Do You Have Freestyle? Expressive Humanoid Locomotion via Audio Control
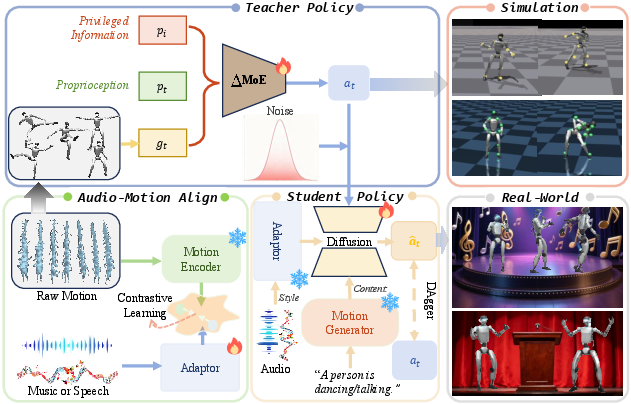
Abstract: Humans intuitively move to sound, but current humanoid robots lack expressive improvisational capabilities, confined to predefined motions or sparse commands. Generating motion from audio and then retargeting it to robots relies on explicit motion reconstruction, leading to cascaded errors, high latency, and disjointed acoustic-actuation mapping. We propose RoboPerform, the first unified audio-to-locomotion framework that can directly generate music-driven dance and speech-driven co-speech gestures from audio. Guided by the core principle of "motion = content + style", the framework treats audio as implicit style signals and eliminates the need for explicit motion reconstruction. RoboPerform integrates a ResMoE teacher policy for adapting to diverse motion patterns and a diffusion-based student policy for audio style injection. This retargeting-free design ensures low latency and high fidelity. Experimental validation shows that RoboPerform achieves promising results in physical plausibility and audio alignment, successfully transforming robots into responsive performers capable of reacting to audio.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces RoboPerform, a way for humanoid robots to move expressively in sync with sound. Instead of telling a robot exactly which poses to copy, RoboPerform lets a robot “feel” music or speech and respond with dance moves or hand/arm gestures that match the rhythm and energy of the audio—almost like freestyle.
What questions did the researchers ask?
- Can a robot move directly from audio—like music or speech—without first copying a human’s motion?
- Can those movements be both safe and realistic for a real robot body?
- Can the robot’s timing match the beat of music or the rhythm of speech?
- Can this work fast enough for real-time performance?
How did they do it? (Methods explained simply)
The team designed a system that treats motion like a combination of two parts: content and style.
The big idea: motion = content + style
- Content = the “what.” For example: “dance” or “give a speech with gestures.” This sets the basic type of movement.
- Style = the “how.” The audio (music or speech) adds rhythm, speed, emphasis, and energy so the robot moves in sync with beats and speech prosody.
Think of it like a sentence: the content is the words, and the audio is the tone and rhythm that change how it feels.
Teaching the robot: a coach and a learner
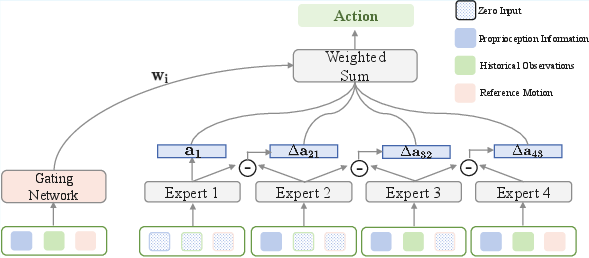
- Teacher policy (coach): A strong controller called ΔMoE (Delta Mixture-of-Experts). Imagine a team of specialists—each one focuses on a different “piece” of the control problem. A gating system combines their advice so the robot stays balanced and moves well.
- Student policy (learner): A faster, lighter model that learns from the teacher. It uses a “diffusion” process (like sharpening a blurry photo step by step) to produce smooth, safe joint actions for the robot.
Understanding sounds: audio–motion alignment
To make audio useful for movement, they train an “adaptor” that learns how audio patterns (beats, rises, pauses) match motion patterns. You can think of it like a matching game: given a piece of audio and a matching motion, the adaptor learns to bring those two closer together in a shared space so the robot can translate sounds into movement cues.
Making smooth moves: diffusion policy
The student policy is a diffusion model:
- It starts with a rough action plan.
- It gradually “denoises” it into a smooth, safe motion.
- It always keeps two guides in mind:
- the content latent (what to do: dance or gesture),
- the audio latent (how to do it: fast, slow, punchy, soft), injected layer by layer so timing stays aligned with the sound.
Why skipping “retargeting” helps
Many older systems first generate a human animation from audio and then “retarget” it to a robot’s body. That often:
- stacks up errors,
- adds delay,
- and loses fine timing details. RoboPerform skips that. It generates robot actions directly from audio and content, reducing errors and latency and keeping the beat.
