- The paper demonstrates that reward models trained on LitBench’s human-labeled dataset achieve 78% accuracy, outperforming zero-shot LLM judges.
- The methodology leverages 2,480 debiased story comparisons from Reddit’s r/WritingPrompts to ensure reliable, human-aligned evaluation.
- Implications suggest that structured feedback and fine-tuned models can significantly improve AI-generated creative writing.
Introduction to LitBench: Standardizing Creative Writing Evaluation
The paper "LitBench: A Benchmark and Dataset for Reliable Evaluation of Creative Writing" (2507.00769) tackles a significant challenge in AI text generation: the evaluation of creative writing generated by LLMs. Creative writing lacks grounded truths due to its open-ended nature, posing difficulties in automated verification. LitBench offers a novel approach by providing the first standardized benchmark and dataset specifically aimed at creative writing verification, contributing a structured dataset of human-labeled story comparisons, drawn from Reddit’s r/WritingPrompts.
Methodology and Data Collection
LitBench comprises a test set of 2,480 debiased human-labeled story comparisons and a training corpus of 43,827 pairs with human preference labels. The data collection process involves mining Reddit’s r/WritingPrompts, where users engage by submitting stories and voting through upvotes, creating an implicit preference dataset. To ensure data reliability, rigorous filtering processes are applied, such as excluding pairs with marginal upvote differences and balancing length biases by adjusting the dataset to achieve proportional representation of shorter and longer stories.

Figure 1: Preprocessing methodology for dataset creation.
LitBench introduces several approaches to model performance evaluation, including zero-shot LLM judges such as Claude-3.7-Sonnet, Bradley-Terry reward models, and Generative reward models. The benchmark identifies that among off-the-shelf LLM judges, Claude-3.7-Sonnet reaches the highest agreement with human preferences at 73%, yet still falls short compared to reward models trained on LitBench, which achieve a higher accuracy of 78%.
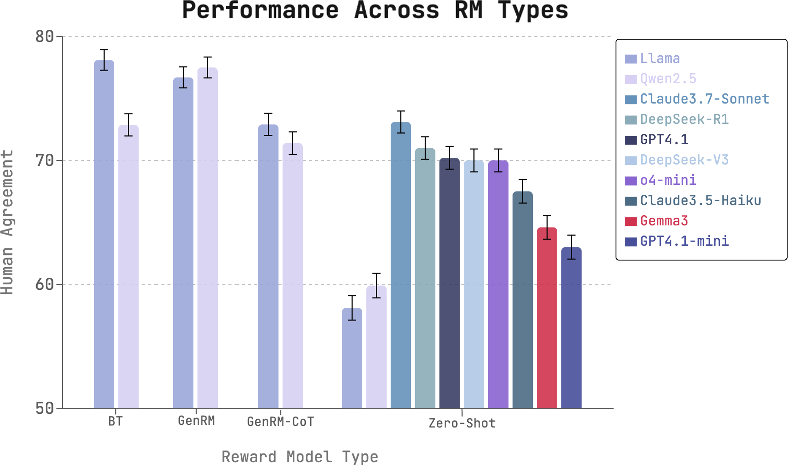
Figure 2: Trained verifiers outperform zero-shot LLM-judges on LitBench. Claude3.7-Sonnet is the strongest zero-shot model. BT verifiers are competitive with GenRMs, but GenRMs with CoTs perform worse. The sizes of Qwen, Llama and Gemma backbones are 7B, 8B and 12B, respectively.
The paper further investigates reward models, with Generative reward models also competing well but showing decreased performance when enhanced with chain-of-thought processes, contrary to their success in other domains such as math problem-solving. An extensive human study was conducted to validate reward model predictions against fresh LLM-generated stories, reaffirming that trained models align with human preferences in creative contexts.
Implications and Future Directions
The rigorous methodology underlying LitBench ensures a reliable framework for the evaluation of creative writing in computational models. By demonstrating the superiority of fine-tuned models over proprietary LLM judges, this research sketches future pathways for efficient creative text generation aligned with human sensibilities. The potential for improving human agreement rates underscores the future significance of incorporating more nuanced feedback and structured rubric-based evaluations to refine model alignments further.
