- The paper presents a unified post-training recipe that synthesizes complex multi-hop reasoning tasks with scalable memory management for ultra-long contexts.
- It employs a multi-stage reinforcement learning strategy featuring task-balanced sampling, task-specific advantage estimation, and adaptive entropy control for improved model stability.
- Empirical results demonstrate significant performance gains over baselines on long-context benchmarks, achieving state-of-the-art metrics in reasoning and memory tasks.
QwenLong-L1.5: A Post-Training Framework for Advanced Long-Context Reasoning and Memory Management
Motivation and Overview
QwenLong-L1.5 (2512.12967) addresses long-standing deficiencies in LLMs' post-training regimes regarding long-context reasoning, multi-hop information integration, and scalable memory management. Despite progress in architecture and pre-training for extended contexts, the field lacked a unified, rigorous post-training recipe capable of synthesizing challenging reasoning data, stabilizing RL on long sequences, and extending agentic memory far beyond static context windows. QwenLong-L1.5, built atop Qwen3-30B-A3B-Thinking, delivers a comprehensive solution integrating (1) a principled data synthesis framework targeting multi-hop grounding and reasoning, (2) stabilized RL optimizations (notably task-balanced sampling, task-wise advantage estimation, and adaptive entropy-controlled policy optimization), and (3) a memory-augmented agent design pushing context lengths to the multi-million token regime.
Long-Context Data Synthesis Pipeline
Critically, QwenLong-L1.5's data pipeline focuses on generating high-value, verifiable long-context reasoning tasks—moving far beyond shallow retrieval or NIAH exemplars. Documents are decomposed into atomic facts and relational structures (via knowledge graph or schema extraction), and then multi-hop, globally distributed compositional questions are assembled programmatically. For numerical reasoning, complex inter-document tabular synthesis and SQL-grounded answer generation are employed. The pipeline enforces two-level validation: knowledge grounding (filtering out questions answerable from parametric knowledge alone) and contextual robustness (retaining only samples impervious to distractor insertion). This supports a training set with orders-of-magnitude more complexity and context diversity than prior art.
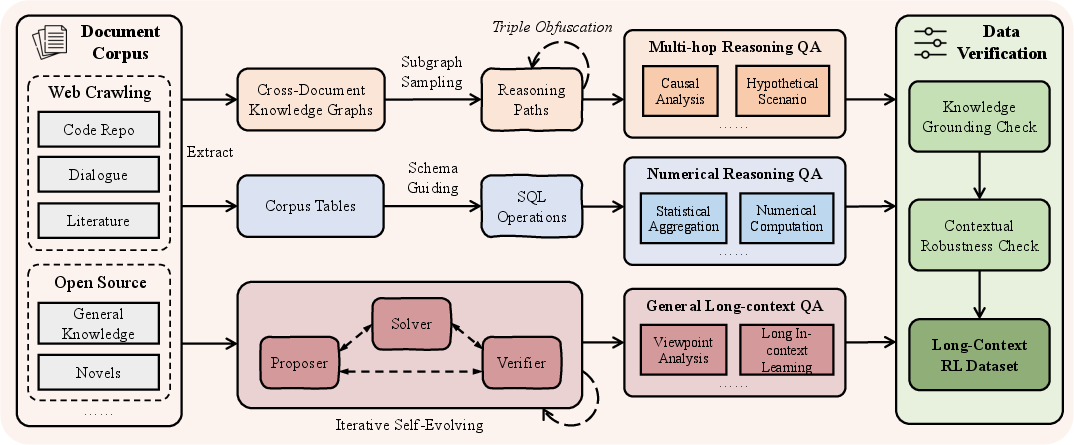
Figure 1: End-to-end RL data synthesis system generating verifiable multi-hop, distributed evidence tasks for long-context training.
The multi-agent self-evolution (MASE) strategy further automates task escalation and answer verification, unlocking higher-order question complexity through curricularly organized proposer-solver-verifier feedback.
