- The paper demonstrates that spatial modulation via boundary functions fundamentally alters the NTK eigenspectrum, thereby governing convergence and generalization.
- It employs rigorous NTK analysis and spectral studies using power family functions to relate effective rank measures with training performance.
- The study advocates a structured design of boundary functions to optimize spectral health and mitigate optimization breakdown in high-dimensional PDE solving.
Spectral Analysis of Hard-Constraint PINNs: The Spatial Modulation Mechanism of Boundary Functions
Introduction and Context
Physics-Informed Neural Networks (PINNs) have become integral for numerically solving PDEs in scientific machine learning, leveraging neural architectures to approximate solutions by minimizing residuals against physical laws and boundary conditions (BCs). Traditional soft-constrained PINNs balance PDE and BC terms in their loss functions, often leading to issues with convergence and generalization, given the weight-coupling dilemma that arises from the necessity to tune residual penalties for accurate BC enforcement. Hard-constrained PINNs (HC-PINNs) address this by encoding exact BC satisfaction into the neural ansatz, u~=A+B⋅N, via boundary basis functions B(x) that vanish on ∂Ω. However, their effect on the underlying training dynamics and, especially, the spectrum of the neural tangent kernel (NTK) had previously remained unexplored.
This work offers a comprehensive framework for understanding the critical role of B(x) in HC-PINNs, systematically deriving and analyzing the NTK representations governing convergence, generalization, and spectral conditioning. Notably, the study highlights that B acts as a spatial modulator—reshaping the NTK eigenspectrum and thus fundamentally altering the optimization landscape for PDE learning.
Theoretical Framework: NTK Analysis for HC-PINN
HC-PINNs are constructed by enforcing the BCs in the trial function formulation, with A and B chosen to satisfy A(x)=g(x), B(x)=0 for x∈∂Ω and B(x)>0 in the interior. The pivotal insight is the derivation of the core modulation law:
Kt=BKnB,
where Kn is the NTK of the underlying neural network, and B=diag(B(ri)) imparts spatially varying kernel weights (Figure 1).
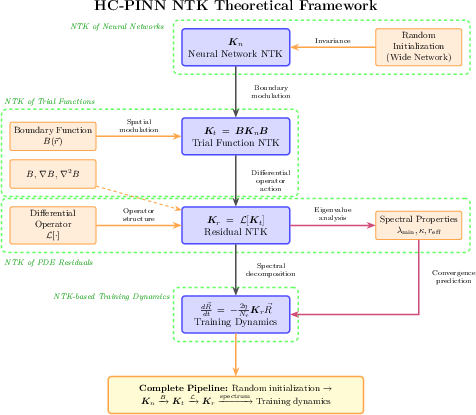
Figure 1: Schematic of the pipeline for NTK analysis in HC-PINNs characterizing the impact of spatially modulated boundary functions B on training dynamics and kernel spectra.
The multiplicative action of B instantiates a "spectral filter" on the eigenmodes of Kn, amplifying or attenuating certain basis components depending on their alignment with B's spatial variation. Importantly, NTK initialization invariance holds in the overparameterized limit—making these effects robust across different seeds and network widths.
Concurrently, the NTK for PDE residuals, Kr, pertinent for the evolution of HC-PINN residuals during optimization, becomes a structured combination of the derivatives of the neural network modulated by the corresponding derivatives of B. Explicitly, for linear operators L, spectral effects propagate strongly through B′′ for diffusion-like operators, further entangling boundary design with optimization.
Empirical and Spectral Analysis
Power Family Boundary Functions
The influence of B's functional form is scrutinized using power families, B(x)=xp(1−x)p and B(x)=xp, varying p:
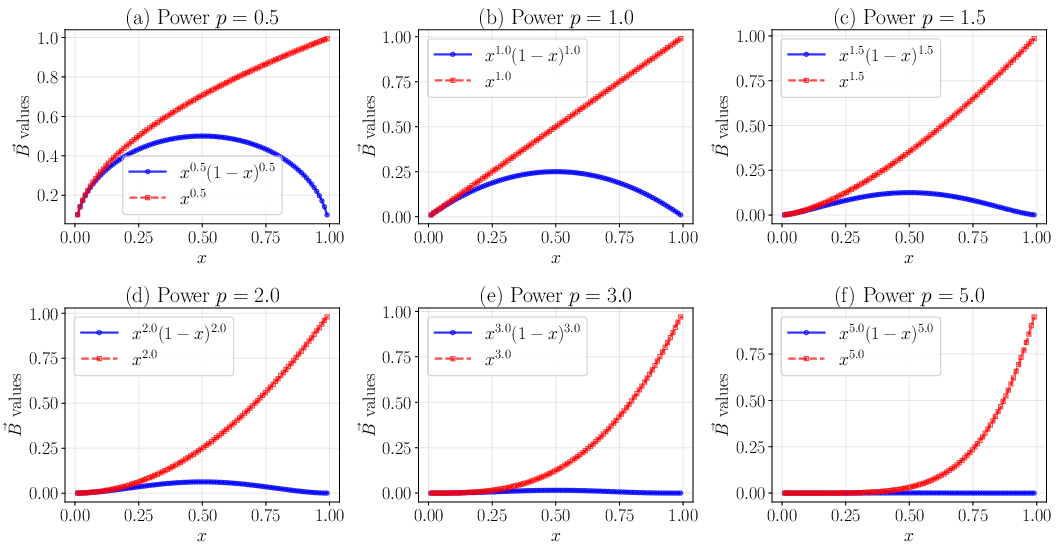
Figure 2: Distributions of power family boundary functions over varying p, highlighting the localization properties for large p.
Mode localization, dynamic range, curvature properties, and statistical dispersion (e.g., Gini coefficient) are tracked, finding that boundary functions with higher curvature and non-uniform distributions increasingly concentrate NTK spectral mass on lower effective ranks (Figure 3 and Figure 4).
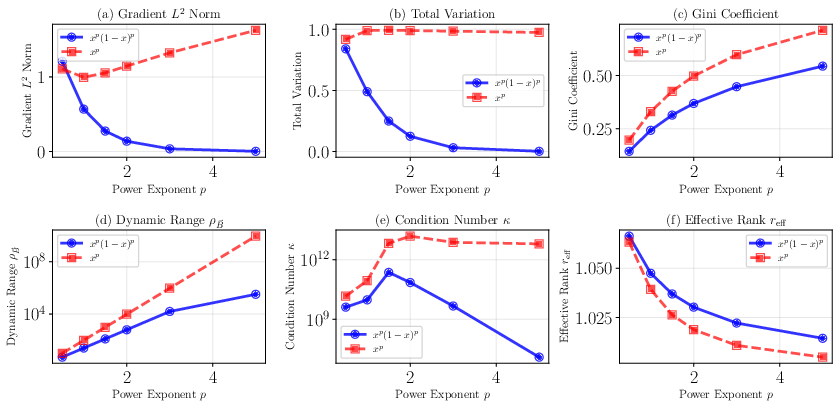
Figure 3: Analysis of boundary function characteristics and the resulting rapid collapse of kernel spectral rank with increasing p for both symmetric and asymmetric families.
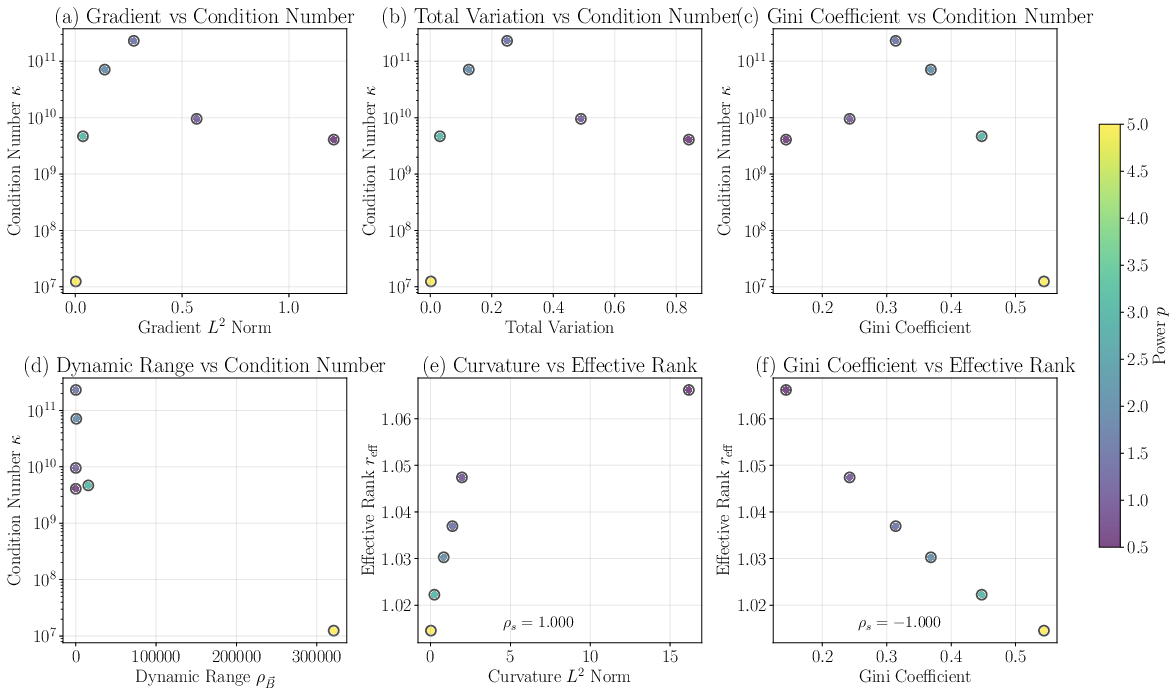
Figure 4: Correlation analysis confirming effective rank reff tracks second-derivative magnitude of B and Gini coefficient, unlike the condition number κ.
The effective rank reff robustly emerges as a better surrogate for expected convergence and generalization than the condition number, which is highly susceptible to outlier eigenvalues and hence numerically unstable.
Spectral Collapse and Optimization Pathologies
In 1D benchmarks, spectral collapse is vividly demonstrated: for B(x)=x0.5(1−x)0.5, high curvature near boundaries results in NTKs with condition numbers exceeding 1012 and effective rank plunging, causing severe slowdowns or outright stagnation during training. As α increases in B(x)=xα(1−x)α, B′′ decays, and so does the overall NTK magnitude, but the region near the center is emphasized, modulating which solution components are efficiently learnable (Figure 5).
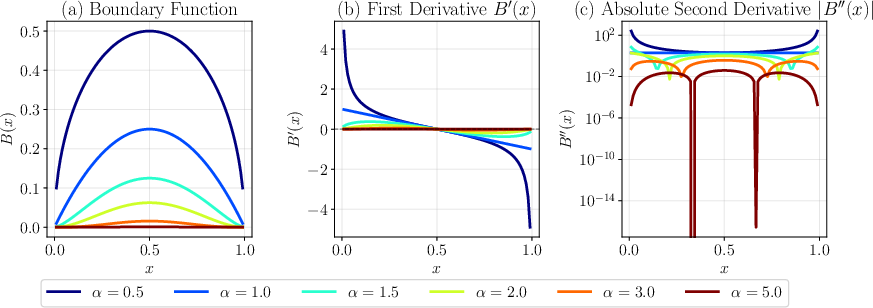
Figure 5: Family of B(x)=xα(1−x)α and their first and second derivatives, showing steep boundary effects for low α and central localization for larger α.
Spectral analysis over multiple families, dimensions, and parametrizations confirms:
- Highly singular or sharply varying B imparts ill-conditioning.
- Effective rank below $2$ correlates with severe slowdowns or inability to resolve high-frequency solution details.
Training Dynamics and Optimizer Regimes
The paper thoroughly investigates the interplay with optimizer choice: vanilla SGD in the NTK regime, though theoretically insightful, proves to be orders of magnitude slower (and often unable to traverse ill-conditioned directions in parameter space) compared to Adam+L-BFGS, which leverages adaptive stepsizes and feature learning outside the "lazy" NTK regime. Despite feature evolution, the initialization-time spectrum of Kr remains a reliable early predictor for convergence and final error, underscoring the diagnostic value of NTK analysis (Figure 6).
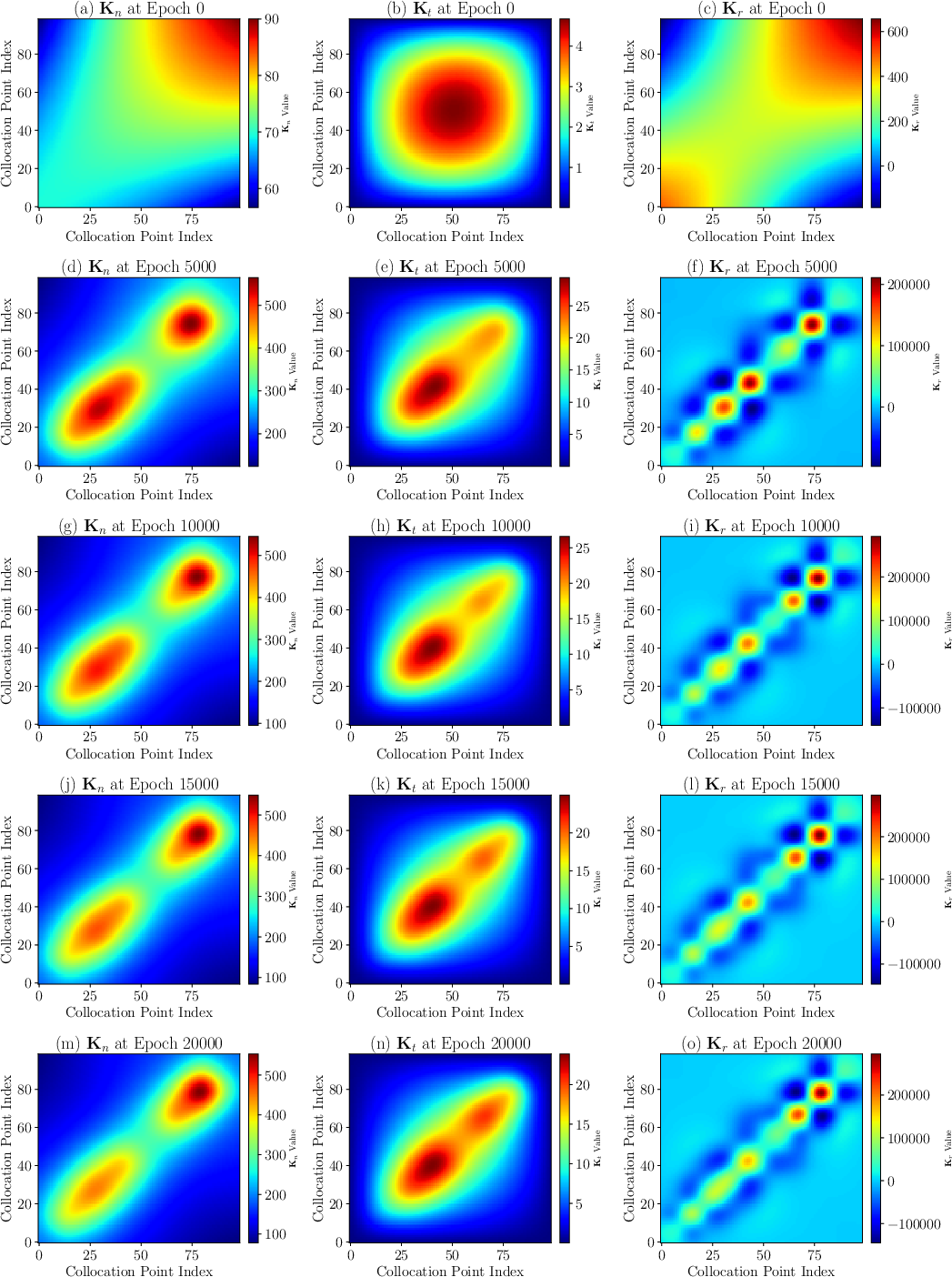
Figure 6: Evolution of the NTK matrix during SGD training, showing limited adaptation; entrywise mass remains concentrated off the diagonal for ill-shaped B.
Implications for Boundary Function Design
The central practical insight is recasting the historically heuristic process of selecting B(x) as a rigorous spectral optimization: what functions maximize reff while avoiding large B′′ (and thereby instability) in the target PDE? The modular NTK decomposition highlights that effective rank and higher-order smoothness of B are strongly predictive for robust convergence, outperforming classical reliance on the NTK condition number.
In higher dimensions, the role of B sharpens: symmetric, low-order polynomials and hyperbolic tangent envelopes consistently yield high effective rank and low error across 2D and 3D benchmarks, while asymmetric or highly localized choices result in dramatic breakdown, particularly due to amplification of ill-conditioning across axes. Moreover, anisotropic B design (asymmetric exponents) universally degrades 3D generalization, independently of loss minimization.
Broader Impact and Limitations
This framework elevates the analysis and selection of boundary basis in HC-PINNs from empirical trial-and-error to theoretically grounded methodology, paving the way for automated, geometry-aware basis search. The theoretical results clarify why many prior "hard constraint" PINN failures can be traced directly to boundary basis spectral degeneracy, not merely to expressive limits or optimizer friction.
However, NTK-derived metrics are strictly valid only in the infinite-width, low learning-rate, non-momentum regime. Practical training with modern deep learning optimizers deviates from this idealized setting, but empirical results indicate that spectral diagnostics at initialization still robustly predict relative training difficulty and solution accuracy, even in feature-learning regimes.
Conclusion
This work rigorously characterizes the spatial modulation mechanism by which boundary functions B(x) in HC-PINNs control the eigenspectrum of the induced NTK, with explicit analytical forms and comprehensive empirical validation. It is established that the effective rank reff is a superior indicator of training viability, convergence, and attainable resolution compared to traditional condition numbers, especially in higher-dimension and more complex geometry settings. Smooth, symmetric boundary choices maximize spectral health, while singular or asymmetric ones precipitate spectral collapse and optimization breakdown.
The implications are profound for both PINN theory and practice: the design of B should be approached as a structured spectral optimization, with initialization-time NTK diagnostics informing boundary strategy before costly training is attempted. Theoretical refinements to the NTK framework that better account for modern optimizer-induced feature evolution, as well as investigations into non-linear or temporal operator effects, are critical future directions for making HC-PINNs maximally robust and interpretable for scientific computing.
References:
"Spectral Analysis of Hard-Constraint PINNs: The Spatial Modulation Mechanism of Boundary Functions" (2512.23295)

