KV-Tracker: Real-Time Pose Tracking with Transformers
Abstract: Multi-view 3D geometry networks offer a powerful prior but are prohibitively slow for real-time applications. We propose a novel way to adapt them for online use, enabling real-time 6-DoF pose tracking and online reconstruction of objects and scenes from monocular RGB videos. Our method rapidly selects and manages a set of images as keyframes to map a scene or object via $π3$ with full bidirectional attention. We then cache the global self-attention block's key-value (KV) pairs and use them as the sole scene representation for online tracking. This allows for up to $15\times$ speedup during inference without the fear of drift or catastrophic forgetting. Our caching strategy is model-agnostic and can be applied to other off-the-shelf multi-view networks without retraining. We demonstrate KV-Tracker on both scene-level tracking and the more challenging task of on-the-fly object tracking and reconstruction without depth measurements or object priors. Experiments on the TUM RGB-D, 7-Scenes, Arctic and OnePose datasets show the strong performance of our system while maintaining high frame-rates up to ${\sim}27$ FPS.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces KV-Tracker, a fast system that can figure out where a camera or an object is in 3D space in real time using regular video frames (RGB images). It does this by smartly reusing information from a few important frames, so it doesn’t have to redo heavy calculations every time a new image arrives. The system can track a camera moving in a room and can also track and reconstruct objects on the fly, without needing depth sensors or 3D models of the objects beforehand.
What questions are the researchers asking?
The paper focuses on simple, practical questions:
- How can we use powerful multi-view 3D models—which usually run slowly—quickly enough for real-time use?
- Can we track a camera’s position and orientation smoothly at high frame rates without slowly drifting away from the truth?
- Can we track and build a 3D model of a moving object using only RGB video, without pre-made 3D models or depth data?
How does KV-Tracker work?
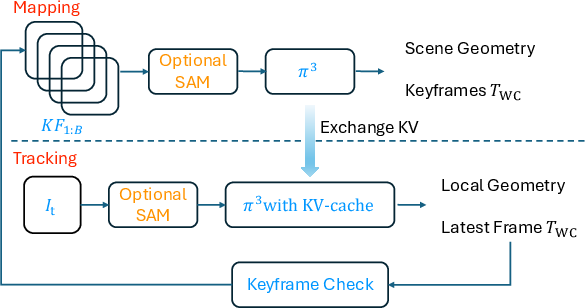
Think of the system as working in two alternating steps: mapping and tracking.
Mapping: picking keyframes and building memory
- The system watches the video and automatically picks a small set of “keyframes” (important snapshots) that show the scene or object from different angles.
- It runs a strong 3D model (called π³, pronounced “pi-cubed”) on these keyframes to build a global understanding.
- Inside this model, there’s an “attention” mechanism (like a smart way to compare and connect information across images). Attention uses three parts: Queries (Q), Keys (K), and Values (V).
- KV-Tracker saves the “Keys” and “Values” from the global attention layers as a compact memory of the scene. This saved set is called the “KV cache.” Think of it like a study guide made from the best pages of a book.
Tracking: fast relocalization using the KV cache
- When a new frame comes in, the system doesn’t recompute everything. It only processes the new frame and then looks up the stored KV cache from the keyframes.
- This is like asking a well-organized librarian (the attention mechanism) to find matches between the new frame (your “question”) and the saved notes (the “keys” and “values”). The librarian does a quick lookup instead of rereading the entire book.
- Because the memory isn’t changed or overwritten every time, it avoids “drift”—slowly getting off course over long sequences.
Why is this faster?
- Multi-view attention normally compares all patches of all frames with all others. That work grows very quickly as you add more frames (like comparing every student in a school with every other student).
- KV-Tracker reduces this by saving the heavy work from the keyframes and only comparing the new frame to that saved memory. This cuts the computation down dramatically.
