reasoners approach substantiates that modularization informed by cognitive neuroscience can endow transformer models with interpretable, causal, and steerable specialization—yielding competitive performance, enhanced interpretability, and tighter behavioral alignment. This paradigm augments both the computational toolkit for interpretable NLP and the scientific framework for bridging AI architectures with human cognition, setting the stage for further cross-disciplinary advances in modular intelligence.