- The paper introduces a memory-based multi-view segmentation benchmark to evaluate 3D scene understanding with mean intersection-over-union as the core metric.
- It demonstrates that self-supervised ViT encoders, especially DINOv3 and DINOv2, maintain robust spatial consistency under significant angular shifts.
- The study reveals key memory-performance trade-offs and exposes limitations in geometry-grounded models like VGGT when applied to multi-view settings.
Evaluating Foundation Models’ 3D Understanding Through Multi-View Correspondence Analysis
Introduction and Motivation
The paper targets the underexplored issue of viewpoint robustness and 3D scene understanding in vision foundation models, especially those relying on ViT-based self-supervised and multimodal encoders. Conventional benchmarks mainly assess single-view recognition or dense view synthesis, neglecting pixelwise semantic consistency as viewpoint shifts. Catastrophic failures in recognition due to angular deviations are well-documented, yet standard evaluation rarely isolates this geometric vulnerability. The authors’ major contribution is a systematic, in-context, memory-based segmentation benchmark on Multi-View ImageNet (MVImgNet), extending the Hummingbird paradigm of non-parametric, prompt-based scene understanding from 2D to structured multi-view 3D scenarios. This approach bypasses finetuning and decoders, directly probing encoder-intrinsic spatial robustness under controlled angular displacements.
Experimental Methodology
