- The paper presents a novel iterative self-training framework using MCTS-based revision trajectories to significantly improve error correction in LLM agents.
- It demonstrates a +5.59% performance boost over baselines by enabling agents to detect and correct errors in real-time, thereby avoiding repetitive error loops.
- The framework’s two-phase approach—model-guided reflection and iterative self-training—offers scalable, dynamic corrections in complex interactive tasks.
Agent-R: Training LLM Agents to Reflect via Iterative Self-Training
Agent-R represents an advancement in the development of LLM-based agents, particularly in addressing error correction challenges in dynamic, interactive environments. By leveraging an iterative self-training framework, Agent-R improves LLMs' ability to self-correct erroneous actions, a capability not sufficiently addressed by traditional methods that rely on behavior cloning from expert trajectories.
Framework and Methodology
Agent-R's framework is divided into two primary phases:
- Phase I: Model-Guided Reflection Trajectory Generation
Agent-R introduces a novel mechanism for constructing training samples through Monte Carlo Tree Search (MCTS), which enables the transformation of erroneous trajectories into corrected ones. This approach involves a dynamic identification and splicing process, where the first error detected within a trajectory is corrected in real-time by aligning it with adjacent, correct paths. This model-guided approach, shown in the framework of Agent-R (Figure 1), contrasts with naive correction strategies by focusing on timely revisions rather than waiting for the culmination of a rollout to address errors.
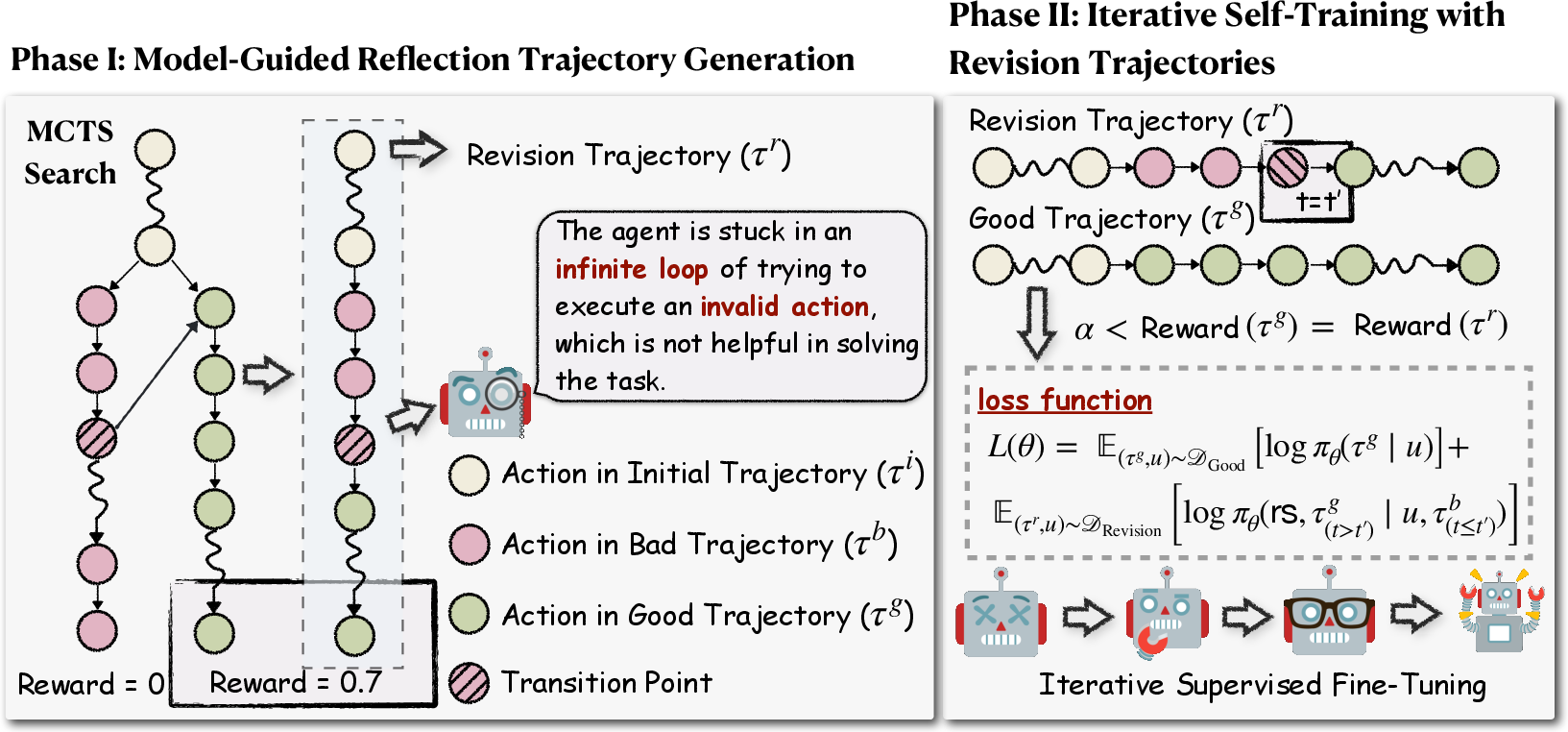
