RELIC: Interactive Video World Model with Long-Horizon Memory
Abstract: A truly interactive world model requires three key ingredients: real-time long-horizon streaming, consistent spatial memory, and precise user control. However, most existing approaches address only one of these aspects in isolation, as achieving all three simultaneously is highly challenging-for example, long-term memory mechanisms often degrade real-time performance. In this work, we present RELIC, a unified framework that tackles these three challenges altogether. Given a single image and a text description, RELIC enables memory-aware, long-duration exploration of arbitrary scenes in real time. Built upon recent autoregressive video-diffusion distillation techniques, our model represents long-horizon memory using highly compressed historical latent tokens encoded with both relative actions and absolute camera poses within the KV cache. This compact, camera-aware memory structure supports implicit 3D-consistent content retrieval and enforces long-term coherence with minimal computational overhead. In parallel, we fine-tune a bidirectional teacher video model to generate sequences beyond its original 5-second training horizon, and transform it into a causal student generator using a new memory-efficient self-forcing paradigm that enables full-context distillation over long-duration teacher as well as long student self-rollouts. Implemented as a 14B-parameter model and trained on a curated Unreal Engine-rendered dataset, RELIC achieves real-time generation at 16 FPS while demonstrating more accurate action following, more stable long-horizon streaming, and more robust spatial-memory retrieval compared with prior work. These capabilities establish RELIC as a strong foundation for the next generation of interactive world modeling.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces FutureOrange, a powerful “video world model.” Think of it like stepping into a picture and moving around inside it, while the world stays consistent as you look around, and it reacts instantly to your controls. FutureOrange can:
- run in real time (so it feels responsive),
- remember what it has seen before (so places look the same when you come back), and
- follow your actions precisely (like moving forward, turning left, or looking up).
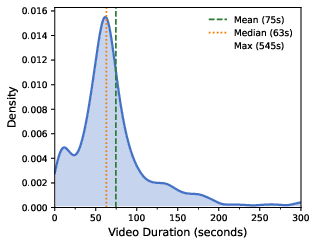
It starts from a single image and a short text description, then lets you explore the scene for up to 20 seconds at 16 frames per second.
What questions were the researchers trying to answer?
The team tackled three big challenges that usually don’t work well together:
- How can a video model respond quickly enough for real-time control?
- How can it keep a steady “memory” of the world so revisited places look the same?
- How can it follow detailed user actions (like camera motions) precisely over a long time?
Their core question: Can we build one system that does all three—fast, consistent, and controllable—without slowing down or breaking over longer videos?
How did they do it? (Methods in simple terms)
They combined smart training tricks with a clever memory design.
1) A coach-and-student training setup
- Imagine a “coach” model (teacher) that can create high-quality videos by looking at both past and future frames. It’s great at consistency but slow and not real-time.
- They trained this coach to handle longer videos (from 5 seconds up to 20 seconds) using a gradual schedule (first 5s, then 10s, then 20s). They also extended the model’s “sense of time” so it can pay attention over longer sequences.
- Then they trained a “student” model to imitate the coach but in a fast, real-time style. The student sees only past information (like real-time), so it can stream videos autoregressively (one chunk after another) with low delay.
An analogy: The coach plays the whole movie knowing the script; the student learns to perform live on stage, using only what’s already happened.
2) Action control: telling the model how to move
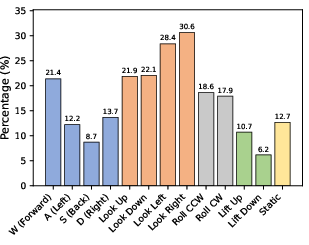
- The model listens to your controls (like a game camera). It supports 13 types of camera actions: 6 movements (forward/back, left/right, up/down), 6 rotations (look up/down, pan left/right, roll clockwise/counterclockwise), and “stay still.”
- It uses two kinds of guidance:
- Relative actions: “what the camera does between frames” (like turning the wheel and pressing the pedals).
- Absolute camera pose: “where the camera is and which way it’s facing overall” (like GPS plus compass).
- This combo helps the model both follow your input smoothly and retrieve the right scene content when you return to a place you saw before.