What did they find?
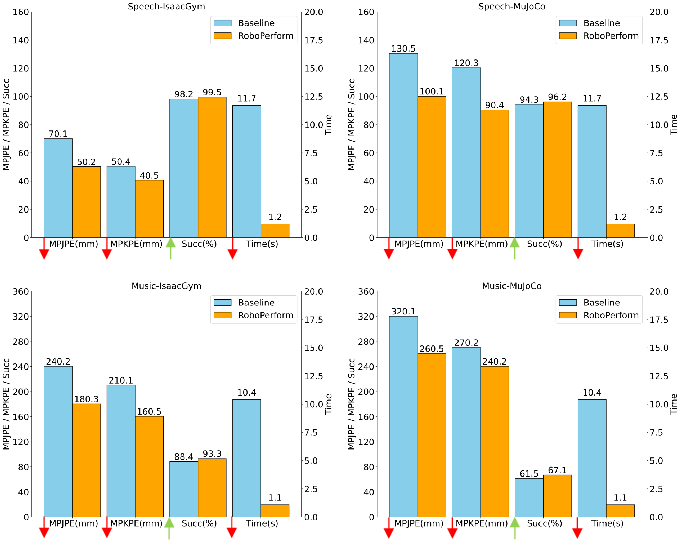
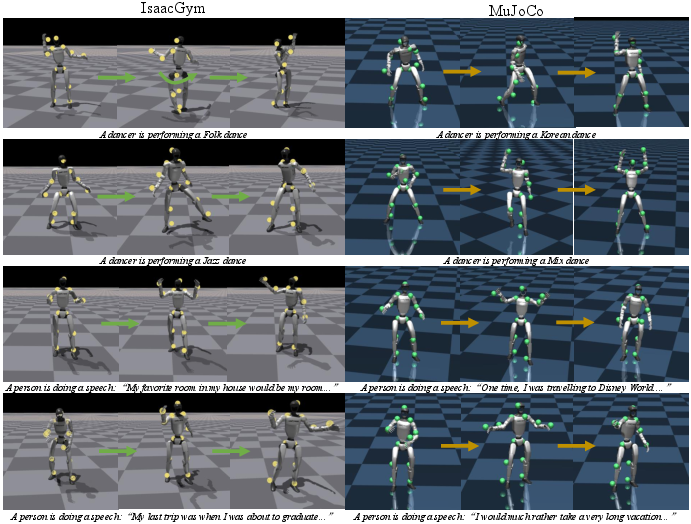
In tests with two datasets (music and speech) and on a real humanoid robot (Unitree G1), RoboPerform:
- Produced movements that matched beats and speech rhythm better than baselines.