Figure 1: The framework of Agent-R consists of two phases. In Phase I, we adopt MCTS and a model-guided reflection mechanism to construct revision trajectories. In Phase II, the agents are trained using the collected revision trajectories. These two phases can be repeated iteratively. rs is the revision signal, t′ is the transition point between the bad and good trajectories, and L(θ) is the loss function to be optimized.
- Phase II: Iterative Self-Training with Revision Trajectories
In this phase, agents are iteratively trained using the revision trajectories generated through MCTS. This continuous feedback loop allows models to refine their policies progressively, enhancing both error detection and correction capabilities. The iterative nature ensures a scalable enhancement of the agent's reflective abilities, leading to improved decision-making and avoidance of error propagation in complex interactive environments.
Experimental Results
Agent-R has been validated through extensive experiments across three interactive environments, demonstrating its superiority over baseline methods. Key results indicate that Agent-R enables agents to more effectively identify and rectify erroneous actions, avoiding repetitive loops in long trajectories, as depicted in the analysis of repeated action lengths (Figure 2).
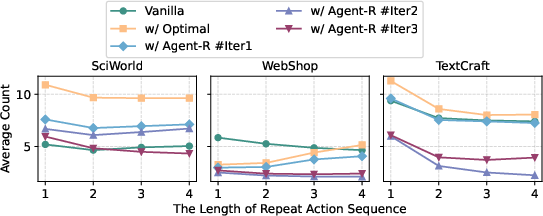
Figure 2: Average count of repeated action lengths for different training trajectories and different iterations in three interactive environments.
Some significant findings include:
- Enhanced Self-Reflection: The model's ability to self-correct and recover from errors improves significantly with training on revision trajectories, leading to superior performance metrics (+5.59% improvement over baselines).
- Avoidance of Error Loops: Agent-R effectively reduces the incidence of agents becoming stuck in action loops, which often hinder recovery in long sequences (Figure 3).