The experimental setup leverages the Hummingbird retrieval framework in combination with COLMAP-binned MVImgNet object categories, assigning images to angular bins spanning 0∘ to 90∘ in 15∘ steps. Model feature memory banks store reference-angled support images with dense masks; query masks are inferred by k-NN patch feature retrieval under varied angular separations. Models evaluated include self-supervised (DINO, DINOv2, DINOv3), multimodal (CLIP, SigLIP2), mixed-supervised (TIPS, C-RADIOv2), and an explicitly geometry-grounded transformer (VGGT). Memory sizes are scaled to examine sample efficiency and computational trade-offs.
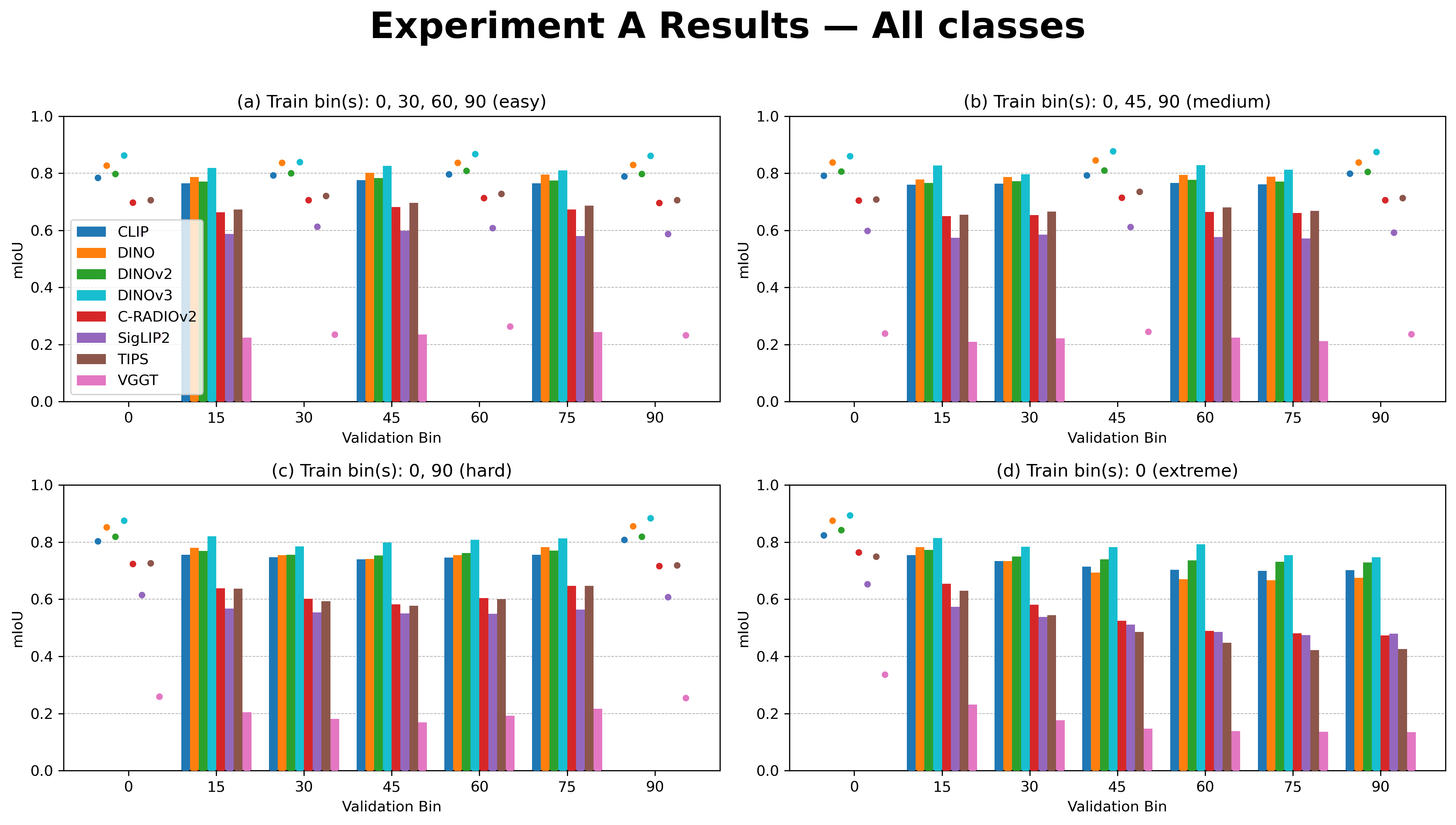
Difficulty levels for segmentation tasks are systematically constructed by varying the density and distribution of support-bin angles, creating Easy, Medium, Hard, and Extreme regimes. A primary metric is mean intersection-over-union (mIoU), measured as a function of validation bin angular offset relative to the support bins.
The object category selection enforces full angular coverage and manageable memory footprints, resulting in 15 diverse classes (Figure 1, Figure 2).

Figure 1: Multi-view categories. Each MVImgNet category is shown across all viewpoint bins (0∘–90∘), above are example visualizations for 4 of the 15 selected classes.
Results and Analysis
Cross-Viewpoint Generalization
Systematic evaluation (per Table 1 and Figure 3) reveals three key findings:
Breaking Point Analysis
Normalized mIoU curves (Figure 4) demonstrate that DINOv2, DINOv3, DINO, and CLIP degrade smoothly, showing no sudden breaking point up to 90∘ reference-query angle. TIPS and VGGT, by contrast, exhibit significant performance drops at 30∘, failing to maintain spatial consistency, confirming self-supervised ViT encoders’ clear advantage in geometric feature stability under perturbation.
