R$^3$L: Reflect-then-Retry Reinforcement Learning with Language-Guided Exploration, Pivotal Credit, and Positive Amplification
Abstract: Reinforcement learning drives recent advances in LLM reasoning and agentic capabilities, yet current approaches struggle with both exploration and exploitation. Exploration suffers from low success rates on difficult tasks and high costs of repeated rollouts from scratch. Exploitation suffers from coarse credit assignment and training instability: Trajectory-level rewards penalize valid prefixes for later errors, and failure-dominated groups overwhelm the few positive signals, leaving optimization without constructive direction. To this end, we propose R$3$L, Reflect-then-Retry Reinforcement Learning with Language-Guided Exploration, Pivotal Credit, and Positive Amplification. To synthesize high-quality trajectories, R$3$L shifts from stochastic sampling to active synthesis via reflect-then-retry, leveraging language feedback to diagnose errors, transform failed attempts into successful ones, and reduce rollout costs by restarting from identified failure points. With errors diagnosed and localized, Pivotal Credit Assignment updates only the diverging suffix where contrastive signals exist, excluding the shared prefix from gradient update. Since failures dominate on difficult tasks and reflect-then-retry produces off-policy data, risking training instability, Positive Amplification upweights successful trajectories to ensure positive signals guide the optimization process. Experiments on agentic and reasoning tasks demonstrate 5\% to 52\% relative improvements over baselines while maintaining training stability. Our code is released at https://github.com/shiweijiezero/R3L.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces a new way to train AI models (especially LLMs, or LLMs) to reason better and act more effectively in multi-step tasks. The method is called R³L, which stands for Reflect-then-Retry Reinforcement Learning. The big idea is to help the AI learn from its mistakes by:
- using language feedback to figure out what went wrong,
- fixing only the parts that need correction, and
- turning up the “volume” on successful attempts so they guide learning more strongly.
This helps the AI solve harder problems more reliably and with less wasted effort.
Key objectives: What problems are they trying to solve?
The paper focuses on three common issues when training AIs with trial-and-error learning (reinforcement learning):
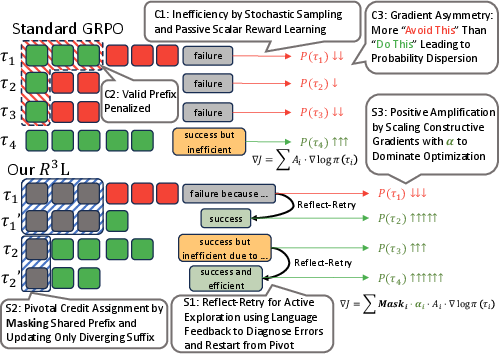
- Inefficient exploration: On tough tasks, most attempts fail. Randomly trying from scratch over and over wastes time and money.
- Unfair credit assignment: If the AI makes a late mistake, the usual training method punishes the whole attempt, including the parts it did correctly. That confuses learning.
- Training instability: When failures greatly outnumber successes, the AI mostly learns “what not to do” and becomes uncertain or “noisy,” instead of being guided toward the right solutions.
Their goal is to make exploration smarter, credit assignment more precise, and training more stable.
Methods: How does R³L work?
Think of the AI like a student solving a long math problem or playing a multi-step game. R³L teaches the student to reflect on errors, retry from the right place, and learn strongly from wins. It has three main parts.
Before the list, here’s a quick note: in these tasks, an “attempt” is called a trajectory—basically the sequence of steps the AI takes to solve a problem. A “pivot” is the first step where things start going wrong.
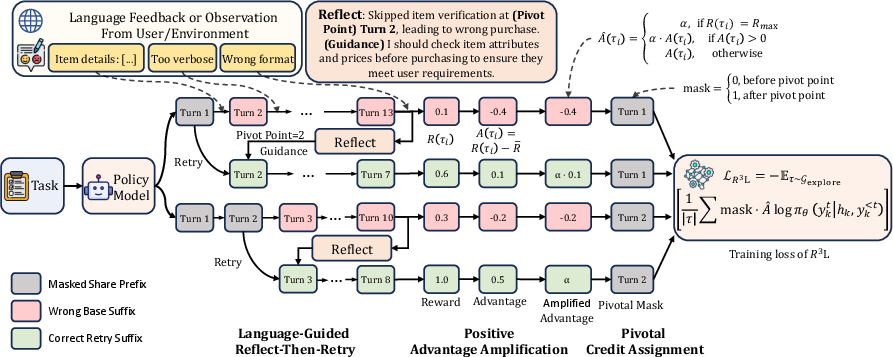
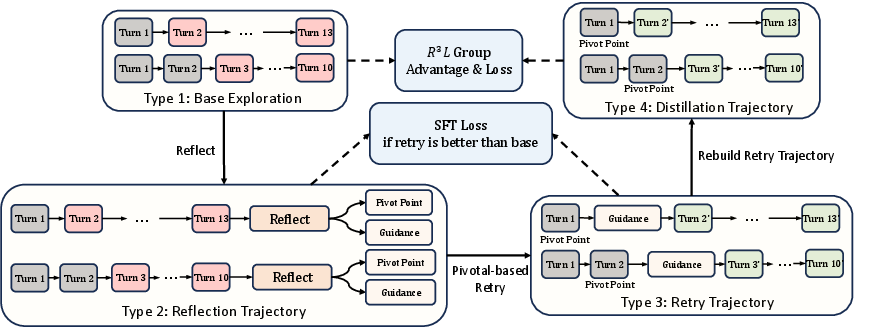
- Reflect-then-Retry
- What it does: When the AI fails, it writes down in plain language what went wrong, pinpoints the first bad step (the pivot), and then tries again starting from that point with a correction.
- Why it helps: Instead of restarting from the beginning, it fixes the exact part that caused the failure. This saves time and produces more successful attempts.
- Smart detail: During training, they remove the guidance text from the input when they stitch the corrected suffix to the original prefix. This forces the model to “absorb” the correction so it can apply it by itself later, without needing extra hints.
- Pivotal Credit Assignment
- What it does: When comparing the original attempt and the corrected retry, both share the same beginning (prefix) and only differ after the pivot (suffix). R³L updates the model only on the part after the pivot.
- Everyday analogy: If you got the first 9 steps right and messed up on step 10, the teacher should only mark step 10 wrong—not the entire solution.
- Why it helps: It avoids penalizing correct reasoning and focuses learning exactly where the choice led to success or failure.
- Positive Amplification
- What it does: It boosts the learning signal from successful attempts so they stand out in groups where many attempts fail.
- Everyday analogy: In a noisy classroom, the teacher speaks louder when explaining the correct solution so everyone clearly hears it.
- Why it helps: Without this, the AI mostly learns “don’t do that,” which can make it uncertain. Amplifying positive examples directs the AI toward the right answers.
- Keeping the skills fresh
- The authors also train two small helper tasks:
- “Learn to reflect”: practice writing clear diagnoses of what went wrong.
- “Learn to retry”: practice generating corrected steps using guidance.
- These keep the reflection and retry skills strong throughout training.
Main findings: What did they discover?
Across many tests, R³L consistently improved performance compared to strong baselines:
- Agent tasks (like simulated household tasks, web shopping, and science environments): R³L ranked best or second-best in most settings, with noticeable boosts on more complex, long-horizon tasks.
- Math reasoning (benchmarks like GSM8K, Math500, OlympiadBench): R³L often achieved higher accuracy, especially on harder sets where random sampling struggles.
- Overall improvements ranged from about 5% to 52% compared to standard methods, depending on the task and model size.
- The reflect-then-retry step often turned failed tries into successful ones, especially for tasks where errors are easy to spot and fix. For example, on ALFWorld with a larger model, more than 70% of retries improved over the original attempts.
Why this matters:
- It cuts down on wasted effort by not restarting from scratch.
- It prevents good early reasoning from being punished.
- It stabilizes training even when there are lots of failures.
Implications: Why is this important and what could it change?
- Smarter AI assistants: This approach can make AIs better at multi-step reasoning, like solving math problems, navigating websites, writing code with error messages, or following instructions in complex environments.
- Lower training costs: By retrying from the exact failure point and learning strongly from successes, training becomes more efficient.
- More reliable learning: The model stays stable and focused on correct solutions, even when successes are rare.
- Future directions: It looks promising for any domain where feedback exists (like error messages or hints). The paper focuses on tasks with clear right/wrong answers; applying it to creative or open-ended tasks needs more research.
