- The paper introduces LongStoryEval, a benchmark of 600 novels using an eight-aspect taxonomy to address annotation and computational challenges.
- It compares aggregation, incremental-updated, and summary-based methodologies, finding that summary-based evaluation with NovelCritique best aligns with human ratings.
- Empirical analysis reveals strong system-level correlations with human judgments and underlines the need for scalable, bias-aware long-form narrative evaluation.
Systematic Evaluation of Book-Length Stories: Methodology, Dataset, and Model Advances
Automatic evaluation of lengthy narratives remains a critical yet largely unresolved problem in NLG, especially given that stories exceeding 100K tokens defy the practical context length of current LLMs and the scalability of human annotation protocols. Short-form story evaluation has benefited from LLM prompts and weakly-supervised ranking [Chhun et al., 2022; Yang & Jin, 2024; (Yang et al., 2024)], but direct transfer of these evaluation paradigms to full-length books is hindered by (1) annotation cost, (2) ambiguous or inconsistent evaluation criteria, and (3) architectural and computational processing limits.
LongStoryEval: Curation and Structure
LongStoryEval constitutes a high-coverage benchmark tailored for this underexplored domain, featuring 600 novels with an average of 121K tokens each and comprehensive metadata (title, genres, premise, reviews, reviewer profiles). Critically, each novel is paired with both aggregate rating statistics and a large sample of reader reviews, providing a foundation for supervised and semi-supervised methodologies and analyses of evaluation subjectivity.
The data curation process ensures that all items are absent from pretraining data of tested LLMs, restricting potential contamination and evaluation leakage.

Figure 1: Pipeline for constructing LongStoryEval, from raw reader reviews to aspect-guided structured critiques suitable for modeling.
Reviews are automatically restructured using LLMs to extract salient evaluation aspects, leading to the identification and normalization of over 1,000 unique user-mentioned criteria. These aspects are mapped into an eight-aspect hierarchical taxonomy spanning objective structural concerns (plot, characters, writing, world-building, themes) as well as subjective reader experience facets (emotional impact, enjoyment/engagement, expectation fulfillment).
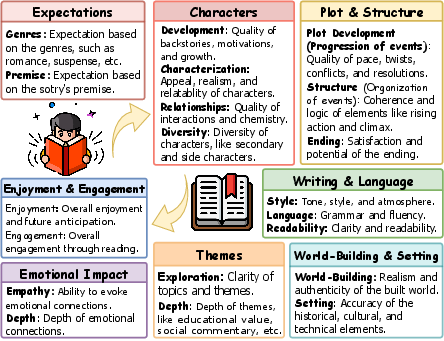
Figure 2: Taxonomy of evaluation criteria and how readers interact with these during the immersive process of consuming a narrative.
Distributional statistics confirm substantial review diversity and criteria representation across genres.
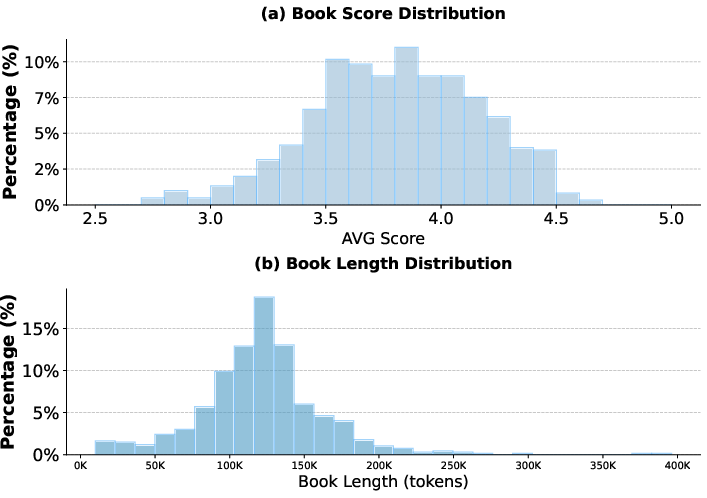
Figure 3: Score and book length distributions reveal both evaluation diversity and a wide coverage of narrative lengths.