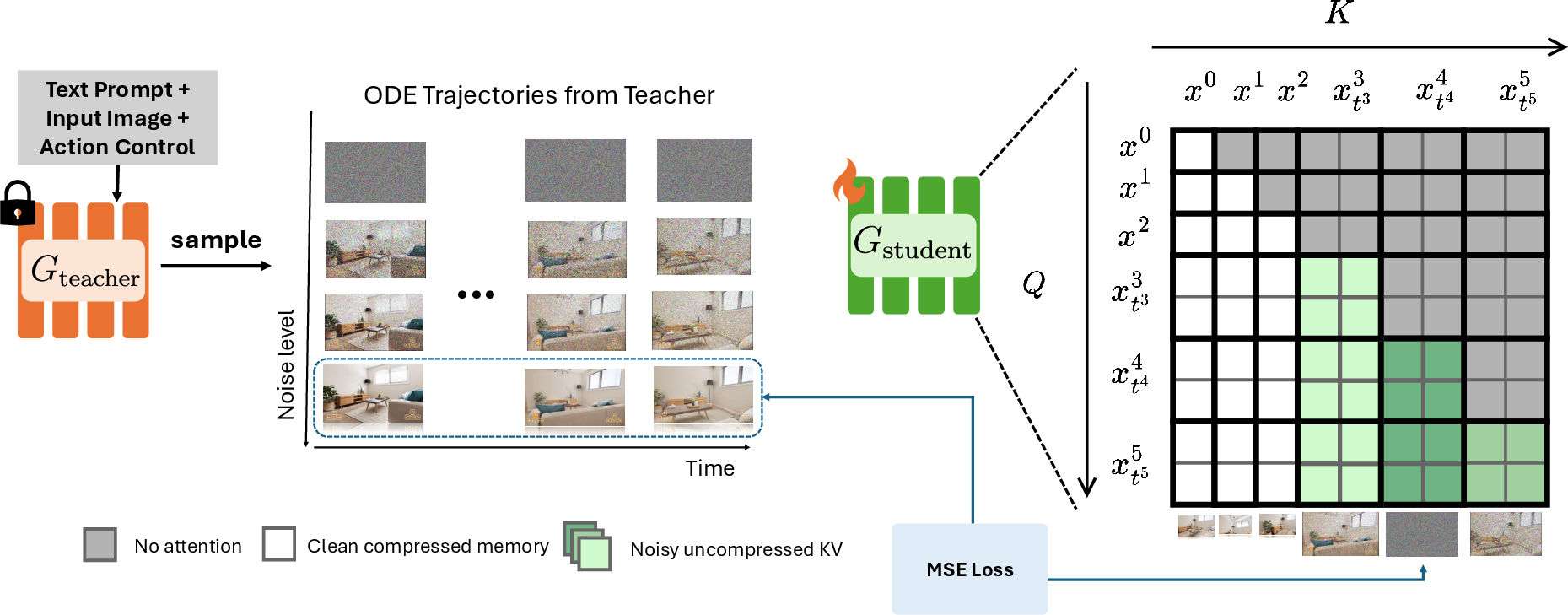
3) Memory that’s fast and long-lasting
- The model keeps a “memory shelf” (called a KV cache) of what it has generated so far.
- To avoid slowing down over time, they compress older memories into tiny, camera-aware “thumbnails” (compressed tokens) while keeping a small high-detail window for the most recent frames.
- This way, the model can still “remember” and recreate faraway details when you revisit them, but it doesn’t carry a huge, slow memory around.
Analogy: Your short-term memory is sharp (recent moments), and your long-term memory stores smaller, summarized snapshots with notes about where you were looking. Together, they keep the world consistent.
4) Teaching the student efficiently (without running out of memory)
- The student learns from the coach using a method called DMD (Distribution Matching Distillation). In simple terms, the student compares how it “thinks” a noisy video should look versus how the coach “thinks,” and adjusts to match the coach.