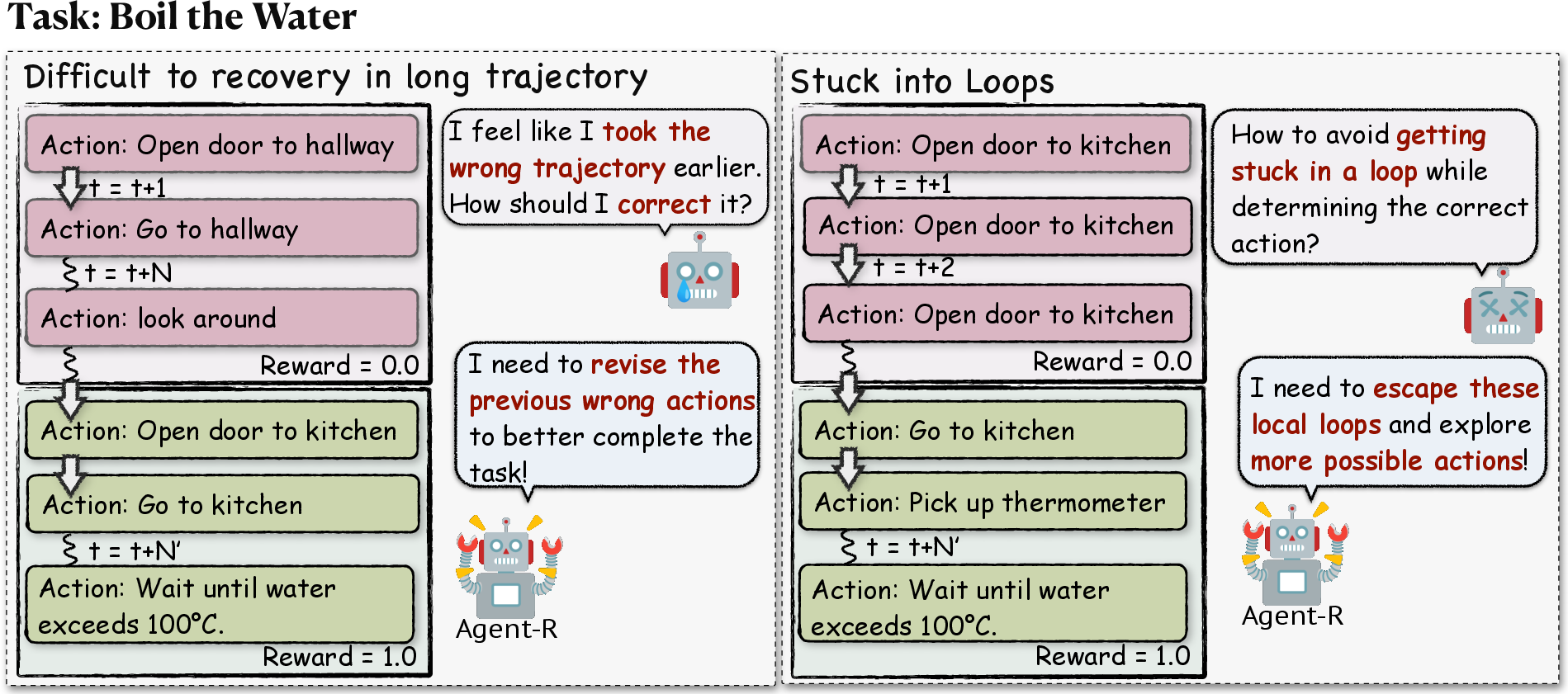
Figure 3: Illustration of language agents struggling with error correction in trajectory generation. These errors can cause agents to enter loops, hindering recovery in long trajectories and resulting in suboptimal outcomes. Agent-R enables agents to effectively detect and address errors in real-time, handling long-horizon tasks and avoiding loops with greater self-reflection capabilities.
Limitations and Future Work
While Agent-R exhibits considerable improvements, it necessitates substantial computational resources due to the iterative training and the complexity of MCTS. Future research could explore optimizations to reduce resource consumption and further enhance scalability. Moreover, integrating Agent-R with other learning paradigms, such as reinforcement learning, may broaden its applicability and efficiency.
Conclusion
Agent-R represents a significant contribution to the field of AI by enhancing the self-correction capabilities of LLM-based agents in interactive environments. This iterative self-training framework allows agents not only to detect and rectify errors dynamically but also to improve decision-making over time through continuous refinement. The outcomes suggest promising directions for future research in developing more adaptive and intelligent autonomous agents.