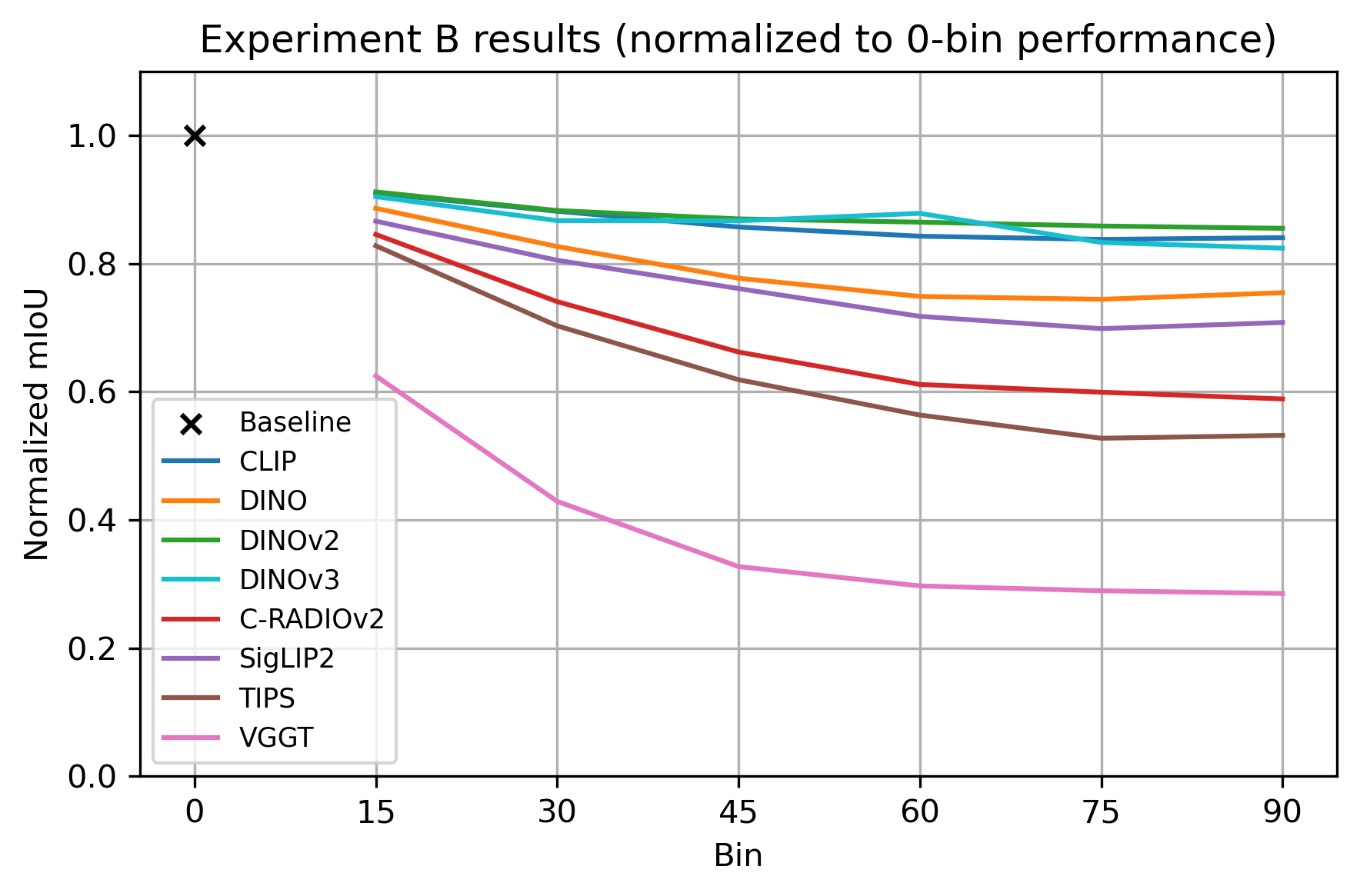
Figure 4: Normalized mIoU under viewpoint shifts. DINO-like models degrade more smoothly, TIPS/CRADIO/VGGT degrade sharply at small angular offsets.
Memory Size Robustness
Increasing the support memory size systematically boosts mIoU, particularly for weaker encoders (see Table 2). Gains for DINO-family models are marginal past 640k entries, while SigLIP2/TIPS/CRADIOv2 see larger, more sustained improvements, indicating that robust feature learning is more parameter-efficient than scaling external memory. This reflects typical memory-performance trade-offs for nonparametric inference pipelines under descriptor uncertainty.
Per-Class and Qualitative Insights
Some classes (e.g., "sofa", "broccoli") maintain high generalization, while thin-structured or partially annotated categories (e.g., "coat rack", "bed") manifest sharply reduced mIoU and, in the case of bed, annotation errors outweigh true model failures (see Figure 5, Figure 6).
Qualitative comparisons (Figure 7) show that DINO-predicted masks often more closely trace visible object boundaries even than ground-truth annotations—a strong indication of local shape preservation, even in the presence of label noise.