- Stayed physically plausible and stable, with low joint/keypoint errors in simulators (IsaacGym and MuJoCo).
- Ran with lower latency because it avoided slow “retargeting” steps.
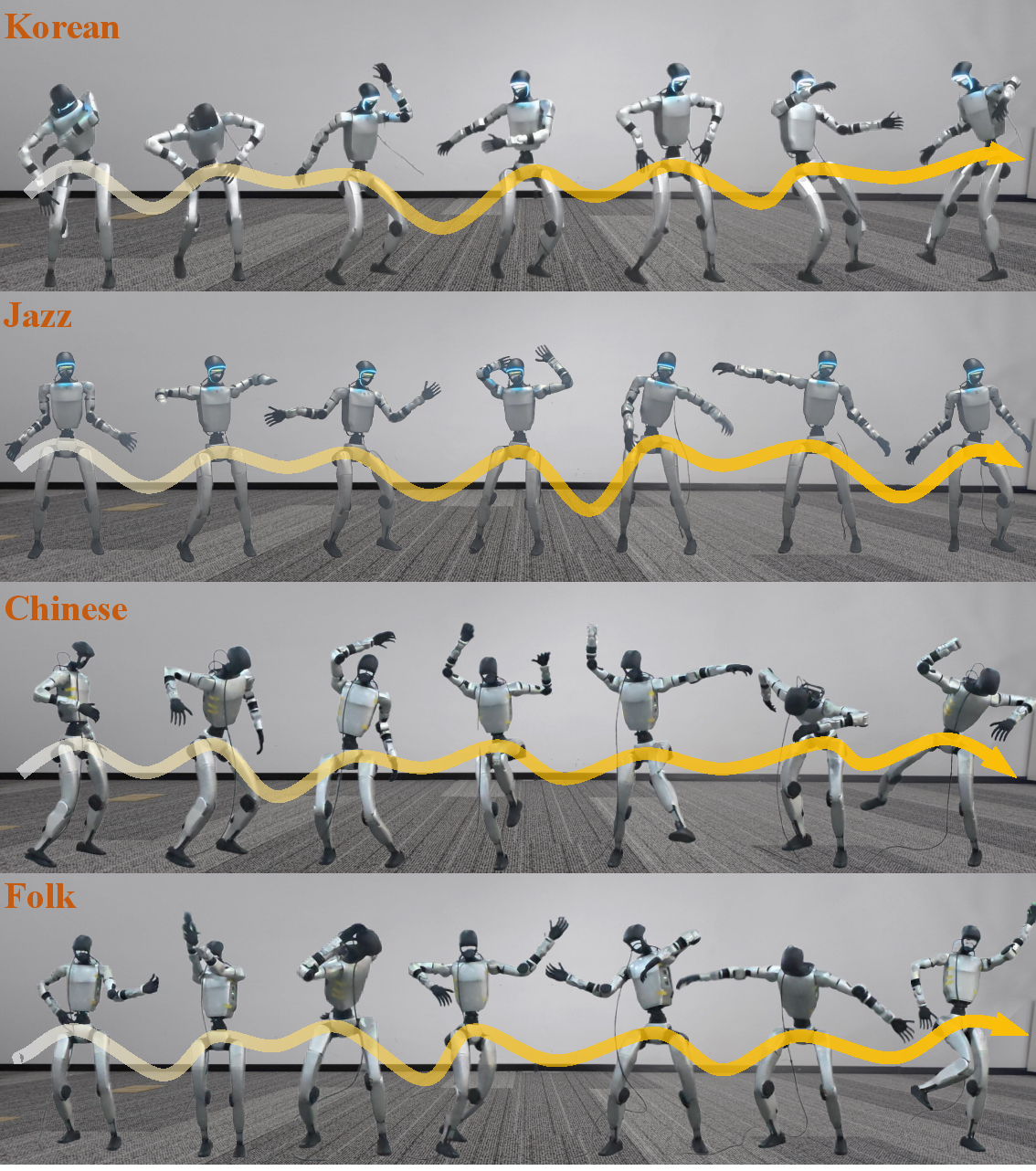
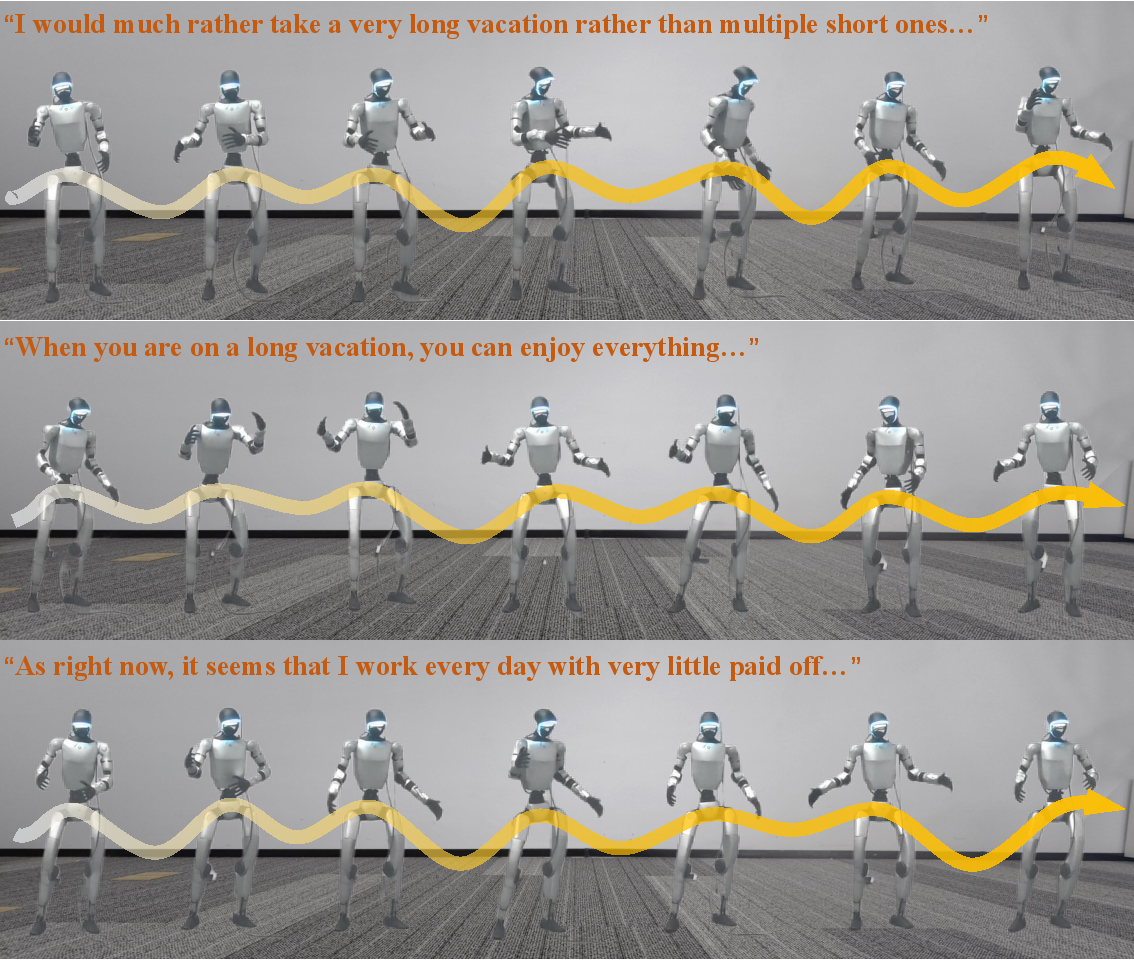
- Worked for both music-driven dance and speech-driven gestures.