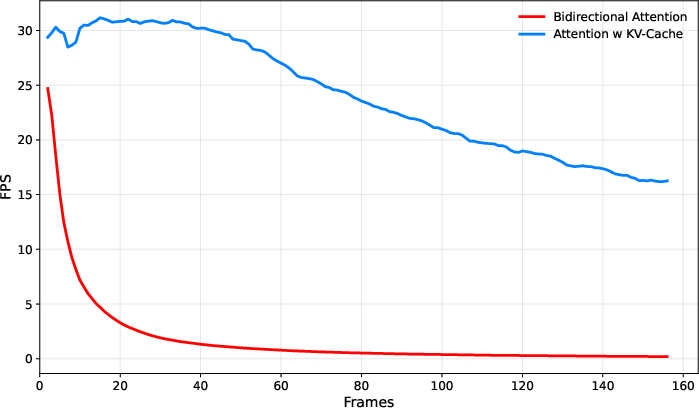
- In tests, this gave up to a 15× speed-up and allowed tracking at around 27 frames per second (FPS).
Object tracking with masks
- For tracking a single object (like a phone or a toy), the system uses segmentation masks to focus only on the object and ignore the background.
- It picks keyframes when the viewpoint changes enough (for example, the camera moves to a new angle), so the object gets covered from many directions.
- With about 50–60 keyframes, the system can build a good online 3D reconstruction of an object while keeping tracking fast.
What did they find, and why is it important?
Here are the main takeaways:
- Speed: KV-Tracker reaches up to ~27 FPS in tracking, which is fast enough for real-time applications.
- Accuracy: On indoor camera-tracking benchmarks (TUM RGB-D and 7-Scenes), KV-Tracker consistently beat other streaming methods that update their memory every frame. It also performed competitively with a strong traditional odometry method (DPVO), even though KV-Tracker provides dense geometry when needed.
- Object tracking: On object datasets (ARCTIC, OnePose, OnePose++), KV-Tracker tracked objects well using only RGB video and segmentation masks. On the harder “low-texture” objects, it often matched or beat methods that rely on offline 3D reconstruction—while still staying real-time.
- No retraining needed: KV-Tracker works “training-free” with off-the-shelf multi-view models like π³, so it’s easy to plug into existing systems.
Why this matters:
- It makes advanced 3D transformer models practical for live use in AR/VR, robotics, and handheld devices.
- It removes the need for depth sensors or pre-built 3D models of objects, making it more flexible in the real world.
What does this mean for the future?
KV-Tracker shows a simple but powerful idea: save the right information once, and reuse it to make live tracking fast and stable. This can:
- Enable smooth AR experiences that understand both rooms and objects in 3D without special hardware.
- Help robots quickly map small workspaces and track objects they interact with.
- Encourage new designs where “memory” (KV caches) becomes the standard scene representation for real-time 3D systems.
Current limits:
- The memory size grows with the number of keyframes and image resolution, so it’s best for objects or small spaces.
- Future work could compress, prune, or update the cache more cleverly to scale up to larger environments and full SLAM systems.
In short, KV-Tracker turns slow, powerful 3D models into fast, practical tools by saving and reusing what matters most.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to be actionable for future research.
- Scalability beyond small workspaces: No evaluation on large-scale scenes (e.g., building-sized SLAM with hundreds to thousands of keyframes) or long trajectories with repeated revisits; how does the KV-cache behave in truly large-scale mapping and re-localization?
- Memory footprint characterization: The paper states cache memory grows linearly with keyframes and resolution and hits a 24GB limit, but does not quantify per-keyframe memory, per-patch memory, or give formulas/empirical curves to guide cache sizing and compression.
- Incremental KV-cache updates: New keyframes trigger a full KV-cache recomputation; there is no method/benchmark for efficient incremental KV updates, partial recomputation, or online cache maintenance policies (e.g., streaming append, lazy updates).
- Cache pruning/compression: No concrete techniques are proposed or evaluated for KV-cache pruning, distillation, sparsification, quantization, or product codes to reduce memory and extend scene scale.
- Cache aging and robustness: The impact of stale KV-cache over long time spans, changing illumination, seasonal changes, or object appearance changes is not assessed; how often must the cache be refreshed to maintain accuracy?
- Loop closure and global consistency: The system does not perform loop closure or global optimization (e.g., pose graph or bundle adjustment). How can drift be corrected when revisiting areas or closing loops without corrupting the KV-cache?
- Error recovery and reinitialization: There is no mechanism to detect severe tracking failure and recover (e.g., re-localize from scratch against cache, or switch to a fallback like PnP with explicit correspondences).
- Theoretical grounding of KV-cache as scene representation: The paper motivates KV pairs as an implicit scene memory but does not provide formal analysis (e.g., invariance properties, coverage guarantees, or what geometric/appearance content is retained or lost).