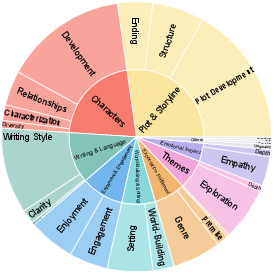
Figure 4: Empirical incidence of evaluation aspects as extracted from natural reader reviews, affirming the taxonomy coverage.
Decomposition of Evaluation Methodologies
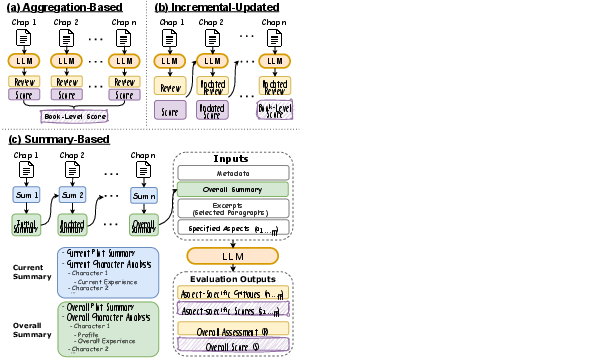
Three evaluation paradigms for long-form stories are compared:
Results indicate that single-pass evaluation over the entire book is computationally infeasible or ineffective, and that aggregation-based and summary-based methods dominate in both fidelity to human ratings and computational cost-effectiveness.
Model Development: NovelCritique
NovelCritique is introduced as an 8B-parameter Llama 3.1-based model, instruction-tuned on structured critiques and normalized scores from LongStoryEval. The model exclusively leverages the summary-based framework, absorbing both textually rich summaries and reviewer judgments aligned with the established aspect taxonomy. Bias mitigation and reviewer normalization are applied during training to counteract rating and review selection biases in the GoodReads-derived review corpus.
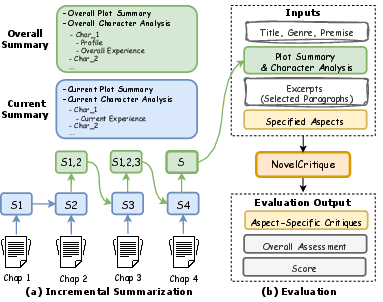
Figure 6: Schematic for NovelCritique highlighting incremental summarization and the transformation of summary/context into aspect-structured critique and scoring.
Ablation studies show that organization of reviews around explicit criteria, review bias correction, and user-standard normalization meaningfully enhance model alignment with ground truth.
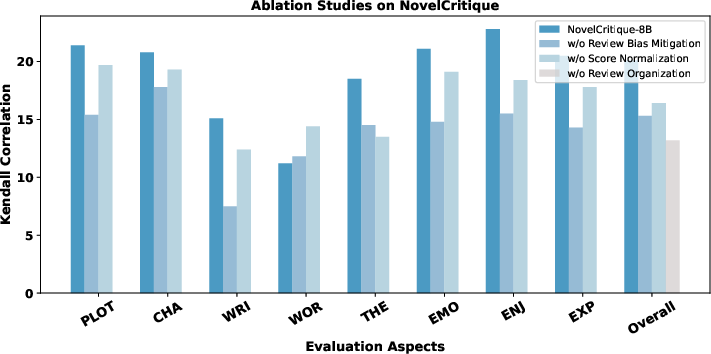
Figure 7: Decomposition of system performance gains attributable to core components of the NovelCritique pipeline.
Empirical Results and Analysis
NovelCritique achieves strong system-level Kendall-tau correlations (up to 27.7 for overall scores) with human ratings—substantially surpassing GPT-4o and other LLMs on both holistic and aspect-specific axes. Aggregation- and summary-based strategies are consistently superior to incremental-updated or naive single-pass evaluations.