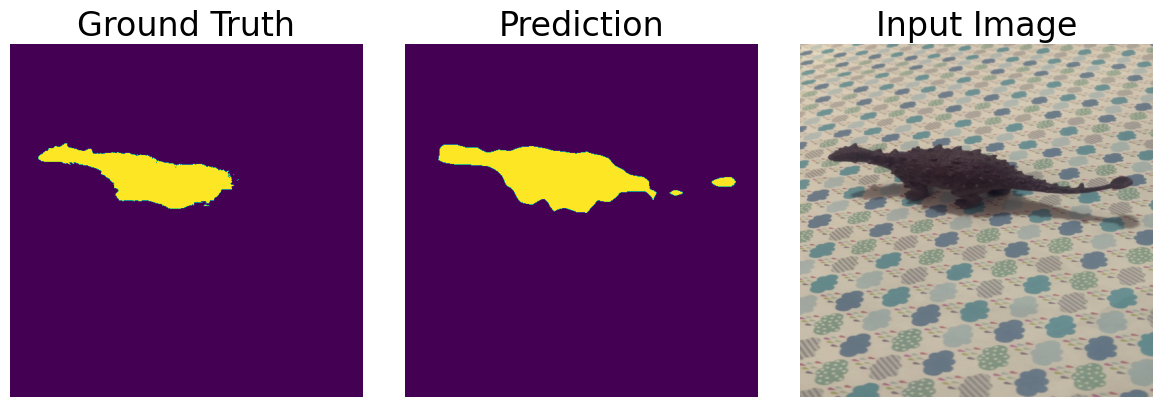


Figure 7: Qualitative segmentation using DINO. Model predictions closely align with visual boundaries, sometimes outperforming coarse ground truth in terms of appearance-consistent segmentation.
Implications and Future Directions
This work definitively demonstrates that self-supervised ViT encoders, particularly DINOv3 and DINOv2, provide robust, viewpoint-consistent representations for 3D-aware segmentation tasks without task-specific finetuning or explicit 3D alignment in pretraining. In practical terms, this finding is highly consequential for robotics, autonomous driving, and embodied intelligence, where agents must recognize objects or scenes from arbitrary, previously unseen viewpoints using only in-context memory.
The failure modes of explicitly geometry-grounded models in this setting accentuate the architectural and pretraining objective mismatch that persists in dense correspondence and retrieval-based inference regimes. Robustness to geometric perturbation can—at present—be more reliably obtained via appropriate self-supervised objectives than explicitly multi-view model design, unless memory architectures are also co-adapted.
Theoretically, these findings highlight the emergence of 3D-aware part consistency in scalable self-supervised ViTs, suggesting further pretraining objectives that enforce equivariance or invariance to 3D transformations may be fruitful. The evaluation paradigm also points the way towards nonparametric, memory-based generalization tests that better match downstream applications in open-world and few-shot scenarios.
Open research directions include:
- Extending the evaluation to multi-object segmentation, occlusion, and compound 3D rotations.
- Benchmarking with synthesized as well as real-world multiview data and extending angular range beyond 90∘.
- Investigating how architectural elements (e.g., register tokens in DINOv3) interact with retrieval robustness.
- Mixing parametrized and nonparametric inference to further capitalize on robust self-supervised spatial features.
Conclusion
The paper offers a rigorous, controlled, memory-retrieval-driven evaluation of current foundation vision models’ capacity for viewpoint-consistent 3D understanding. The evidence unambiguously positions DINO-based self-supervised ViTs as the state-of-the-art for geometry-aware, in-context segmentation among major foundation encoders, with their advantage amplified as viewpoint variability increases. Multimodal and geometry-focused pretraining, as currently implemented, lag behind unless model and inference procedures are jointly adapted. This benchmark sets a new standard for evaluating 3D spatial consistency in frozen visual encoders and raises foundational questions about the interplay between pretraining objectives, architectural priors, and in-context generalization.
References: