LLMEval: A Preliminary Study on How to Evaluate Large Language Models
Abstract: Recently, the evaluation of LLMs has emerged as a popular area of research. The three crucial questions for LLM evaluation are ``what, where, and how to evaluate''. However, the existing research mainly focuses on the first two questions, which are basically what tasks to give the LLM during testing and what kind of knowledge it should deal with. As for the third question, which is about what standards to use, the types of evaluators, how to score, and how to rank, there hasn't been much discussion. In this paper, we analyze evaluation methods by comparing various criteria with both manual and automatic evaluation, utilizing onsite, crowd-sourcing, public annotators and GPT-4, with different scoring methods and ranking systems. We propose a new dataset, LLMEval and conduct evaluations on 20 LLMs. A total of 2,186 individuals participated, leading to the generation of 243,337 manual annotations and 57,511 automatic evaluation results. We perform comparisons and analyses of different settings and conduct 10 conclusions that can provide some insights for evaluating LLM in the future. The dataset and the results are publicly available at https://github.com/llmeval .
- A General Language Assistant as a Laboratory for Alignment. arXiv:2112.00861.
- A Survey on Evaluation of Large Language Models.
- AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback. arXiv:2305.14387.
- GPTScore: Evaluate as You Desire. arXiv:2302.04166.
- Measuring Massive Multitask Language Understanding. arXiv:2009.03300.
- C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models. arXiv:2305.08322.
- From Word Embeddings To Document Distances. In International Conference on Machine Learning.
- Holistic Evaluation of Language Models. arXiv:2211.09110.
- Lin, C.-Y. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In Annual Meeting of the Association for Computational Linguistics.
- G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment. arXiv:2303.16634.
- Bleu: a Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, 311–318. Philadelphia, Pennsylvania, USA: Association for Computational Linguistics.
- Is ChatGPT a Good NLG Evaluator? A Preliminary Study. arXiv:2303.04048.
- Large Language Models are not Fair Evaluators. arXiv:2305.17926.
- BERTScore: Evaluating Text Generation with BERT. arXiv:1904.09675.
- MoverScore: Text Generation Evaluating with Contextualized Embeddings and Earth Mover Distance. arXiv:1909.02622.
- Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. arXiv:2306.05685.
- AGIEval: A Human-Centric Benchmark for Evaluating Foundation Models. arXiv:2304.06364.
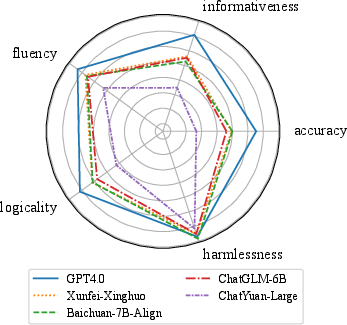
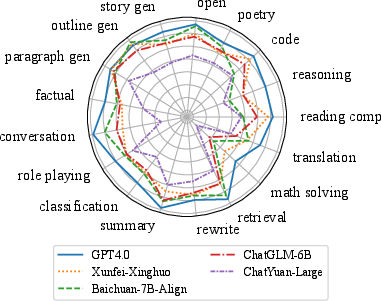
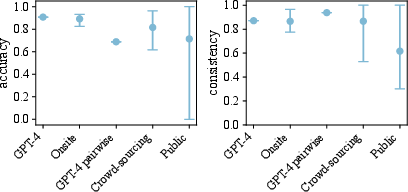
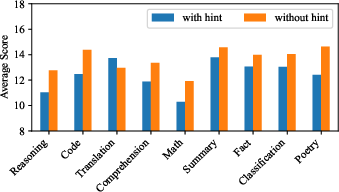
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.