Limitations to keep in mind:
- Reflection takes an extra pass, though restarting from the pivot saves time overall.
- Smaller models may need a warm-up period to learn good reflection skills.
- The method is proven on tasks with clear correctness; open-ended tasks may be trickier to validate automatically.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single, consolidated list of the key knowledge gaps, limitations, and open questions left unresolved by the paper. Each item is framed to be concrete and actionable for future research.
- Formal convergence and bias analysis: Provide theoretical guarantees for the RL objective after removing importance sampling and KL constraints, including bounds on off-policy divergence, conditions for stability under amplified advantages, and provable mitigation of “entropy collapse.”
- Reliability of pivot localization: Quantify the accuracy of model-identified pivot turns () relative to true error locations; develop automated validators (e.g., verifier signals, environment traces) and evaluate how mislocalized pivots affect learning and credit assignment.
- Granularity of pivotal credit: Investigate token-level or step-level masks (soft/probabilistic masks) instead of turn-level masking; handle multiple pivots per trajectory and cases where errors propagate across turns.
- Adaptive positive amplification: Systematically study sensitivity to the amplification factor and design adaptive schedules (e.g., based on group composition, success rate, or uncertainty) that avoid mode collapse and excessive suppression of exploration.
- Exploration–diversity trade-offs: Measure how positive amplification affects exploration diversity (e.g., entropy, type-token variety, KL to a reference) and propose mechanisms to preserve diversity (temperature schedules, capped amplification, entropy bonuses).
- Off-policy correction bias: Quantify the distributional shift between guidance-conditioned retry generation and guidance-free training/inference; compare “context distillation” (removing guidance in training inputs) versus guidance-preserving training to assess generalization without feedback at inference.
- Robustness to noisy or adversarial feedback: Evaluate RL under corrupted, sparse, or misleading environment messages; introduce confidence-weighted reflection, feedback filtering, or ensemble critique modules to improve resilience.
- Cold-start mitigation for small models: Develop bootstrapping strategies (synthetic reflection pretraining, curricula, teacher–student distillation) to reduce warm-up time and compute for models that initially fail to produce actionable reflections.
- Training cost and scalability: Report wall-clock time, GPU hours, and token-level cost breakdowns (reflection pass vs saved retries); benchmark scalability across model sizes, group sizes, and environments.
- Domain generality and subjective tasks: Validate RL in open-ended domains (creative writing, dialog) where ground-truth verification is subjective; design reliable automated preference signals or evaluators to support retry validation.
- Pivot sourcing comparison: Compare model-driven pivot selection to environment-derived pivots (e.g., exception lines, stack traces, verifier cues) to determine which yields better corrections, lower rollout cost, and higher stability.
- Handling multiple error points: Extend reflect–retry to multi-pivot scenarios with branching corrections; study stitching consistency and state alignment when retries alter intermediate environment state.
- State consistency and re-execution: Ensure that stitched trajectories (prefix + corrected suffix) remain consistent with environment state; incorporate re-execution or state replay to detect and discard inconsistent corrections.
- Group size and normalization effects: Analyze sensitivity to group size and reward normalization; characterize how group composition (failure dominance, reward variance) impacts advantage scaling and stability.
- Variance and significance reporting: Include multi-seed experiments with mean ± std and statistical tests; current results lack error bars, making robustness claims hard to assess.
- Synergy with stabilizers: Test combinations with KL penalties, clipping (e.g., BAPO), sequence-level ratios (GSPO), and entropy regularization to identify complementary stabilization strategies or conflicts.
- Lightweight process rewards: Explore integrating verifier signals or learned step-level rewards that do not require expensive human labels; compare to Process Reward Models in stability and cost.
- Inference-time self-reflection: Evaluate whether trained models can self-reflect and retry at inference without environment feedback; define deployment protocols for agentic settings where feedback may be partial or delayed.
- Auxiliary SFT selection bias: Assess the impact of training reflection/retry only on verified successful corrections; consider incorporating failed corrections and hard negatives to reduce bias and improve robustness.
- Token-level retry for single-turn tasks: In math reasoning, study fine-grained token-level restart positions within a solution draft and evaluate gains versus turn-level stitching.
- Expanded evaluation metrics: Add trajectory stability metrics (entropy, KL-to-ref, advantage variance), diversity measures, and sample-efficiency curves; current reporting emphasizes final average reward without deeper dynamics.
- Reproducibility details: Release seeds, prompts, environment configurations, and ablation scripts; many critical details are in appendices or omitted from the main text, hindering independent replication.
- Safety and integrity considerations: Examine risks from misleading or adversarial feedback, ensure alignment of corrections with environment constraints, and assess broader safety implications of language-guided retries in real-world agentic systems.
Practical Applications
Immediate Applications
Below are concrete, near-term use cases that can be deployed with today’s LLMs and infrastructure, leveraging R3L’s reflect-then-retry, Pivotal Credit Assignment, and Positive Amplification.
- Software engineering and DevOps (software)
- Use case: Test-aware code-repair assistants that parse compiler/unit-test messages, diagnose the first failing function (pivot), and regenerate only the failing segment; CI bots that auto-patch PRs and rerun failing jobs from the pivot.
- Potential tools/products/workflows: GitHub/GitLab Action plugins; “reflect-and-retry” patch microservice; RL training on build/test logs with guidance removal distillation.
- Assumptions/dependencies: Deterministic validators (tests/linters); execution sandbox; robust logging; access to error traces.
- Web automation and e-commerce agents (software, retail)
- Use case: Browser agents for product discovery and checkout that interpret HTTP/DOM errors, identify the step where navigation failed, and retry from there; form-filling agents that correct schema violations.
- Potential tools/products/workflows: Headless browser + R3L loop; DOM-error-to-guidance adapters; shopping/search assistants.
- Assumptions/dependencies: Clear completion rewards; instrumented error messages; bot policy compliance and rate limits.
- Data engineering/ETL reliability copilots (software)
- Use case: Pipeline-repair agents that read job logs, pinpoint the failing task (pivot), propose config/code fixes, and resume DAGs from that node.
- Potential tools/products/workflows: Airflow/Prefect plugin; log parsers to language feedback; rollback/canary deploy pipelines augmented with R3L.
- Assumptions/dependencies: Structured logs; safe partial re-execution; deterministic validation checks.
- Math tutoring and grading (education)
- Use case: Stepwise tutors that diagnose the first incorrect step in a student’s solution and generate a corrected continuation; graders that preserve correct prefixes and give targeted hints.
- Potential tools/products/workflows: LMS integrations; auto-grader + hint generator; RL training on verified math datasets with Pivotal Credit.
- Assumptions/dependencies: Reliable solution checkers; pedagogy-aligned hinting; content safety.
- Customer support and back-office automation (services)
- Use case: Claim/intake form agents that reflect on backend validation errors and retry from the invalid field; ticket resolution assistants that propose corrected actions from the failure point.
- Potential tools/products/workflows: CRM copilots; validation-feedback adapters; reflect-then-retry workflow templates.
- Assumptions/dependencies: API access; clear acceptance criteria; privacy/compliance controls.
- Scientific computing and protocol planning in simulators (science, R&D)
- Use case: Simulation/lab assistants that read error/status strings, identify the failed step of a protocol, and regenerate from that step; long-horizon scientific reasoning tasks (ScienceWorld-like).
- Potential tools/products/workflows: Electronic lab notebook (ELN) integrations; protocol planners; simulator bridges with R3L loops.
- Assumptions/dependencies: High-fidelity simulators; safe action spaces; verifiable end conditions.
- LLM training infrastructure for reasoning and agents (AI infrastructure)
- Use case: Replace GRPO in math/agent RL training with R3L to synthesize higher-quality trajectories (via reflection), stabilize training without PRMs, and reduce compute by restarting from pivots.
- Potential tools/products/workflows: R3L trainer modules; trajectory stores for base/retry pairs; advantage amplification scheduler; gradient-masking trainer.
- Assumptions/dependencies: Environments with verifiable rewards; auxiliary SFT tasks to maintain reflection/retry; hyperparameter tuning of amplification factor α.
- Compliance/KYC document assembly (finance)
- Use case: KYC/AML document agents that reflect on schema/validator feedback, correct missing or inconsistent fields, and resubmit from the specific section.