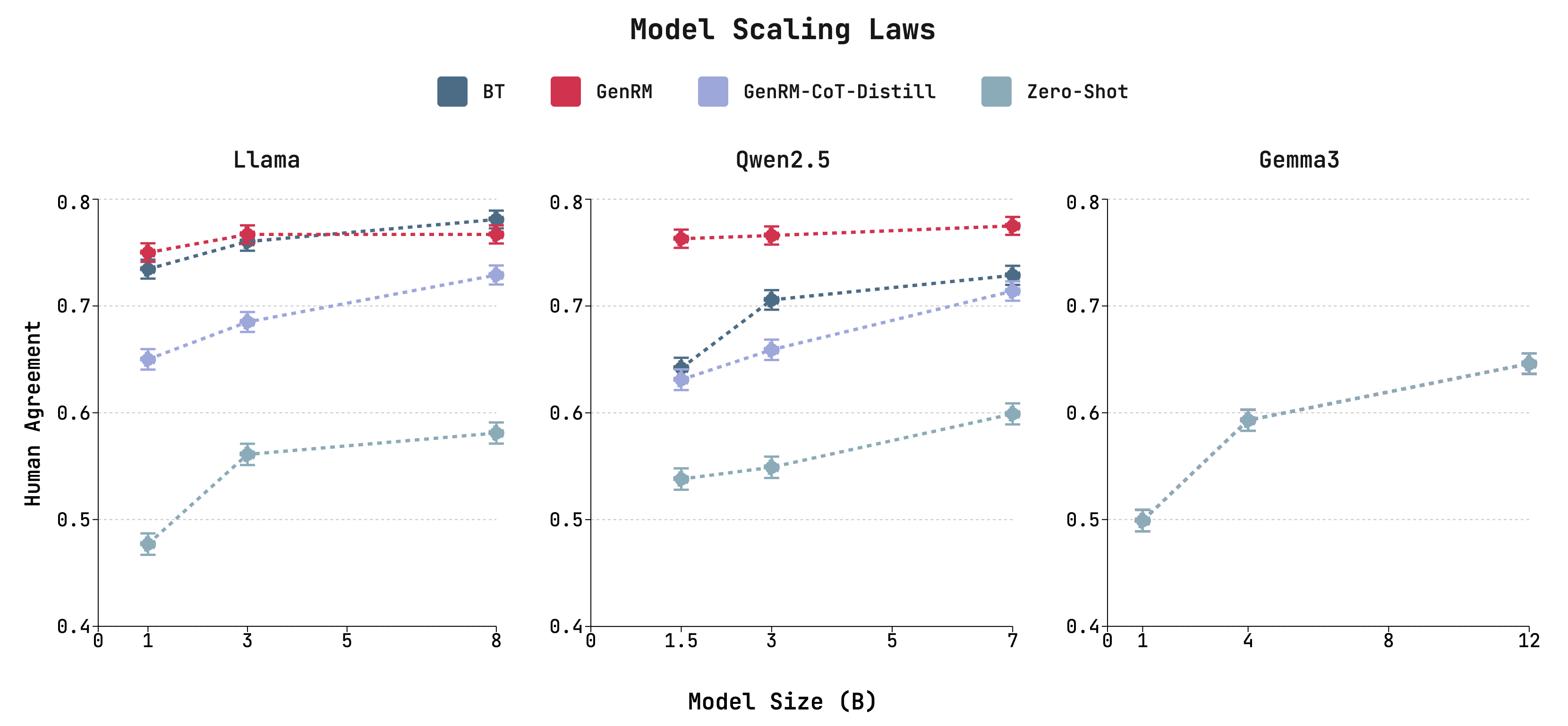
Figure 3: Human agreement scaling is inconsistent with model size for different types of RMs.
Considering these findings, LitBench paves the way for expansive research into model training for creative writing tasks, suggesting Quality Improvement pathways through well-structured feedback loops, possibly transforming AI's role in creative writing and narrative generation.
Conclusion
LitBench provides significant contributions to AI-based creative writing evaluation, proving that trained reward models can surpass existing LLM judges by leveraging human preference-derived datasets. These findings highlight substantial advancements towards achieving reliable automated creative writing evaluation and optimization systems, offering a solid foundation for continued research in AI's capacity for creativity and content generation.