- Transferred from simulation to a real robot, showing freestyle dancing and presenter-like gesturing.
They also ran careful comparisons:
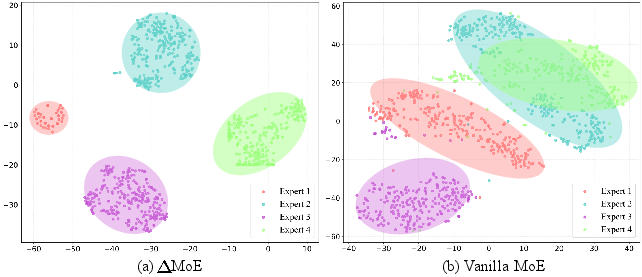
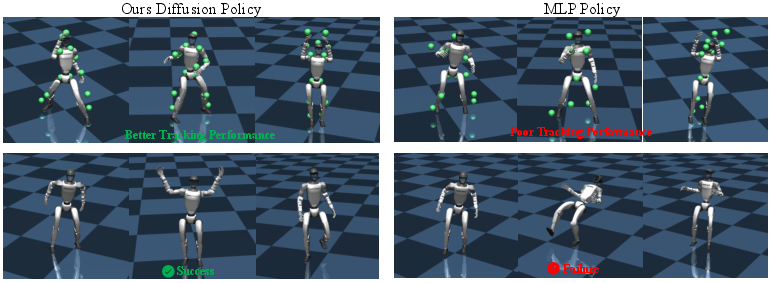
- ΔMoE vs. a standard expert mix: ΔMoE gave more accurate tracking and better specialization (experts add non-overlapping skills like layers in a painting).
- With vs. without content: including the content “what” signal improved accuracy, keeping motions meaningful, not just rhythmic flailing.
- With vs. without the audio adaptor: the adaptor made audio cues much more “kinematic,” improving tracking and beat alignment.
- Audio-driven vs. pose-driven baselines: direct audio control was faster and more reliable than generating human poses then retargeting to the robot.
Why is this important?
- More natural robot performances: Robots can dance to different songs and gesture while speaking, matching timing and energy like humans do.
- Simpler control: Audio is an easy, rich control signal. You can change the music or speech and get a fresh performance—no need to handcraft motion clips.
- Lower latency and fewer errors: Direct audio-to-action reduces complexity, making real-time, responsive performances more practical.
- A foundation for expressive robots: Beyond entertainment, this could help in education, public speaking aids, social robots, and therapy—anywhere timing and expressiveness matter.
In short, RoboPerform shows that robots can “freestyle”: listen, feel the rhythm, and move in sync—safely, smoothly, and in real time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- End-to-end latency and compute footprint are not quantified; report absolute inference times, hardware specs (robot CPU/GPU), memory use, and energy consumption for on-robot deployment versus retargeting baselines.
- Robustness to real-world audio conditions is untested: evaluate performance under background noise, reverberation, microphone placement variability, non-stationary loudness, and abrupt tempo/prosody changes.
- Generalization across music genres, rhythmic structures (syncopation, polyrhythms), and languages/accents is not assessed; design controlled OOD tests for genre, tempo ranges, meter, and multilingual prosody.
- Audio-motion alignment metrics focus on retrieval; add direct synchronization measures (beat hit rate, beat-phase error, cross-correlation of motion energy to audio envelope, dynamic time warping alignment, prosody-gesture correlation) and report them in the main results.
- Co-speech gesture semantic appropriateness is not evaluated; incorporate ASR and semantic parsing to test whether gestures align with lexical content, discourse functions, and communicative intent beyond prosody.