- Potential tools/products/workflows: Document assembly copilots; validator-driven retry loops; audit logs with pivot annotations.
- Assumptions/dependencies: Standardized validators; human-in-the-loop approvals; auditability and data governance.
- Personal productivity assistants (daily life)
- Use case: Travel-booking and form-filling assistants that interpret failure messages (e.g., payment declined, seat unavailable) and retry from that step with alternatives; writing tools that reflect and rewrite only flawed paragraphs.
- Potential tools/products/workflows: Browser/editor plugins; “pivot-aware” retry scaffolds; outcome-based reward metrics (booking success, task completion).
- Assumptions/dependencies: Access to feedback messages; user consent; reliable validators and rate limits.
Long-Term Applications
The following require additional validation, scaling, safety assurance, or domain integration before broad deployment.
- Embodied robotics and service robots (robotics)
- Use case: Robots that generate natural-language self-diagnostics from sensor/execution anomalies, identify the failing subroutine (pivot), and retry only that subroutine; long-horizon task learning with Pivotal Credit.
- Potential tools/products/workflows: R3L-enabled robot training in simulators; language-grounded failure analyzers; subroutine-level retry controllers.
- Assumptions/dependencies: Robust language feedback from perception; sim-to-real transfer; strict safety/containment.
- Clinical documentation and decision support (healthcare)
- Use case: Agents that draft clinical notes/orders, reflect on guideline/EHR validator feedback, and retry; stepwise differential diagnosis planning with credit focused on late-stage errors.
- Potential tools/products/workflows: EHR-integrated copilots; prior-authorization assistants; clinical validators providing language feedback.
- Assumptions/dependencies: Regulatory approval; rigorous validation and bias auditing; PHI privacy; human oversight.
- Public-sector digital services automation (policy, government)
- Use case: Application/tax filing assistants that leverage agency validation messages to fix errors and resubmit from the exact section; reduce citizen resubmission burden.
- Potential tools/products/workflows: GovTech R3L platforms; standardized feedback APIs across agencies; retry-aware form engines.
- Assumptions/dependencies: Interoperable feedback schemas; cybersecurity; policy/legal oversight and transparency.
- Autonomous research and experiment design (academia, industry R&D)
- Use case: Literature and experiment planners that detect flawed experimental steps and retry designs; reinforcement on success metrics (reproducibility, target achievement).
- Potential tools/products/workflows: Lab copilots with R3L planning; hypothesis-testing agents connected to simulators or robotic labs.
- Assumptions/dependencies: Reliable simulators and lab interfaces; reward design that avoids shortcut solutions; expert review loops.
- Strategy backtesting and constraint-aware planning (finance)
- Use case: Trading/optimization agents that reflect on backtest errors or risk/constraint breaches and retry from violating segments; stabilize training with Positive Amplification.
- Potential tools/products/workflows: R3L backtesting assistants; constraint-violation explainers; pivot-focused strategy refinement.
- Assumptions/dependencies: Strong risk controls; prevention of reward hacking/overfitting; compliance review.
- Multi-agent orchestration and tool-use platforms (cross-sector)
- Use case: An “agent OS” that standardizes reflect-then-retry scaffolds across tools (search, code, spreadsheets, APIs), with training that masks shared prefixes and amplifies successful patterns.
- Potential tools/products/workflows: Orchestration SDKs with pivot detection; telemetry standards for language feedback; cross-tool reward aggregation.
- Assumptions/dependencies: Standard feedback interfaces; monitoring/observability for safety; robust sandboxing.
- Scaled adaptive education (education)
- Use case: Systems that learn from large corpora of student step traces, identify the first pivot error, issue targeted hints, and continuously RL-tune to maximize learning gains.
- Potential tools/products/workflows: Adaptive tutors with pivot-hint engines; dashboards that surface preserved correct reasoning; curriculum-aware reward shaping.
- Assumptions/dependencies: Consent and privacy; fairness and efficacy studies; educator oversight.
- Industrial control via digital twins (energy, manufacturing)
- Use case: Supervisory copilots that reflect on alarms/anomalies in digital twins, propose corrective sequences, and validate by retrying in-silico before field deployment.
- Potential tools/products/workflows: Twin-integrated R3L controllers; alarm-to-language feedback bridges; staged rollout pipelines.
- Assumptions/dependencies: Accurate twins and validators; safety certification; clear human-in-the-loop controls.
Cross-cutting assumptions and dependencies
- Language feedback availability: R3L’s exploration benefits depend on accessible, informative textual feedback (error messages, traces, observations). Where absent, instrumentation must expose such feedback.
- Verifiable rewards: Most immediate wins rely on objective success checks; open-ended, subjective tasks need additional research on preference/reward reliability.
- Stability and tuning: Positive Amplification (e.g., α ≈ 3) must be tuned; removing IS/KL constraints assumes amplification and masking prevent entropy drift; monitor Retry Improvement Rate and Reward Gain.
- Model readiness: Smaller models may exhibit cold starts; auxiliary SFT tasks (reflection/retry) and warm-up are necessary.
- Safety, compliance, and privacy: Many applications require audit trails, data governance, and human oversight to meet regulatory and ethical standards.
Glossary
- Advantage function: In reinforcement learning, a value indicating how much better an action (or token) is compared to a baseline, used to weight gradients. "and A_kt denotes the advantage function."
- Agentic Environments: Benchmarks requiring autonomous, multi-step decision-making in interactive settings. "Agentic Environments: ALFWorld (language-only version) \cite{shridhar2020alfworld} for embodied decision-making, WebShop \cite{yao2022webshop} for web navigation, and ScienceWorld \cite{wang2022scienceworld} for long-horizon scientific reasoning."
- Amplification factor: A scalar multiplier applied to positive advantages to make constructive gradients dominate optimization. "A single amplification factor applied uniformly suffices."
- Anchor states: Reference states used to estimate step-level credit without external annotation. "Alternative approaches like GiGPO \cite{feng2025group} and VinePPO \cite{kazemnejad2024vineppo} estimate step-level credit through anchor states or Monte Carlo rollouts."
- Behavior policy: The policy used to sample trajectories during training, potentially lagging behind the current trainable policy. "Given a query , base trajectories are sampled from the behavior policy $\pi_{\theta_{old}$."
- Control variate: A variance reduction technique using a correlated baseline to reduce estimator noise. "Functionally, the shared prefix acts as a control variate, because policy behavior is identical in this region, including it would introduce variance without providing useful signal."
- Contrastive structure: Structural pairing of base and retry trajectories that share prefixes but diverge in suffixes, enabling precise credit assignment. "we introduce Pivotal Credit Assignment that exploits the contrastive structure between base and retry trajectories."
- Credit assignment: Methods for attributing rewards to specific actions or tokens within a trajectory. "Trajectory-level credit assignment applies the same reward signal to all tokens regardless of where errors occur."
- Distillation Trajectories: Corrected trajectories formed by restarting generation from a pivot with guidance, then training without guidance to internalize corrections. "Distillation Trajectories. For each base sample, the model reflects on the trajectory to produce a structured diagnosis..."
- Distributional shifts: Mismatches between training and sampling distributions that can destabilize learning. "While these methods improve trajectory quality, they introduce distributional shifts that can destabilize training if not properly managed \cite{zheng2025prosperity}."
- Entropy collapse: A failure mode where suppressing errors without reinforcing correct actions drives the policy toward high entropy. "We term this entropy collapse and analyze it in Appendix \ref{sec:entropy_collapse}."
- Exploration group: The set of base and distillation trajectories used together for RL optimization. " and form the exploration group for RL optimization"
- Gradient mask: A binary weighting that zeros gradients for shared prefixes to focus updates on diverging suffixes. "We exploit this structure by applying a gradient mask that excludes the shared prefix from updates."
- Group Relative Policy Optimization (GRPO): An RL method computing advantages via group-wise reward normalization without a learned critic. "Group Relative Policy Optimization (GRPO) \cite{shao2024deepseekmath} estimates advantages via group-wise reward normalization"
- Group-wise reward normalization: Computing trajectory advantages by normalizing rewards relative to group statistics. "GRPO \cite{shao2024deepseekmath} estimates advantages via group-wise reward normalization"
- Importance sampling: Reweighting updates using likelihood ratios to correct off-policy divergence. "To manage the resulting off-policy divergence, GRPO employs importance sampling with clipping as follows:"
- Importance sampling ratio: The likelihood ratio between current and behavior policies used for off-policy correction. "where $r_{i,k,t} = \frac{\pi_{\theta}(y_k^t | h_k, y_k^{<t})}{\pi_{\theta_{old}(y_k^t | h_k, y_k^{<t})}$ is the importance sampling ratio for trajectory ."