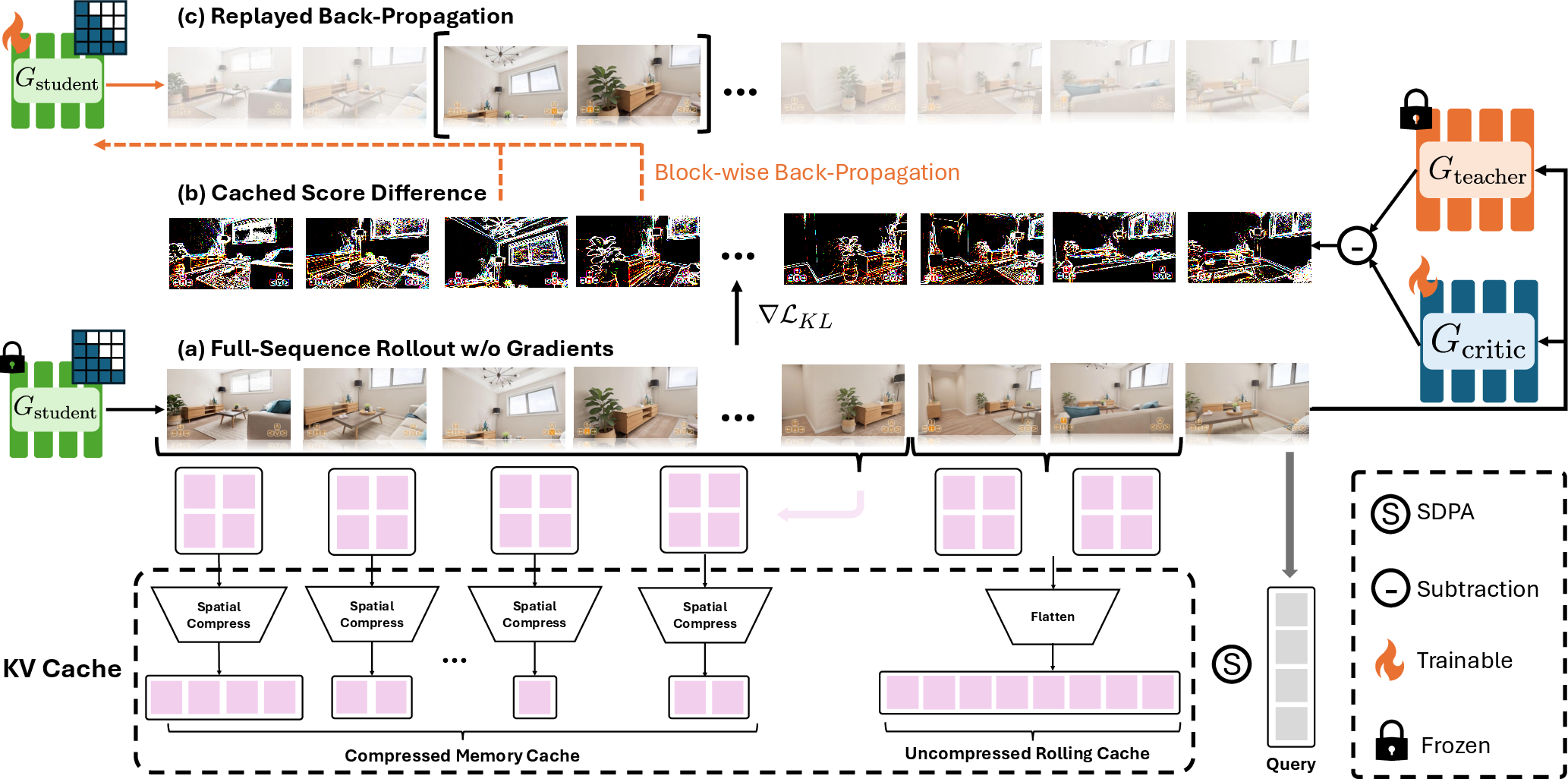
- Long videos make this training heavy on computer memory. So they invented “replayed back-propagation”: 1) First, generate the whole video once without recording the training steps. 2) Save the coach’s feedback for each part. 3) Replay the video a block at a time to update the student, freeing memory as they go.
Analogy: Watch the full game, jot down where mistakes happened, then replay only one play at a time to fix it—so you never need to keep the entire game “loaded” in your head.