- No human perceptual studies of expressiveness or naturalness; conduct user studies comparing RoboPerform to baselines on perceived synchrony, style, clarity of gestures, and likability/engagement.
- Style controllability is minimal (fixed α in diffusion injection); expose user-facing controls (style intensity, sparsity, energy, smoothness), and test learnable style tokens or continuous style sliders.
- The “content latent” is fixed to generic text (“dancing” / “giving a speech”); study how richer content semantics (e.g., dance genre, choreography constraints, rhetorical structure) affect output, and learn disentangled content/style latents.
- Streaming and long-horizon behavior are not demonstrated; validate online processing on continuous audio streams (no 10s segmentation), with tempo drift handling, buffer management, and latency-bounded causal models.
- Physical metrics are limited (MPJPE/MPKPE, success rate); add contact fidelity (foot slip rate, contact timing vs beat), CoM–support polygon margin, torque/energy consumption, joint limit violations, and fall rates.
- Failure modes and safety are not analyzed; catalog conditions leading to instability, and implement safeguards (e.g., fall recovery, collision avoidance, torque limiting under audio spikes).
- Cross-hardware generalization is unclear; evaluate portability to other humanoids with different morphology/actuation, and provide guidelines to adapt policies without retargeting.
- ΔMoE subspace design is under-specified; clarify what conditional dimensions c1–c3 represent, test more experts, alternative partitions, and gating calibration; provide formal analysis or empirical evidence of the claimed CFG generalization.
- Audio adaptor choices are narrow; compare adaptor architectures (CNN/TCN/transformers), explicit beat/prosody detectors vs learned alignment, InfoNCE temperature schedules, negative sampling strategies (speaker/genre negatives), and ablate adaptor capacity.
- Training/sample efficiency and compute cost are not reported; quantify PPO/DAgger steps, wall-clock training time, datasets per task, and sensitivity to data size (especially for dance vs gesture).
- Dataset biases and segmentation effects are unaddressed; analyze how 10-second clipping affects continuity and expressiveness, and evaluate on longer sequences with transitions between styles/speakers/songs.
- Baseline comparisons are limited; include stronger state-of-the-art pipelines (e.g., recent audio-to-motion + advanced retargeting controllers), and ensure fair latency and fidelity comparisons with matched hardware and optimization.
- Beat tracking and prosody extraction are implicit; assess whether explicit beat/tempo detectors or pitch/energy contours improve synchronization versus latent-only alignment, and whether hybrid supervision helps.
- No quantitative real-world evaluation; provide on-robot metrics (task success, synchronization errors, contact slip, energy) and error bars across multiple trials and environments.
- Gesture granularity (hands/fingers) and expressivity constraints are not discussed; evaluate fine hand articulation, pointing, deictic gestures, and constraints like avoiding self-collisions or violating social norms.
- Adaptation to mixed audio (simultaneous speech and music) is unexplored; test multi-source audio separation and control fusion for scenarios like speaking over background music.
- Policy interpretability is limited; analyze how audio features modulate actions layer-wise in diffusion (e.g., feature attribution, latent traversals), and visualize gating weights in ΔMoE across conditions.
- Robustness to out-of-distribution motion latents is unclear; test different content generators, domain shifts in motion VAE, and the impact on style injection and physical plausibility.
- Ethical/social considerations are absent; discuss risks of persuasive/affective robotic behaviors, biases in gesture/dance styles, and guidelines for responsible deployment in human-facing settings.
Practical Applications
Below is a concise synthesis of practical, real-world applications that follow from the paper’s findings and innovations. Each item is categorized as either an Immediate Application (deployable now) or a Long-Term Application (requiring further research, scaling, or development). Where relevant, we indicate sectors, potential tools/products/workflows, and assumptions or dependencies that may affect feasibility.
Immediate Applications
- Entertainment and live events (Sector: robotics, entertainment)
- Use case: Humanoid performers that freestyle-dance to music and act as stage hosts with co-speech gestures synced to mic or playback audio.
- Tools/products/workflows:
roboperform_node(ROS2 integration), a “Show Control” pipeline connecting audio-in (mic or DAW) to the diffusion student policy, pre-set content latents like “dancer” or “presenter,” two-step DDIM sampling for real-time. - Assumptions/dependencies: Compatible humanoid (e.g., Unitree G1 or similar), adequate compute for on-device inference, licensed audio, stage safety procedures, controlled lighting/surface conditions.
- Retail and marketing installations (Sector: retail, advertising, robotics)
- Use case: Storefront or booth humanoids reacting to promotional music/audio, drawing crowd attention with synchronized gestures/dance.
- Tools/products/workflows: Remote scheduling dashboard, playlist-driven choreography (content latent fixed, style from music), safety zoning line and fall-prevention routines.
