- The paper presents RoboGhost, a retargeting-free framework that directly aligns motion latents with language commands to control humanoid locomotion.
- The methodology integrates a continuous autoregressive motion generator, an MoE teacher policy, and a diffusion-based student policy to achieve low latency and high success rates.
- Quantitative evaluations demonstrate improved tracking accuracy and faster deployment validated through simulations in IsaacGym, MuJoCo, and real-world Unitree G1 experiments.
Retargeting-Free Language-Guided Humanoid Control via Motion Latent Guidance
Introduction and Motivation
The paper presents RoboGhost, a retargeting-free framework for language-guided humanoid locomotion that directly conditions control policies on language-grounded motion latents. Traditional pipelines for text-to-humanoid control involve three stages: (1) decoding human motion from language, (2) retargeting the motion to robot morphology, and (3) tracking the retargeted trajectory with a physics-based controller. This multi-stage approach is susceptible to cumulative errors, high latency, and weak semantic coupling between language and control. RoboGhost eliminates explicit motion decoding and retargeting, enabling direct, semantically aligned control from open-ended language commands.
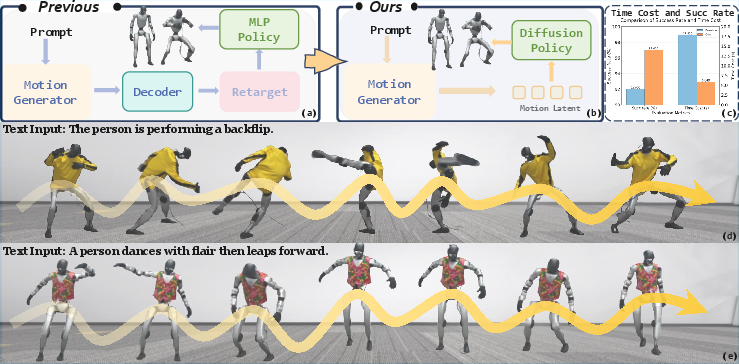
Figure 1: RoboGhost enables direct language-to-action control for humanoid robots, bypassing motion retargeting and demonstrating improved success rates and reduced latency compared to baselines.
Methodology
Architecture Overview
RoboGhost comprises three principal components: a continuous autoregressive motion generator, a Mixture-of-Experts (MoE) teacher policy, and a diffusion-based student policy. The pipeline operates as follows:
- Motion Latent Generation: A textual prompt is processed by a transformer-based motion generator, producing a compact latent representation lref that encodes the semantic intent of the command.
- MoE Teacher Policy: Trained via PPO in simulation with privileged information, the teacher policy leverages MoE to enhance generalization and outputs expert actions for diverse motion inputs.
- Diffusion-Based Student Policy: The student policy, conditioned on lref and proprioceptive states, is trained to denoise actions from noise using a diffusion model. This policy is distilled from the teacher via a DAgger-like approach and does not require explicit reference motion during inference.
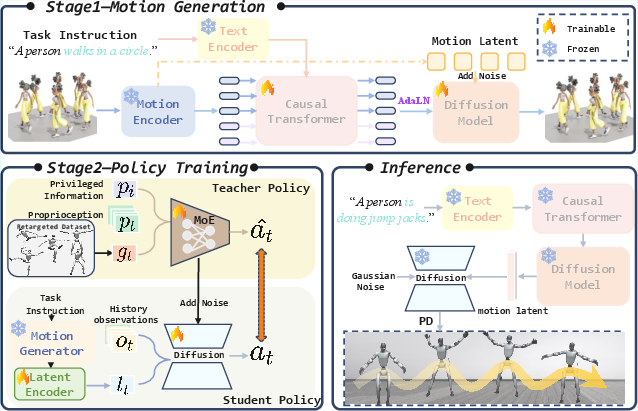
Figure 2: RoboGhost’s two-stage pipeline: motion latent generation followed by MoE-based RL teacher and diffusion-based student policy, fully bypassing motion retargeting.
Continuous Autoregressive Motion Generator
The motion generator employs a causal autoencoder and masked autoregressive transformer architecture. Temporal masking is scheduled via γ(τ)=cos(2πτ), and textual features are extracted using a LaMP transformer. Predicted latent representations condition the downstream diffusion model, ensuring semantic richness and temporal coherence.
Latent-Driven Diffusion Policy
- MoE Teacher Policy: The teacher is trained on a curated, diverse motion dataset, filtering out sequences with high tracking error. The MoE architecture combines expert networks and a gating network, outputting actions as weighted combinations of expert predictions.
- Diffusion Student Policy: The student receives motion latents and observation history, and is trained to denoise actions using a Markov noising process. The denoiser ϵθ is supervised via MSE loss against teacher actions, enabling robust action generation from imperfect latents.
- Inference: DDIM sampling and AdaLN conditioning are used for efficient, real-time action generation. The policy is fully retargeting-free, requiring only the motion latent and proprioceptive states for deployment.
Causal Adaptive Sampling
To address heterogeneous difficulty in long-horizon motor skills, RoboGhost introduces a causality-aware adaptive sampling mechanism. Sampling probabilities for motion intervals are dynamically adjusted based on empirical failure statistics, focusing training on challenging segments and improving sample efficiency.
Experimental Results
Quantitative Evaluation
RoboGhost is evaluated on the HumanML and Kungfu subsets of MotionMillion, using metrics such as retrieval precision (R@1,2,3), FID, MM-Dist, Diversity, success rate, Empjpe, and Empkpe. The continuous autoregressive motion generator achieves competitive performance across all metrics, demonstrating robustness to representation variation.
- Motion Generation: On HumanML3D, RoboGhost achieves R@1 = 0.639, FID = 11.706, and Diversity = 27.230, outperforming several transformer and diffusion baselines.
- Motion Tracking: In IsaacGym, RoboGhost attains a success rate of 0.97 and Empjpe of 0.12, with similar gains in MuJoCo and on the Unitree G1 robot.
Qualitative Evaluation
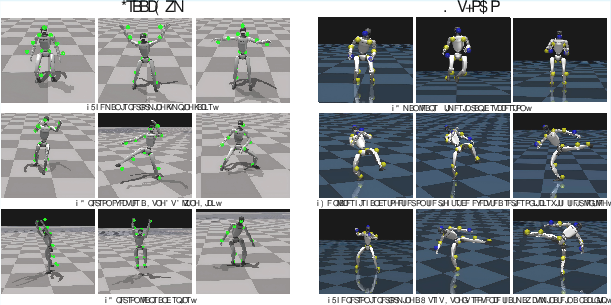
Figure 3: RoboGhost produces semantically aligned, temporally coherent locomotion in IsaacGym and MuJoCo simulations.
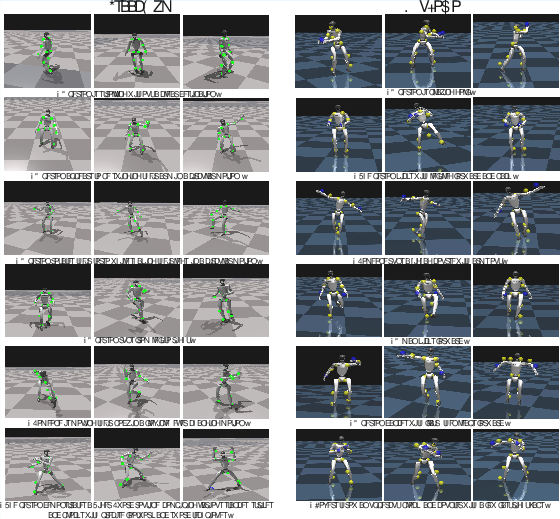
Figure 4: Additional qualitative results in simulation environments, demonstrating robust tracking and balance.

Figure 5: Real-world deployment on Unitree G1, showing smooth execution of language-driven commands.
Ablation Studies
- Retargeting-Free Pipeline: The latent-driven approach reduces deployment time from 17.85s to 5.84s and increases success rate by 5% compared to explicit retargeting pipelines.
- Diffusion vs. MLP Policy: Diffusion-based policies outperform MLP-based policies in both tracking accuracy and generalization to unseen instructions.
- Motion Generator Backbone: DiT offers marginal gains in generation metrics but incurs higher latency; the 16-layer MLP is adopted for efficiency.
Implementation and Deployment Considerations
- State Representation: The student policy relies on extended observation history and motion latents, while the teacher uses privileged information.
- Training: Teacher is trained via PPO with MoE, student via DAgger and diffusion denoising. Curriculum learning and domain randomization are employed for robustness.
- Deployment: Policies are trained in IsaacGym, transferred to MuJoCo for cross-simulator validation, and deployed on Unitree G1 with real-time control via Jetson Orin NX and LCM communication.
Implications and Future Directions
RoboGhost demonstrates that direct conditioning on motion latents enables robust, real-time, semantically aligned humanoid control from language. The framework generalizes to other modalities (images, audio, music), providing a foundation for vision-language-action systems. The retargeting-free paradigm reduces complexity and error accumulation, facilitating practical deployment in real-world environments. Future work may explore scaling to more complex morphologies, multi-agent coordination, and integration with multimodal perception for fully embodied intelligence.
Conclusion
RoboGhost establishes a new paradigm for language-guided humanoid locomotion by eliminating motion retargeting and leveraging latent-driven diffusion policies. The approach achieves superior efficiency, robustness, and semantic alignment, validated across simulation and real-world platforms. This work advances the state-of-the-art in intuitive, deployable humanoid control and lays the groundwork for general vision-language-action robotics.
Figure 6: Qualitative results of the motion generator, illustrating diverse and precise motion synthesis from language prompts.