- KL penalty: A regularization term penalizing deviation from a reference policy via Kullback–Leibler divergence. "The full GRPO objective incorporates a KL penalty to constrain policy updates:"
- KL regularization: Constraining policy updates by referencing a frozen baseline policy using KL divergence. "a frozen reference policy for KL regularization."
- Language-guided exploration: Using natural language feedback (e.g., error messages) to diagnose failures and synthesize improved trajectories. "We propose a language-guided exploration strategy that synthesizes successful trajectories by diagnosing errors and restarting generation from identified failure points with corrective guidance"
- Monte Carlo rollouts: Repeated simulated trajectories used to estimate returns or step-level credit. "estimate step-level credit through anchor states or Monte Carlo rollouts."
- Off-policy data: Trajectories generated under a different policy or guidance than the current training policy. "synthesized off-policy data exacerbates this instability \cite{wu2025learning}."
- Off-policy divergence: The mismatch between behavior and current policies that must be corrected for stable learning. "To manage the resulting off-policy divergence, GRPO employs importance sampling with clipping"
- Pivot turn: The first turn where an issue manifests, used as a restart point for retries. "the pivot turn where the issue first manifested."
- Pivotal Credit Assignment: A method that updates only the diverging suffix after the pivot, excluding the shared prefix from gradients. "With errors diagnosed and localized, Pivotal Credit Assignment updates only the diverging suffix where contrastive signals exist, excluding the shared prefix from gradient update."
- Pivotal mask: A mask that zeroes gradient contributions before the pivot to isolate critical decision points. "Combining the pivotal mask with amplified advantages, the final RL objective is:"
- Policy gradient: The gradient of expected reward with respect to policy parameters, guiding updates in RL. "The policy gradient is derived as:"
- Policy shaping: Adjusting optimization to favor certain trajectories or refinements during training. "Critique-GRPO \cite{zhang2025critique} applies policy shaping only to refinements."
- Positive Amplification: Reweighting that scales up positive advantages so successful signals dominate training. "Positive Amplification upweights successful trajectories to ensure positive signals guide the optimization process."
- Process Reward Models: Models that provide step-level reward signals to supervise intermediate reasoning steps. "Process Reward Models \cite{lightman2023let} offer step-level credit as an alternative"
- Reference policy: A fixed policy used as a baseline for KL regularization and stability. "a frozen reference policy for KL regularization."
- Rejection sampling: Selecting higher-reward samples from a set to improve training signal quality. "Rejection sampling methods like RAFT reach 0.914 on ALFWorld"
- Retry Improvement Rate: The percentage of retry trajectories that improve upon their base attempts. "the Retry Improvement Rate, defined as the percentage of retry trajectories that achieve higher reward than their corresponding base attempts"
- Sequence-level ratios: Importance weights computed over entire sequences to reduce variance relative to token-level weights. "GSPO \cite{zheng2025group} replaces token-level importance weights with sequence-level ratios"
- Sparse rewards: Infrequent reward signals that make exploration and credit assignment difficult. "multi-step agentic environments with sparse rewards"
- Stochastic sampling: Random sampling of trajectories from a policy, often yielding many failures on hard tasks. "Stochastic sampling produces predominantly failed trajectories on difficult problems"
- Supervised fine-tuning (SFT): Auxiliary supervised training used to maintain reflection and retry skills. "where is the auxiliary supervised fine-tuning loss on verified successful corrections"
- Trajectory stitching: Constructing training inputs by pairing original prefixes with corrected suffixes. "both credit assignment and trajectory stitching operate at this turn level."
- Trajectory-level rewards: Rewards applied uniformly to entire trajectories, which can penalize valid prefixes for late errors. "Trajectory-level rewards penalize valid prefixes for later errors"
- Variance reduction: Techniques for lowering gradient variance to improve stability and efficiency. "GSPO improves to 0.857 on ALFWorld through variance reduction"
Collections
Sign up for free to add this paper to one or more collections.