- Assumptions/dependencies: Reliable power/battery life, staff oversight, brand-safe motion styles, ambient noise management.
- Museum and visitor engagement (Sector: education, culture, service robotics)
- Use case: Gallery guides that gesture to audio narrations or music exhibits, improving clarity and engagement.
- Tools/products/workflows: TTS-prosody integration (
gesture_syncmodule aligning timecodes), content latents for “guide/explainer,” audio adaptor for rhythmic consistency. - Assumptions/dependencies: Clear speech input or high-quality TTS, multilingual support if needed, ADA and public safety compliance.
- Classroom assistants and presenters (Sector: education, edtech, service robotics)
- Use case: Robots that gesture with lectures or announcements (speech-driven co-speech gestures) to aid attention and comprehension.
- Tools/products/workflows: LMS-to-TTS pipeline plus RoboPerform policy, gesture intensity knobs (style injection strength α), classroom mic integration.
- Assumptions/dependencies: Reliable audio capture, teacher controls for gesture appropriateness, school safety policies.
- Telepresence and customer service (Sector: service robotics, CX)
- Use case: Receptionists or telepresence robots that naturally gesture in sync with spoken dialog, improving social cues and perceived empathy.
- Tools/products/workflows: Integration with call-center TTS, latency controls (two-step DDIM), “presenter” content latent for consistent body language.
- Assumptions/dependencies: Privacy-compliant audio handling, noise robustness in public spaces, fallback to minimal-motion mode.
- VTubers/virtual production and game development (Sector: software, media, gaming)
- Use case: Real-time audio-driven motion for virtual humanoid avatars (VTubers, NPCs) without retargeting pipelines.
- Tools/products/workflows: Unity/Unreal plugin (
Audio2Motionavatar component), direct skeleton actuation aligned to audio prosody/beat, content-style disentanglement for genre presets. - Assumptions/dependencies: Engine integration, GPU resources for diffusion, alignment of rig conventions (SMPL-H or custom skeletons).
- HRI research platform (Sector: academia, HCI)
- Use case: Studying audio–motor coupling, engagement effects, and timing fidelity using rhythm hit rate and tracking metrics.
- Tools/products/workflows: Open-source evaluation scripts (R@k, MPJPE/MPKPE, rhythm hit rate), controlled experiments comparing audio-driven vs pose-driven policies.
- Assumptions/dependencies: IRB approval for user studies, standardized audio datasets (BEAT2, FineDance), replicable hardware stack.
- Robotics engineering and prototyping (Sector: robotics, software)
- Use case: Retargeting-free, low-latency control modules for humanoid whole-body action, reducing cascade errors in typical motion pipelines.
- Tools/products/workflows: ROS2 package, IsaacGym-to-real workflow, ΔMoE teacher pretrain + diffusion student deploy, domain randomization presets.
- Assumptions/dependencies: Access to training data for fine-tuning, simulator–to–hardware consistency, reliable sensors and PD controllers.
- Wellness and eldercare engagement (Sector: healthcare, wellness)
- Use case: Light-mobility engagement sessions (gentle dance/gesture to familiar music) to encourage movement and social interaction.
- Tools/products/workflows: Playlist-driven sessions, safety-limited motion envelopes, caregiver control tablet.
- Assumptions/dependencies: Clinical oversight for target populations, conservative motion limits, quiet environments.
- Home assistants and interactive toys (Sector: consumer robotics, toys)
- Use case: Gesture-aware assistants reacting to speech from users or streaming music, and toys that “dance” to songs.
- Tools/products/workflows: Embedded audio pipeline, prosody-aware gesture presets, mobile SOC optimization.
- Assumptions/dependencies: On-device compute constraints, parental controls, safe operation near children and pets.
Long-Term Applications
- Multi-robot choreography and group performance (Sector: entertainment, robotics)
- Use case: Coordinated ensembles of humanoids performing synchronized choreographies to audio.
- Tools/products/workflows: Multi-agent timing protocols, beat-phase alignment across robots, choreographer UI for content/style presets.
- Assumptions/dependencies: Robust multi-agent synchronization, network latency management, advanced collision avoidance.
- Personalized style learning and transfer (Sector: software, HCI, robotics)
- Use case: Robots learn user-specific dance or gesture styles from a small set of audio–motion exemplars.
- Tools/products/workflows: Few-shot adaptation of audio adaptor and student policy, style libraries per user.
- Assumptions/dependencies: Privacy-compliant data collection, continual learning without catastrophic forgetting, cultural sensitivity in motion styles.
- Rich semantic content control beyond dance/gesture (Sector: robotics, education, service)
- Use case: Dynamic content latents generated from complex utterances (e.g., instructions, stories), expanding behaviors (demonstrations, pointing, deictic references).