- Complexity analysis clarity: The attention complexity derivation and equation formatting contain errors/typos; a precise derivation for bidirectional global attention vs. cached cross-attention (e.g., O(|Q|·|K|) with |Q|=M and |K|=NM) should be corrected and verified across different patch sizes and heads.
- Model-agnostic claim: The approach is only demonstrated on π3; applicability to VGGT, MapAnything, and other multi-view transformers (with different attention implementations, FlashAttention, register tokens, or architectural variations) is not empirically validated.
- Register tokens inconsistency: π3 is said to drop special camera register tokens, yet the experiments claim caching “per frame register tokens.” This contradiction must be resolved and the exact tokens included in the cache clearly specified for reproducibility.
- Decoder head toggling: During tracking, point-map and confidence heads are turned off, with the claim that tracking quality is unaffected; a controlled ablation quantifying the impact on pose accuracy and stability is missing.
- Scale ambiguity and calibration: Trajectories are aligned via Sim(3) for scene tracking, but object tracking reports centimeter-level thresholds without clarifying how absolute scale is obtained in the absence of intrinsics/depth; sensitivity to intrinsics, focal length, and pixel scaling is not analyzed.
- Evaluation protocol clarity for object pose: It is unclear whether ARCTIC experiments measure object or camera pose, how coordinate frames are defined, and whether scale alignment or frame transforms are applied; a formal, reproducible protocol is needed.
- Segmentation dependency: Object tracking relies on SAM 2 masks and blacked-out backgrounds, yet π3 was not trained on masked inputs. There is no ablation on segmentation accuracy, mask leakage, temporal mask failure, or the benefit of context (vs. black background).
- Bounding box vs. mask trade-offs: The paper observes better performance with dilated 2D boxes than with masks but does not systematically study dilation size, context width, or failure modes (e.g., background clutter near object boundaries).
- Non-rigid and articulated objects: The method is tested on rigid objects; robustness to articulation, deformation, and topology changes (e.g., opening/closing doors, folding) remains unexplored.
- Dynamic scenes and occlusions: No experiments assess robustness to moving backgrounds, significant occlusions, or partial visibility; how should the cache be updated or queried when large portions of the scene/object are temporarily occluded?
- Long-term operations: The system does not address persistent mapping across sessions (saving/loading KV-cache to disk, cross-device portability, or temporal consistency across days/weeks).
- Multi-object tracking: Handling multiple simultaneous objects (separate caches, memory scheduling, mutual occlusion, segmentation ambiguities, and cache interaction) is not addressed.
- Keyframe selection policy: Angular-threshold keyframing lacks sensitivity analysis and adaptivity; how should thresholds be tuned, and can uncertainty-aware or coverage-aware policies improve reconstruction and tracking?
- Keyframe rejection/pruning: The confidence-based keyframe rejection strategy is briefly mentioned without quantitative criteria, ablation, or impact analysis on tracking stability and reconstruction completeness.
- Cache poisoning vs. adaptability: Freezing the KV-cache avoids “poisoning,” but also limits adaptation to new observations; designing safe, data-driven cache updates that preserve global consistency is left open.
- Fairness and comparability of baselines: Object-level baselines use offline reconstructions and different hardware; more controlled, matched setups (same GPU, resolution, segmentation/no-segmentation conditions) are needed to isolate algorithmic gains.
- Broader benchmarks: Evaluation is limited to indoor scenes and curated object datasets; outdoor scenes, adverse weather, strong specularities, repeated patterns, and low-light scenarios are not tested.
- Real-time feasibility on commodity/mobile hardware: Results are reported on an RTX 4090; measurements on laptops, embedded GPUs, or AR devices—with end-to-end latency including segmentation—are needed to validate practical deployment.
- Energy and compute profiling: There is no analysis of GPU utilization, memory bandwidth, energy per frame, or throughput under varying cache sizes/heads; such profiling would guide design choices for real-time systems.
- Uncertainty calibration: Confidence maps are available but turned off during tracking; how can uncertainty estimates be exploited for robust keyframing, cache pruning, and downstream pose-graph optimization?
- Cache structure and indexing: The cache is treated as a flat KV store; exploring structured memory (e.g., per-view, per-region, spatial hashing, block-sparse indexing) to accelerate queries and reduce memory is an open direction.
- Interaction with explicit geometry: The method does not combine cached KV with explicit geometric optimization (e.g., local BA, pose graph), which could provide drift correction and accuracy improvements; hybrid designs are unexplored.
- Robustness to camera artifacts: No analysis of motion blur, rolling shutter, lens distortion, or sensor noise; the impact on KV-cache attention and tracking accuracy is unknown.
- Reproducibility details: Implementation specifics for intercepting KV tensors in modern attention frameworks (FlashAttention, fused kernels), memory layout, and exact layers cached are not documented; a reference implementation or API for cache extraction/injection would aid adoption.
- Upper bound on object keyframes: The claim that “50–60 keyframes are sufficient” is anecdotal; a principled method to determine the necessary number of keyframes for a given object complexity and required accuracy is missing.
Practical Applications
Practical Applications of KV-Tracker
Below are actionable, real-world applications derived from KV-Tracker’s findings and methods. Each item includes the sector(s), examples of tools/products/workflows, and key assumptions/dependencies that impact feasibility.
Immediate Applications
These can be deployed today in constrained settings (small objects/workspaces, single monocular RGB camera, sufficient GPU).
- bold Object-level 6-DoF tracking without CAD models
- Sectors: robotics, AR/VR, manufacturing, retail
- Tools/workflows:
- Monocular pick-and-place tracker for unknown objects on cobots
- AR object anchors for demos, training, and in-store retail experiences
- On-the-fly object pose feedback during manual assembly
- Assumptions/dependencies: segmentation masks (e.g., SAM2) or 2D boxes; RTX-class GPU for ~16–27 FPS; objects small enough to be fully mapped with 50–70 keyframes; scale ambiguity for metric output unless externally calibrated
- bold On-set VFX camera/object tracking without markers
- Sectors: media/film, virtual production
- Tools/workflows:
- Real-time camera re-localization for handheld monocular shots in small sets
- Online object reconstruction for match-moving
- Assumptions/dependencies: small scenes; stable lighting; GPU availability on cart/edge box; integration with Unreal/Unity pipelines; occasional cache refresh when adding keyframes
- bold AR try-on and product visualization for small items
- Sectors: e-commerce, retail, marketing
- Tools/workflows:
- Phone-based scanning and pose tracking of accessories, footwear, small appliances for interactive product demos
- Web/SDK-based 3D previews using online recon output fused over keyframes
- Assumptions/dependencies: adequate texture; good mask propagation; limited scene scale; device-class acceleration (desktop/server side more practical today)
- bold Industrial workcell monitoring and alignment
- Sectors: manufacturing, QA/QC
- Tools/workflows:
- Real-time tracking of tools/fixtures to verify positioning without markers or depth
- Quick object re-localization after changeovers using cached KV map
- Assumptions/dependencies: controlled lighting; pre-scanned object keyframes; near-field camera placement; safety/compliance for cameras in the cell
- bold Warehouse/bin-picking perception bootstrap
- Sectors: logistics, robotics
- Tools/workflows:
- Online reconstruction and pose tracking to initialize grasp planners for unknown SKUs
- Rapid object re-localization across frames during manipulation
- Assumptions/dependencies: single-object focus; segmentation reliability; potential need to fuse with depth for final grasp planning
- bold Indoor micro-drone and ground robot navigation in confined spaces
- Sectors: robotics, inspection
- Tools/workflows:
- Monocular camera tracking in GPS-denied, small, structured environments (e.g., equipment rooms)
- KV-cache refresh when viewpoint changes significantly
- Assumptions/dependencies: small workspace; moderate motion blur; offboard compute or high-performance onboard GPU; scale ambiguity unless calibrated
- bold Cultural heritage object digitization “lite”
- Sectors: museums, archives, education
- Tools/workflows:
- Rapid, online 3D reconstruction and pose tracking for small artifacts with a handheld camera
- Immediate feedback during scanning to ensure coverage
- Assumptions/dependencies: small objects; masking viable; non-destructive imaging policy compliance; post-hoc scale setting if needed
- bold Academic eval and prototyping for streaming multi-view models
- Sectors: academia, software tools
- Tools/workflows:
- Model-agnostic KV-cache adaptor to make multi-view transformer backbones usable on video streams without retraining
- Benchmarking workflows for streaming inference vs. offline N2 attention
- Assumptions/dependencies: availability of pi3/VGGT-like backbones with global SA; sufficient VRAM to cache per-keyframe K/V at chosen resolution
- bold Low-cost AR measurement and DIY guidance
- Sectors: daily life, education
- Tools/workflows:
- Smartphone-assisted pose tracking for assembling furniture, tool alignment, and measurement of small items
- Overlayed step-by-step guidance anchored on the object
- Assumptions/dependencies: runs server-side or on high-end devices; needs segmentation; limited to tabletop-scale
- bold Edge-cost reduction by removing depth/CAD requirements
- Sectors: policy, procurement, operations
- Tools/workflows:
- Replace depth sensors or CAD-model pipelines with monocular tracking + segmentation in small-space applications
- Assumptions/dependencies: performance degrades on large scenes; may still need depth for metrology-grade precision
Long-Term Applications
These require further research in cache pruning/compression, incremental KV updates, larger-scene scaling, multi-object handling, or embedded optimization.
- bold Room- to building-scale dense SLAM with KV-state
- Sectors: AR cloud, facilities management, construction
- Tools/products:
- Persistent spatial anchors and dense maps across large indoor spaces
- “KV-SLAM” frameworks with loop-closure via cache management
- Dependencies: scalable memory (hierarchical caches), drift control, loop closure strategies, multi-session mapping
- bold Markerless surgical/navigation AR
- Sectors: healthcare
- Tools/products:
- Real-time instrument tracking and organ/phantom surface reconstruction from monocular endoscopes or operating room cameras
- Dependencies: strict robustness, medical-grade validation, tissue deformation handling, potentially multimodal fusion with ultrasound/CT
- bold Autonomous driving and mobile robotics at scale
- Sectors: mobility, transportation, drones
- Tools/products:
- Online reconstruction and pose tracking in semi-structured outdoor environments with dynamic objects
- Dependencies: high-speed motion, illumination/weather variability, efficient cache pruning, multi-camera synchronization, real-time constraints on embedded hardware
- bold Digital twins with live object updates
- Sectors: manufacturing, smart buildings, energy
- Tools/products:
- Continual online reconstruction of moving assets (valves, gauges, tools) and re-localization within broader twin models
- Dependencies: integration with existing BIM/PLM; multi-object segmentation and tracking; scalable cache/sharding across edge nodes
- bold Retail checkout and inventory automation without depth
- Sectors: retail, logistics
- Tools/products:
- Item-level pose tracking and verification at stations/scan tunnels using monocular RGB
- Dependencies: occlusions, multi-item scenes, throughput demands; need for robust multi-object KV caches and fast segmentation
- bold Home robots with on-the-fly object models
- Sectors: consumer robotics
- Tools/products:
- Assistive robots building transient object models and tracking them during tasks (e.g., tidying, cooking assistance)
- Dependencies: efficient on-device inference, clutter robustness, dynamic interaction, failure recovery policies
- bold Industrial metrology-lite and automated inspection
- Sectors: manufacturing, aerospace
- Tools/products:
- Rapid, camera-only alignment checks (fit-up verification, orientation checks) with greater precision via improved geometry heads and scale observability
- Dependencies: metric scale estimation (e.g., fiducials, learned scale), tolerancing; traceability requirements
- bold Security/surveillance re-localization and forensics
- Sectors: security, public safety
- Tools/products:
- Cross-view object/camera re-localization in multi-camera networks using cached scene representations
- Dependencies: privacy policy considerations; cross-camera calibration; cache sharing across endpoints
- bold Education and AR labs
- Sectors: education
- Tools/products:
- Interactive lab kits where students build small 3D reconstructions and analyze motion/pose with monocular webcams
- Dependencies: simplified tools, web-first runtimes, classroom-grade hardware
- bold Foundation-model acceleration via KV-caching
- Sectors: software, AI infrastructure
- Tools/products:
- Training-free acceleration layer for multi-view transformer backbones in streaming apps (robotics stacks, AR SDKs, digital twin engines)
- Dependencies: standardized global-attention blocks; cache serialization formats; incremental KV update algorithms
- bold Policy and standards for monocular 3D capture
- Sectors: policy, standards bodies
- Tools/products:
- Guidelines for privacy-preserving scanning, data retention, and accuracy reporting for monocular reconstruction in public/enterprise spaces
- Dependencies: stakeholder engagement; validation benchmarks and certification processes
Common Assumptions and Dependencies Across Applications
- Hardware: current real-time rates (up to ~27 FPS) reported on high-end GPUs (e.g., RTX 4090); embedded/mobile deployment needs optimization.
- Scene scale: best suited to small objects or confined spaces due to KV memory growth with keyframes and image resolution.
- Inputs: monocular RGB; optional segmentation masks (SAM2) significantly aid object-level tracking; background masking improves robustness.
- Scale ambiguity: monocular outputs are up-to-scale; metric use cases need external scale (e.g., known object size, fiducials, stereo/depth fusion).
- Model backbone: relies on availability of multi-view transformer with global self-attention (e.g., pi3, VGGT-like) and compatibility with KV caching; no retraining required but performance depends on pretrained priors.
- Workflows: keyframing policy and cache refresh frequency affect performance; careful threshold tuning and cache management are needed for stability.
Glossary
- 6-DoF: Six degrees of freedom for rigid body pose (3D translation and rotation). "We propose a novel way to adapt them for online use, enabling real-time 6-DoF pose tracking and online reconstruction of objects and scenes from monocular RGB videos."
- Absolute Trajectory Error (ATE) RMSE: Root-mean-square error of the estimated trajectory against ground truth positions. "Absolute Trajectory Error (ATE) RMSE in meters on TUM-RGBD dataset."
- All-to-all self-attention: Attention where every token can attend to every other token across frames. "Fast3R operated on multi-view information with global all-to-all self-attention between frames"
- Azimuth: Horizontal rotation angle around the vertical axis. " and represent the camera's azimuth and elevation angles"
- Bidirectional attention: Attention allowing mutual information flow among tokens in both directions. "map a scene or object via ~\cite{wang2025pi3} with full bidirectional attention."
- CAD model: A precise 3D digital model used as a prior for object pose and shape. "Having a CAD model is a strong assumption that can be limiting in different applications."
- Camera intrinsics: Internal calibration parameters of a camera (e.g., focal length, principal point). "added optional input modalities as conditioning, such as depth and camera intrinsics"
- Camera register token: Special transformer token that encodes camera-related information. "~\cite{wang2025pi3} adopted VGGT's network architecture but reformulated the scene geometry output to local point maps instead of global point maps, dropped the special camera register tokens"
- Catastrophic forgetting: Sudden loss of previously learned knowledge when updating a model online. "This allows for up to speedup during inference without the fear of drift or catastrophic forgetting."
- Confidence map: Per-pixel scores indicating reliability of predicted 3D points. "Since decodes the estimated camera, poses local point maps and confidence maps with 3 independent decoders"
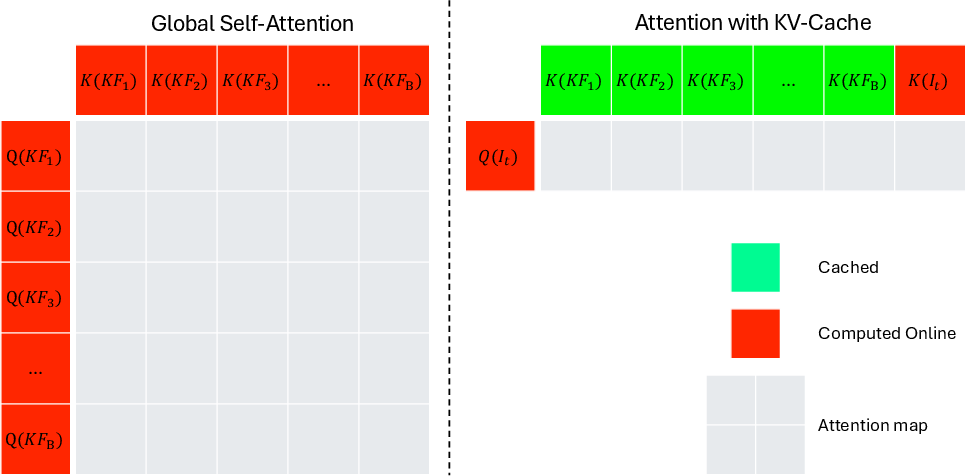
- Cross-attention: Attention where query tokens attend to separate key/value tokens (e.g., from memory). "Visualisation of the full bidirectional global self-attention used during mapping to generate the KV-cache (left) vs. cross-attention with KV-cache + self-attention used for tracking of live frames (right)."
- Decoder heads: Separate output modules producing different predictions (e.g., pose, points, confidence). "Finally, decoding heads are used to predict the final outputs"
- Decoder-only transformer: A transformer architecture composed solely of decoder layers. " is feed-forward decoder only transformer based model."
- Drift: Accumulated pose error over time causing deviation from true trajectory. "While locally the output might be consistent, globally these methods suffer from drift and lack the ability to ``close the loop''"
- Elevation: Vertical rotation angle relative to the horizon. " and represent the camera's azimuth and elevation angles"
- Feed-forward geometry network: Model that predicts 3D geometry in a single pass without iterative optimization. "A novel application of multi-view feed-forward geometry networks to real-time object and scene tracking."
- Frame-wise self-attention: Self-attention applied independently within each frame’s tokens. "alternating between frame-wise self-attention layers and global self-attention layers."
- Global self-attention: Self-attention across tokens from all input frames jointly. "alternating between frame-wise self-attention layers and global self-attention layers."
- Keyframe: Selected frame used to anchor mapping and memory for tracking. "Our method rapidly selects and manages a set of images as keyframes"
- Key-value (KV) pairs: Stored attention keys and values representing features for reuse. "We then cache the global self-attention block's key-value (KV) pairs and use them as the sole scene representation for online tracking."
- KV-cache: Memory of cached key-value pairs used to accelerate attention during tracking. "During the mapping stage a set of keyframes are used to generate a KV-cache."
- Latent memory: Hidden state storing scene information updated over time. "MUSt3R~\cite{cabon2025must3r} uses a latent memory that gets updated with sufficient viewpoint change in the online setting."
- Monocular RGB: Single-camera color video without depth. "online reconstruction of objects and scenes from monocular RGB videos."
- Multi-view networks: Models that take multiple images simultaneously to infer consistent 3D geometry. "In all these multi-view networks, information sharing happens between the multi-views via global all-to-all self-attention"
- Odometry: Estimation of egomotion (camera movement) from sensor data over time. "Since it is a sparse-patch odometry system we do not consider it as a baseline since it lacks dense geometry prediction."
- Permutation-invariant loss: Training objective insensitive to input order. "trained a model with a permutation-invariant loss, so the model is less sensitive to the reference view choice."
- Point map: Per-pixel 3D points predicted in a camera or world frame. "point maps in the local camera frames "
- Pose graph: Graph of poses connected by constraints, optimized to improve trajectory. "An object pose graph was built and solved online, recovering the poses of keyframes and using them for tracking."
- PnP (Perspective-n-Point): Algorithm estimating camera pose from 2D–3D correspondences. "They also trained 2D-3D matching networks through which they solve PnP and recover the object pose."
- Relocalisation: Re-estimating pose by matching to previously built representation. "re-localising the current observation against the saved KV representation without altering it"
- RGB-D: Color image plus depth channel. "Absolute Trajectory Error (ATE) RMSE in meters on TUM-RGBD dataset."
- Scaled Dot-Product Attention: Core transformer attention mechanism using scaled query–key dot products. "The model uses Scaled Dot-Product Attention \cite{vaswani2017attention} for the frame-wise and global self-attention blocks."
- SE(3): Special Euclidean group for 3D rigid body transformations. ""
- Sim(3): Similarity transformations (rotation, translation, uniform scale). "we align all the estimated trajectories to the ground truth trajectories with a alignment using Umeyama Algorithm"
- SLAM: Simultaneous Localization and Mapping for estimating pose while building a map. "Traditional SLAM and reconstruction methods can be broadly categorized by their tracking strategy."
- Umeyama Algorithm: Method for similarity transform alignment between point sets. "we align all the estimated trajectories to the ground truth trajectories with a alignment using Umeyama Algorithm"
- ViT backbone: Vision Transformer encoder used to produce patch tokens. "encoded via a ViT backbone to produce a set of tokens"
Collections
Sign up for free to add this paper to one or more collections.