Analysis reveals:
- Plot and character aspects are the primary contributors to final ratings; writing and world-building, while frequently mentioned, have lesser marginal impacts.
- Subjective criteria (emotional impact, enjoyment, expectation fulfillment) are critical for distinguishing between works of similar technical merit.
- High-quality input summaries marginally improve summary-based model performance over condensed/cheaper alternatives, but diminishing returns are observed beyond a certain summary granularity threshold.
Qualitative review examination exposes a tendency of strong LLMs to overlook story weaknesses unless explicitly prompted, often skewing towards leniency on low-rated works (Figure 8). In comparison, NovelCritique provides more nuanced and critical commentary, with both strengths and weaknesses reflected commensurately with the ground-truth reader assessments.
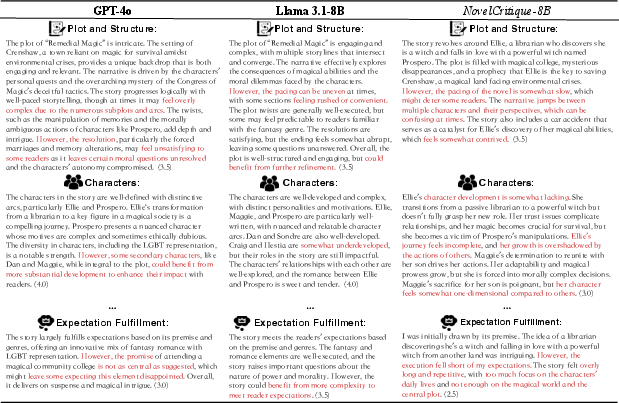
Figure 8: Diagnostic critique illustration for a poorly rated novel, with generated weaknesses explicitly highlighted.

Figure 9: Example detailed review for a highly rated novel, reflecting aspect guidance and alignment with human impressions.
Efficiency analysis confirms a major computational and monetary advantage for summary-based evaluation. For GPT-4o, five-run-average summary-based evaluation is an order of magnitude cheaper and faster relative to aggregation or incremental approaches, confirming its suitability as the practical default for this domain.
Implications, Limitations, and Future Directions
This study delivers a methodological and empirical advance in the automatic evaluation of long-form narratives, offering a scalable, high-fidelity dataset and modeling pipeline. The findings challenge the implicit assumption that LLM-based evaluation reliability extends trivially to long-form narratives; inconsistencies and bias are exacerbated at book scale, requiring architecture, data, and training adaptations not necessary for short-form NLG evaluation [stureborg2024large, (Yang et al., 2024)].
Ethical handling of reader reviews and protection of book copyright, as enforced by summary-only content release, ensures compliance with standard research norms [wan2019Fine].
Moving forward, reliable and interpretable aspect-based evaluation for long-form content is positioned to catalyze advances in narrative generation, personalized recommender systems, and creative AI co-authoring frameworks. Scalable pairwise or ranking-based protocols (including data-efficient/sampling variants [xu2024data]) offer further promise over direct numerical scoring in overcoming inconsistencies and calibration issues. Personalized evaluation—contingent on user history, genre preferences, and bias patterns—remains an open research target as more user metadata becomes available [wang2023perse].
Conclusion
This paper establishes the LongStoryEval dataset and a reference methodology for evaluating book-length stories with high fidelity to real reader standards. Through the introduction of a comprehensive aspect taxonomy, comparative study of scaling evaluation paradigms, and the NovelCritique model, the work both quantifies and addresses the limitations of LLM-based evaluators for long-form narratives. The demonstrated improvement over commercial LLMs and open-source baselines for aspect-guided, summary-based evaluation points to viable paths for robust, efficient evaluation in machine-assisted literary criticism, story generation validation, and NLG research generally.
Reference: "What Matters in Evaluating Book-Length Stories? A Systematic Study of Long Story Evaluation" (2512.12839)