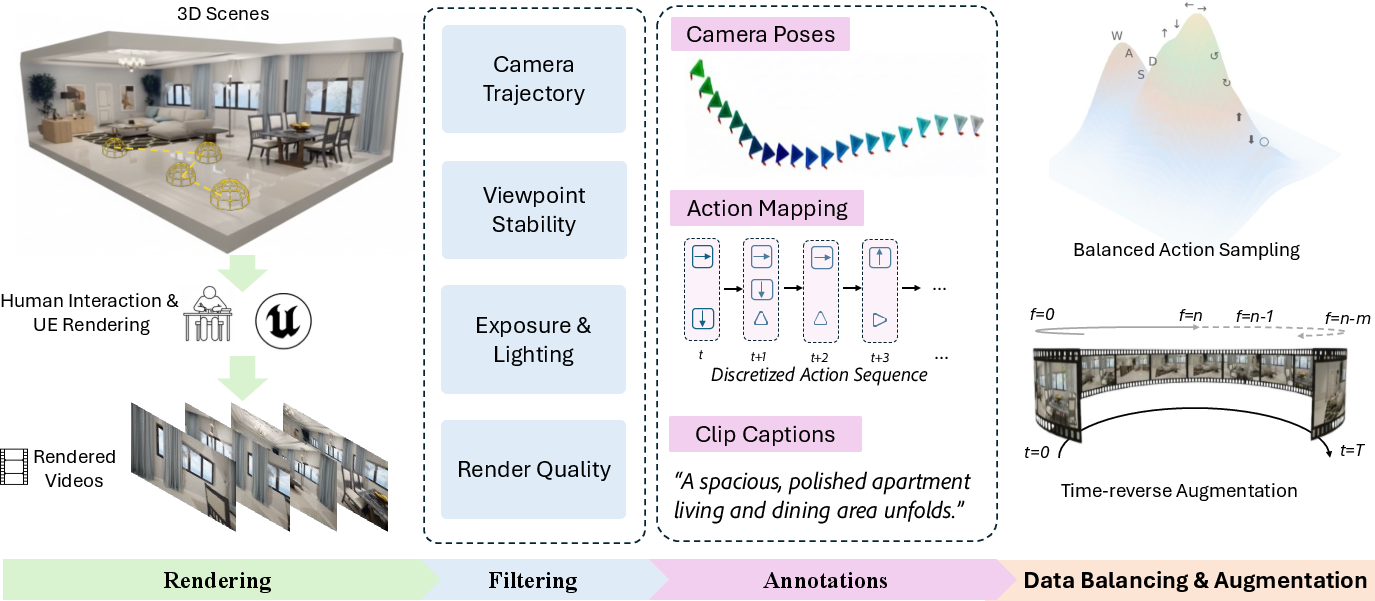
5) Good data for learning exploration
- They built a high-quality dataset using 350 Unreal Engine scenes (indoor and outdoor), with about 1,600 minutes of video at 720p.
- Each frame has precise camera info (position and rotation), and they turn that into clean, balanced action labels (so the model learns all motions well, not just “move forward”).
- They split long videos into 5-second segments with simple captions that describe the scene (not camera motion), so text doesn’t fight with user controls.
- They also use “palindrome-like” clips (forward then reversed) to teach the model how to revisit places and stay consistent over time.
What did they find? (Main results and why they matter)
- Real-time performance: The model runs at 16 FPS at 480×832 resolution and can stream for up to 20 seconds on 4 H100 GPUs.
- Strong memory: It remembers scene layouts across time, so when you turn around or come back, things look stable and consistent (less “drift” or weird changes).
- Better control: It follows action inputs more accurately (your turns, pans, and moves feel right).
- Longer stability: It handles longer videos smoothly thanks to the memory design and long-horizon training.
- Efficient memory: Their compressed-memory trick cuts memory and compute cost by about 4× for older content while preserving useful detail.
Together, these results show you can have fast response, long-term consistency, and precise control in one system—something earlier methods struggled to combine.
Why does this work matter?
Interactive world models like this are stepping stones to next‑generation virtual experiences and tools. They could:
- power smarter game engines that generate worlds on the fly,
- help robots or self-driving systems learn by simulating realistic environments,
- enable creative tools where you “walk through” concepts, films, or designs and edit them in real time.
The big idea is that FutureOrange proves you can get real-time speed, long-horizon memory, and fine-grained control together. That makes it a strong foundation for future systems that let us explore and interact with rich, consistent virtual worlds starting from just a single picture and a description.
Knowledge Gaps
Based on the provided research paper on FutureOrange, an interactive video world model, here are the knowledge gaps, limitations, and open questions:
Knowledge Gaps and Limitations
- Scalability of Memory Mechanism: While a memory compression mechanism is used for efficient long-horizon memory retrieval, the scalability of this mechanism to even longer sequences or more complex scenes is not addressed.
- Generalization Beyond Curated Data: The model is trained on a specifically curated Unreal Engine dataset. Its ability to generalize to other types of video data or dynamically changing real-world video environments is uncertain.
- Action-Text Contradiction Management: Although measures were taken to avoid contradictions between text prompts and user-intended actions, the approach's effectiveness when unpredictable or highly dynamic scenarios are introduced is not demonstrated.
- Computational Overhead of Extended Temporal Horizon: Increasing the model's temporal horizon from 5 seconds to 20 seconds introduces more computational complexity. The implications on computational resources and efficiency, especially on less powerful hardware, need further exploration.
- Empirical Validation of Compression Ratios: The paper claims a reduction in token count via compression, but empirical validation of how varying compression ratios impact performance and memory retrieval is missing.
- Real-World Application and User Studies: There is a lack of details on how the model performs in real-world applications or under different network conditions. User studies to measure the impact on user experience are also absent.
- Robustness to Noisy Input: The robustness of the model when subjected to noisy or erroneous input actions is not explored.
Open Questions
- How does the method perform when the video stream includes unexpected or non-standard actions not covered in the training dataset?
- What are the limits of the model's performance in terms of maximum scene complexity and length where it can still maintain real-time responsiveness and coherence?
- How can the model be adapted or fine-tuned for specific domains or applications without extensive retraining on new datasets?
- Can the compression and memory mechanisms be made adaptive, depending on the context or complexity of the scene to optimize computational resources dynamically?
- What are the ethical implications of having such a powerful simulation tool, and how can privacy and security concerns be mitigated?
These areas present opportunities for future research to refine and expand upon the capabilities of interactive video world models like FutureOrange.
Glossary
- 6-DoF: Six degrees of freedom describing free motion in 3D (translation and rotation along three axes). "record continuous 6-DoF camera trajectoriesâincluding positions, orientations, and the corresponding timestamps"
- Action-Conditioned: A model or training setup that conditions generation on explicit action inputs. "we must first construct a robust action-conditioned teacher model capable of high-quality long-form video generation from streaming action inputs."
- Action Space: The set and format of controllable actions a user/model can issue. "We design a 13-degree action space for FutureOrange"
- Autoregressive (AR): A generation process that produces outputs sequentially, conditioning each step on previous outputs. "In the context of autoregressive (AR) video diffusion models, real-time latency and throughput demand few-step or even one-step denoising models"
- Bidirectional video diffusion model: A diffusion model that attends over past and future context within a sequence during denoising. "Wan-2.1, a bidirectional video diffusion model pretrained for for 5-second text-to-video and image-to-video generation."
- Block-wise causal attention: Attention restricted to past blocks, enabling causal generation while structuring computation in chunks. "replaces bidirectional attention with block-wise causal attention and generates latent frames in a block-causal manner"
- Causal student generator: A unidirectional generator that produces future frames conditioned only on past context. "transform it into a causal student generator using a new memory-efficient self-forcing paradigm"
- Cross-Attention: An attention mechanism that fuses conditioning inputs (e.g., text) into the model’s latent processing. "Input text descriptions are encoded with umT5 and integrated into the model via cross-attention"
- Critic: A learned score or assessment model used to compute distillation targets or losses. "Then we compute and cache the DMD score difference maps over the entire predicted sequence using the critic and teacher models."
- Diffusion-Forcing: A training/inference strategy in diffusion models where tokens carry uneven noise levels within a window. "These scheduling strategies can be regarded as special cases of Diffusion-Forcing"
- Diffusion Transformer (DiT): A transformer architecture tailored for diffusion model denoising in latent space. "The video DiTs include patchifying and unpatchifying layers along with a series of transformer blocks."
- Distribution Matching Distillation (DMD): A distillation method aligning the student’s distribution to data via score matching/KL objectives. "using the Distribution Matching Distillation (DMD) technique"
- Egocentric coordinate system: A coordinate frame centered on and aligned with the camera/agent’s viewpoint. "in the cameraâs egocentric coordinate system"
- Euler angles: Three angles (yaw, pitch, roll) representing rotation in 3D space. "We then convert into yaw, pitch, and roll Euler angles"
- FLOPs: Floating-point operations, a compute cost metric for model execution. "yields a proportional reduction in both KV-cache memory and attention FLOPs"
- Hybrid forcing: Combining teacher forcing and diffusion forcing to improve initialization/training stability. "we adopt a hybrid forcing strategy that combines teacher forcing and diffusion forcing (mask shown on the right)."
- Implicit 3D-consistent content retrieval: Recovering previously seen scene content consistently without explicit 3D reconstruction. "supports implicit 3D-consistent content retrieval"
- KV cache: Key–Value token storage used to retain past attention context during generation. "stored within the KV cache."
- Latent tokens: Compressed representations of frames or patches in the model’s latent space. "historical latent tokens encoded with both relative actions and absolute camera poses within the KV cache."
- Long-horizon memory: Mechanisms that retain and use information across long temporal spans. "represents long-horizon memory using highly compressed historical latent tokens"
- Long-horizon streaming: Real-time generation over long durations while maintaining stability and responsiveness. "Long-horizon streaming additionally requires stable autoregressive rollouts without drift"
- Memory-efficient differentiation: Gradient computation techniques that reduce peak memory usage over long sequences. "enables memory-efficient differentiation of student parameters by accumulating cached gradients of the DMD loss"
- ODE initialization: Initializing a causal student by regressing teacher-provided ordinary differential equation (ODE) trajectories. "ODE initialization. We convert a bidirectional video diffusion model into a causal generator by initializing the student on a set of ODE trajectories obtained from the teacher."
- Patchifying: Converting frames into patch tokens for transformer processing (and reversing via unpatchifying). "The video DiTs include patchifying and unpatchifying layers"
- QK-Norm: Normalization applied to query and key projections to stabilize attention. "Each DiT block integrates YaRN-RoPE, SDPA with QK-Norm, and cross-attention to conditioning tokens."
- Reverse KL divergence: A divergence measure used to align model and data distributions in distillation. "minimizes the reverse KL divergence between the diffused data distribution and the student distribution across sampled timesteps~."
- Rotary Positional Embeddings (RoPE): Position embeddings applied via rotations to enable better extrapolation in attention. "extend the Rotary Positional Embeddings (RoPE) for the query and key tokens in each self-attention layer of the DiT block."
- Scaled dot-product attention (SDPA): The standard attention mechanism using scaled dot products of queries and keys. "before the scaled dot-product attention (SDPA), with the value (V) projections left unchanged."
- Self-Forcing: Training where the model rolls out and learns from its own predictions to reduce exposure bias. "Our framework builds upon the Self-Forcing paradigm"
- Self-rollout: The process of generating long sequences using the model’s own outputs as context. "full-context distillation over long-duration teacher as well as long student self-rollouts."
- SO(3): The group of 3D rotations; set of 3×3 rotation matrices with determinant 1. ""
- Spatio-Temporal Variational Autoencoder (ST-VAE): A VAE that compresses video across space and time into latent tokens. "spatio-temporal variational autoencoder (ST-VAE)"
- Stop-grad: Operator that prevents gradients from flowing through a tensor during backpropagation. "$\hat{\mathbf{x}_{0:L} = \text{stop-grad} (G_\theta(\epsilon_{0:L})),$"
- Teacher forcing: Conditioning on ground-truth or clean past outputs during training to stabilize learning. "Teacher-forcing, inspired by the next-token prediction paradigm of LLMs, trains the model to predict new frames conditioned on previously generated and cached outputs"
- Temporal compression: Reducing the temporal resolution of conditioning/control signals for efficiency. "temporally compresses the control signal by ."
- umT5: A multilingual T5 text encoder used to embed captions/prompts. "Input text descriptions are encoded with umT5"
- Unreal Engine (UE): A 3D creation engine used here to render controlled, annotated training videos. "rendered entirely in Unreal Engine (UE)"
- Viewpoint-aware context alignment: Aligning memory/context using camera viewpoint to improve retrieval and consistency. "This design enables implicit 3D scene-content retrieval through viewpoint-aware context alignment"
- YaRN: A technique to extend positional embeddings’ effective context length for longer sequences. "we apply the YaRN technique to extend the Rotary Positional Embeddings (RoPE)"
Practical Applications
Immediate Applications
The following applications can be piloted with the paper’s current capabilities: a 14B-parameter action-conditioned autoregressive video diffusion model supporting 16 FPS interactive streaming, 6-DoF camera control, and long-horizon memory via compressed KV-cache tokens; a curated UE dataset with precise action/pose labels; and a memory-efficient long-video distillation workflow.
- Interactive scene exploration from a single image (Media, XR, Marketing)
- What: “Step into a picture” experiences where users explore a scene initialized from a single image with WASD/mouse in real time.
- Tools/products/workflows: SceneStepper plugin (web/desktop) that takes an image + text, streams 16 FPS video, and handles 6-DoF camera.
- Assumptions/dependencies: 4×H100-class GPUs for stated throughput and resolution; sufficient rights for input imagery; acceptable domain gap between training (UE scenes) and deployment scenes.
- Previsualization for film, TV, and game design (Creative tools, Software)
- What: Rapid blocking, camera-path iteration, and environment scouting from a concept frame or storyboard; designers iterate with precise camera actions and revisit viewpoints reliably due to long-horizon memory.
- Tools/products/workflows: DCC plugin (Unreal/Unity/Blender) for interactive previz; editor panel mapping 13-DoF controls to camera rigs.
- Assumptions/dependencies: Creative teams accept 480×832 preview quality for speed; licensing for UE assets used during previews; human oversight for artifacts.
- Virtual tours from limited images (Real estate, Tourism, E-commerce)
- What: Immersive exploratory previews of spaces from one or a few photos, allowing customers to “walk around” beyond the frame with consistent spatial recall.
- Tools/products/workflows: Web widget embedded in listing pages; kiosk mode for showrooms; call-to-action “Explore this scene.”
- Assumptions/dependencies: Hallucination risks in unseen areas; must be clearly labeled as generative; moderation for sensitive content; edge devices likely need cloud inference.
- Rapid synthetic egocentric video generation with action/pose labels (Robotics, Autonomy, Computer Vision)
- What: On-demand generation of long-horizon, action-aligned egocentric videos to augment datasets for navigation, SLAM pretraining, action recognition, or control-policy prototyping.
- Tools/products/workflows: DataGen pipeline exporting frames + 6-DoF poses + 13-DoF actions; curriculum sampling of trajectories with controlled revisit patterns.
- Assumptions/dependencies: Sim-to-real gap; training biases from UE scenes; licenses for generated data; appropriate domain adaptations for real-world deployment.
- Interactive user studies on spatial cognition and HCI (Academia, UX research)
- What: Controlled experiments on human navigation/memory using repeatable, artifact-free long-horizon revisits and precise camera control.
- Tools/products/workflows: Experimental harness exposing keyboard/mouse actions and logged pose trajectories; replay for between-subjects designs.
- Assumptions/dependencies: IRB considerations when logging user behavior; calibrated latency across sessions; clear disclosure about synthetic content.
- Action-conditioned controllable video generation baselines (Machine Learning Research)
- What: A reference system for benchmarking action following, drift, and memory retrieval; ablations for compressed-KV memory and hybrid forcing.
- Tools/products/workflows: Release of evaluation harness: metrics for action-following accuracy, viewpoint revisitation fidelity, and long-horizon stability.
- Assumptions/dependencies: Access to model weights and evaluation code; comparable hardware to reproduce throughput.
- Memory-aware KV-cache compression for AR transformers (Software tooling)
- What: Reusable technique for long-horizon streaming that interleaves 1×/2×/4× spatial downsampling of historical KV tokens to cut bandwidth ~4× with minimal quality loss.
- Tools/products/workflows: KV-MemCompression library (PyTorch/Triton) to retrofit AR video models; integration into inference servers.
- Assumptions/dependencies: Model architectures must expose KV-cache and tolerate spatially downsampled keys/values; careful tuning of compression schedule per model.
- Replayed back-propagation for long-sequence distillation (ML systems)
- What: Block-wise “replay” gradient accumulation enabling DMD-based distillation over 20-second sequences within memory budgets.
- Tools/products/workflows: ReplayDistill training module for long-sequence diffusion/transformer students; compatible with DMD loss and self-forcing.
- Assumptions/dependencies: Availability of a long-horizon bidirectional teacher; stable critic/score networks; engineering to manage cached score maps.
- UE data curation and action annotation pipeline (Content production, Academia)
- What: Scripts and procedures to extract 6-DoF poses, normalize motions, derive 13-DoF actions, and balance trajectories with revisit segments.
- Tools/products/workflows: UE plugin + Python toolchain; batch filtering for camera jitter/exposure/render defects; time-reverse augmentation.
- Assumptions/dependencies: Licenses for UE scenes; GPU render budgets for new sequences; expertise in UE controller configuration.
- Interactive advertising and experiential microsites (Marketing, Retail)
- What: Campaigns where users explore a brand world from a key image with coherent spatial memory and text-controlled themes.
- Tools/products/workflows: Campaign builder mapping captions to brand guidelines; analytics on action patterns and dwell time.
- Assumptions/dependencies: Content review and safety filters; scalability of inference for bursts; CDN optimizations for video streams.
Long-Term Applications
These applications require further research, scaling, domain adaptation, or integration with additional systems.
- Embodied AI with persistent world memory (Robotics, Household assistants)
- What: Agents that plan and act using a memory-aware world model to recall occluded or previously visited areas, improving long-horizon tasks.
- Dependencies/assumptions: Robust sim-to-real transfer; sensor fusion with real camera/LiDAR; reliable uncertainty estimates; safety validation.
- Autonomous driving world modeling for closed-loop simulation (Mobility)
- What: Action-conditioned video world models used to simulate traffic scenarios beyond fixed datasets, enabling policy stress testing.
- Dependencies/assumptions: Multi-agent behavior and physics fidelity; integration with planners; regulatory-compliant evaluation pipelines.
- Digital twins from sparse imagery (AEC, Facilities, Energy)
- What: From limited photos or site imagery, generate interactive, explorable scene surrogates to plan maintenance or logistics.
- Dependencies/assumptions: Accuracy guarantees and error bounds; alignment to CAD/BIM; clear separation between “representative” and “as-built.”
- On-device AR “world completion” for novel view synthesis (AR glasses, Mobile)
- What: Completion of unseen content behind walls/around corners to aid navigation or user guidance with streaming consistency.
- Dependencies/assumptions: Tight power and latency budgets; model compression/distillation beyond 14B; safety measures to prevent misleading overlays.
- Telepresence with action-streamed reconstruction (Communications)
- What: Low-bandwidth telepresence where only control/action streams are sent, and the receiver’s world model generates consistent views.
- Dependencies/assumptions: Personalized world priors; shared scene seeds; misalignment/error correction protocols; user consent and privacy safeguards.
- Runtime generative expansions in games (Gaming)
- What: Titles that generate and stream new content from screenshots/concept keys during gameplay with revisitable consistency.
- Dependencies/assumptions: Predictable latency; content moderation; pipeline to blend with deterministic gameplay mechanics.
- Therapeutic VR and training simulators built from photos (Healthcare, Public safety)
- What: Exposure therapy or emergency-response drills using interactive worlds derived from real environments with controllable stressors.
- Dependencies/assumptions: Clinical oversight; validated efficacy; scenario control to avoid harmful hallucinations; data privacy.
- Education: “Field trips” from textbooks (Education)
- What: Students explore historical or scientific scenes synthesized from images and descriptions, with guided action scripts and revisits.
- Dependencies/assumptions: Pedagogical validation; guardrails to avoid factual inaccuracies; content provenance and citations.
- Cross-modal long-context memory transfer (ML research)
- What: Extending compressed-KV long-horizon memory mechanisms to audio, multimodal agents, and long-document transformers.
- Dependencies/assumptions: Architectural adapters for modality-specific features; training recipes for stability; evaluation protocols for memory retrieval.
- Policy and governance sandboxes for generative simulations (Policy, Ethics)
- What: Testbeds to evaluate risks/benefits of generative world models (misinformation, privacy, environmental impact of compute), informing guidelines.
- Dependencies/assumptions: Access to representative models and datasets; stakeholder participation; standardized audit metrics.
- Content provenance and disclosure frameworks (Policy, Platforms)
- What: Standards and tooling to tag interactive generative experiences (e.g., from a single photo) with provenance metadata and user-facing disclosures.
- Dependencies/assumptions: Platform adoption; robust watermarking for streamed video; legal alignment with consumer protection laws.
Notes on feasibility and transfer
- Generalization: The model is trained on curated Unreal Engine scenes; deploying to real-world imagery or niche domains may require fine-tuning and bias audits.
- Hardware: Reported 16 FPS at 480×832 on 4×H100 GPUs; cost/latency must be optimized for consumer or mobile use (quantization, distillation, specialized kernels).
- Safety: For safety-critical uses (autonomy, healthcare), the system’s hallucinations and uncertainty must be explicitly modeled and surfaced to users.
- Licensing: Ensure rights for input images and for any UE-derived assets; clarify ownership of generated experiences and datasets.
- Transparency: For commercial deployments that “extend” a scene beyond the photo, clear labeling as generative and guidance on limitations are essential.
Collections
Sign up for free to add this paper to one or more collections.