- Tools/products/workflows: Stronger text-to-motion models integrated with content-style decomposition, LLM-to-motion interfaces.
- Assumptions/dependencies: Improved T2M models with task semantics and constraints, safety-aware policy shaping.
- Robustness to noisy, multi-speaker, or real-world audio (Sector: software, signal processing)
- Use case: Stable performance in crowded environments, overlapping voices, variable tempos.
- Tools/products/workflows: Speech separation and beat tracking modules, adaptive audio quality assessment, confidence-aware motion scaling.
- Assumptions/dependencies: Advanced audio preprocessing, robust prosody/beat extraction, confidence gating to avoid erratic actuation.
- Safety certification and policy frameworks for public-facing robots (Sector: policy, standards)
- Use case: Formal guidelines for dynamic humanoid motions in public spaces (fall risk, collision avoidance, cultural appropriateness).
- Tools/products/workflows: Standardized safety envelopes, compliance checklists, “motion risk rating” tied to tempo/energy.
- Assumptions/dependencies: Engagement with regulators and insurers, third-party validation, incident logging and auditability.
- OEM-grade Prosody-to-Action SDKs (Sector: robotics, OEM, software)
- Use case: Commercial kits bundling audio adaptor, ΔMoE teacher distillation, diffusion student with ROS/RTOS bindings for different humanoid platforms.
- Tools/products/workflows: Hardware abstraction layers, per-robot calibration tools, cloud or edge inference options.
- Assumptions/dependencies: Vendor partnerships, platform-specific tuning, support and maintenance pipelines.
- Clinical and therapeutic applications (Sector: healthcare)
- Use case: Exergames and physiotherapy support with audio-reactive motions to motivate participation; social robots for cognitive stimulation.
- Tools/products/workflows: Clinician dashboards, patient-specific motion limits, safety interlocks, outcome measurement.
- Assumptions/dependencies: Clinical trials, regulatory approvals, integration with EMR/telehealth systems.
- Education and training (Sector: edtech)
- Use case: Choreography teaching tools, music education aids that visualize rhythm via embodied motion, public speaking training with gesture feedback.
- Tools/products/workflows: Curriculum-aligned content latents, interactive lesson plans, analytics on rhythm hit rate and gesture timing.
- Assumptions/dependencies: School procurement and standards, accessibility features, teacher training.
- Cross-morphology expansion beyond humanoids (Sector: robotics)
- Use case: Audio-reactive control for quadrupeds or mobile robots (e.g., rhythmic locomotion or expressive “body language”).
- Tools/products/workflows: Morphology-specific content latents, gait-aware style injection, platform-specific safety envelopes.
- Assumptions/dependencies: New datasets and training regimes, re-parameterized policies for different kinematics.
- Cultural and ethical governance (Sector: policy, ethics)
- Use case: Ensuring gestures/dances are culturally appropriate, mitigating labor displacement in performance art, managing music IP/licensing.
- Tools/products/workflows: Cultural context filters, IP licensing modules, transparency reports on deployment contexts.
- Assumptions/dependencies: Cross-disciplinary oversight, local cultural consultation, legal review of audio use.
- Advanced authoring and “AI stage director” tools (Sector: media, creative tech)
- Use case: End-to-end creative tools to compose audio, select content latents, and preview robot motion performances in simulation before real deployment.
- Tools/products/workflows: Timeline editors coupling audio waveform to style latents, parameterized “energy” and “nuance” controls, simulator-to-stage transfer.
- Assumptions/dependencies: Professional UX, asset management, strong sim-to-real fidelity.
- Integration with generative audio/TTS and LLM agents (Sector: software, AI)
- Use case: Fully autonomous presenter robots: LLM writes script, TTS renders prosody, RoboPerform maps prosody to gesture; music generated on the fly for dance routines.
- Tools/products/workflows: Orchestration layer connecting LLM → TTS → RoboPerform, real-time content-style negotiation, guardrails for safety and appropriateness.
- Assumptions/dependencies: Reliable end-to-end latency, content moderation, failover behaviors when audio confidence drops.
Notes on cross-cutting assumptions and dependencies:
- Data and models: Current performance depends on datasets like BEAT2 and FineDance; broader styles and cultures will require expanded, diverse datasets.
- Hardware and compute: On-device inference with diffusion models and audio adaptors may require GPU or optimized accelerators; battery and thermal constraints apply.
- Audio quality: Beat/prosody extraction performance depends on audio signal quality; preprocessing and confidence gating help.
- Safety and compliance: Public deployments need motion limits, collision avoidance, and event-specific safety plans; adherence to local regulations.
- IP/privacy: Use of commercial music and live speech requires licensing and privacy safeguards; consent and retention policies for captured audio.
Glossary
- AdaLN: a conditioning mechanism (Adaptive LayerNorm) that injects external signals into network layers. "with conditioning injected via AdaLN~\cite{huang2017arbitrary}"
- Audio adaptor: a learned module that maps raw audio latents to an embedding aligned with motion latents. "To evaluate the alignment capability of the audio adaptor, we conduct alignment evaluation on the test sets of FineDance and BEAT2"
- Audio-Motion Alignment: the process of aligning audio and motion representations, often evaluated via retrieval metrics. "Audio-motion alignment performance on the BEAT2 and FineDance test sets."
- Center of Mass (CoM): the average location of mass of a body, used for balance and stability analysis. "the ground-projected distance between the center of mass (CoM) and center of pressure (CoP)"
- Center of Pressure (CoP): the point on the support surface where the resultant ground reaction force acts, used in stability metrics. "the ground-projected distance between the center of mass (CoM) and center of pressure (CoP)"
- Classifier-Free Guidance (CFG): a sampling technique that blends conditional and unconditional model outputs to control guidance strength. "Classifier-Free Guidance (CFG)~\cite{ho2022classifier}"
- Co-speech gestures: body movements that accompany and emphasize speech, aligned with prosody. "music-driven dance and speech-driven co-speech gestures from audio."
- DAgger: an imitation learning algorithm (Dataset Aggregation) that iteratively collects expert labels on states visited by the learner. "Follwing a DAgger-like approach~\cite{ross2011reduction}, we roll out the student policy in simulation"
- DDIM sampling: a deterministic diffusion sampling schedule that accelerates generation. "we employ a two-step DDIM sampling~\cite{song2020denoising} schedule to ensure real-time performance during deployment."
- Delta Mixture of Experts (ΔMoE): a residual Mixture-of-Experts architecture that models incremental conditional contributions. "We propose MoE in the teacher policy"
- Diffusion model: a generative model that denoises noisy samples through iterative steps to produce outputs (here, actions). "We employ a diffusion model as the student policy to perform action denoising."
- Domain randomization: a robustness technique that randomizes environment/dynamics during training to aid sim-to-real transfer. "we utilize the domain randomization techniques and regularization items"
- GAE (Generalized Advantage Estimation): a variance-reduced estimator for policy gradients in reinforcement learning. "GAE Discount factor () & 0.99"
- Gating network: a network that produces weights to combine expert outputs in a Mixture-of-Experts model. "A gating network dynamically weights experts via residual fusion"
- InfoNCE loss: a contrastive loss that pulls positive pairs together and pushes negatives apart in embedding space. "optimized using the InfoNCE loss~\cite{oord2018representation}"
- IsaacGym: a GPU-accelerated physics simulator for large-scale reinforcement learning. "both the teacher and student policies are trained in the IsaacGym simulation environment"
- Mixture of Experts (MoE): an architecture that combines multiple expert models via a gating mechanism. "Ablation study on vanilla MoE and MoE across both BEAT2 and FineDance datasets."
- MuJoCo: a physics engine widely used for robotics simulation and control. "cross-simulator transfer (MuJoCo)"
- PBHC retargeting: an iterative motion retargeting procedure used to fit human motion onto robot joint constraints. "we employ a 1000-iteration PBHC retargeting~\cite{xie2025kungfubot} procedure."
- PPO (Proximal Policy Optimization): a reinforcement learning algorithm with a clipped objective to stabilize training. "The teacher policy is trained via PPO \citep{schulman2017proximal}"
- Privileged information: training-only signals available to the teacher/critic that are not accessible at test time. "For privileged information, it forms the observation of the critic network together with proprioceptive information."
- Proprioceptive states: internal sensor-based observations like joint positions/velocities and root signals. "the proprioceptive state components are shared between the teacher and student policies"
- Reference State Initialization (RSI): a technique that initializes episodes at random phases of a reference motion to improve learning. "we adopt the Reference State Initialization (RSI) framework \cite{peng2018deepmimic}."
- Retargeting-free: a design that avoids explicit conversion of human motion to robot-specific poses, directly producing actions. "This retargeting-free, latent-driven design improves overall inference efficiency"
- SMPL-H: a parametric human body model (SMPL with hands) used for motion data representation. "It provides the SMPL-H~\cite{pavlakos2019expressive} format motion data"
- T-SNE: a dimensionality reduction method for visualizing high-dimensional data. "T-SNE visualization results of each component for MoE and vanilla MoE."
- Temporal attention: an attention mechanism that captures temporal patterns in sequential inputs. "augmented with temporal attention to capture rhythmic structures inherent in the audio."
- VAE (Variational Autoencoder): a generative model that learns latent representations via variational inference. "The motion latent is extracted from our pretrained VAE"
Collections
Sign up for free to add this paper to one or more collections.