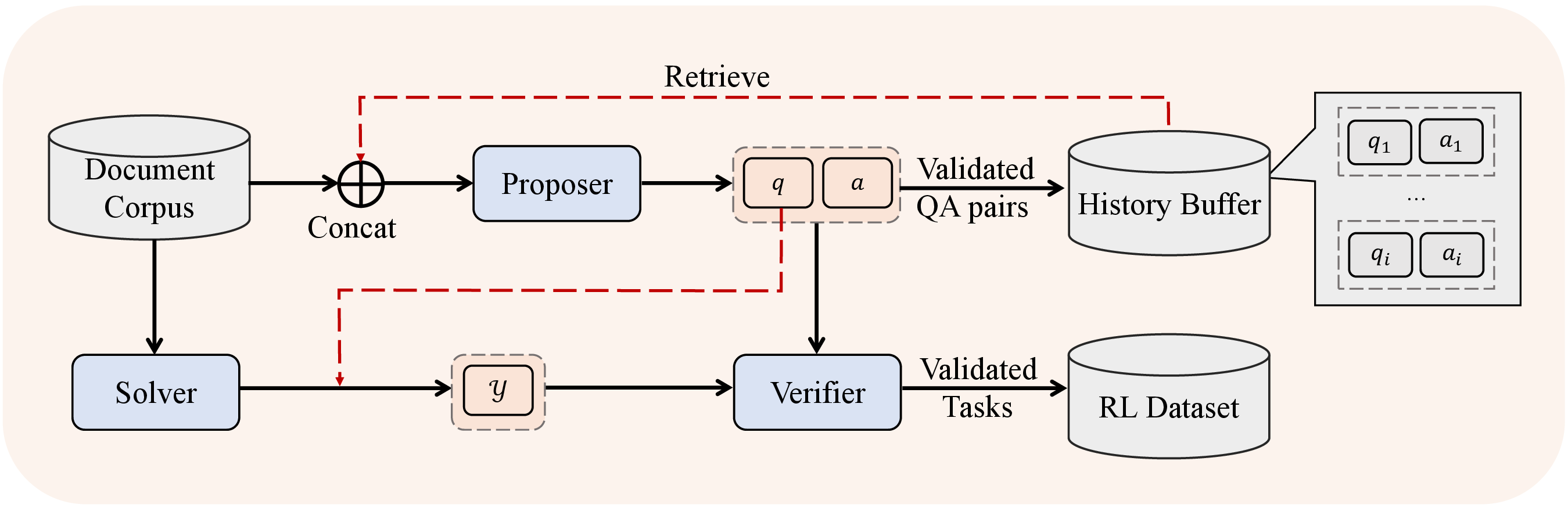
Figure 2: Multi-agent self-evolved data synthesis—enabling automatic escalation of long-context question complexity via inter-agent interaction.
Notably, QwenLong-L1.5's RL corpus covers a far wider input length spectrum than QwenLong-L1, with substantial data volume at challenging >64K token lengths, as shown below.
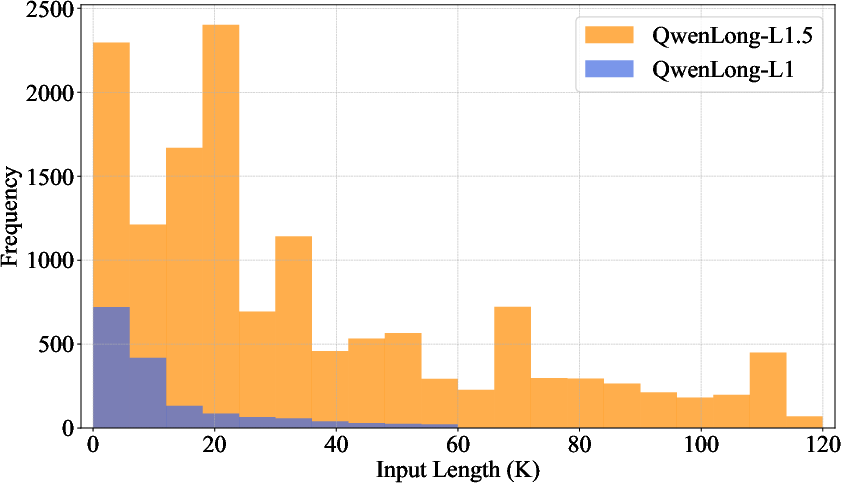
Figure 3: Comparative distribution of RL training input lengths, with QwenLong-L1.5 heavily emphasizing extended-length samples.
Reinforcement Learning for Long-Context Reasoning
Pipeline and Progressive Length Extension
Training stability under long, diverse, multi-task RL is a persistent failure mode. QwenLong-L1.5 employs a multi-stage progressive context extension regime: RL stages at increasing context/output sizes, with retrospective difficulty sampling at stage transitions. Full-context reasoning is isolated from memory-agent training, and expert models are subsequently merged via SCE, followed by a final RL stage on the fused model.
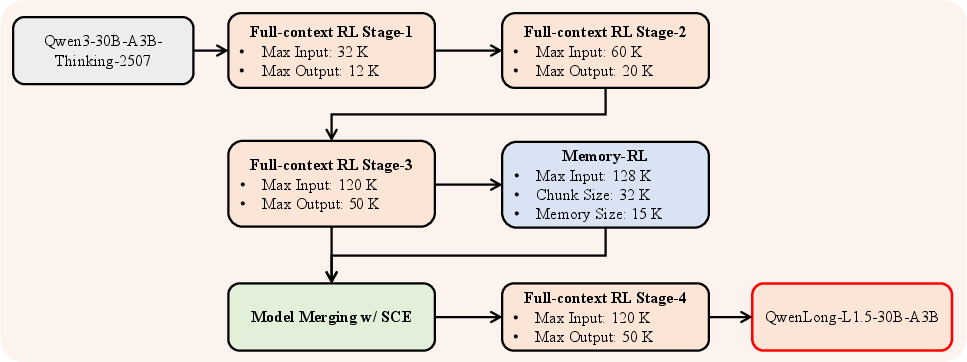
Figure 4: QwenLong-L1.5 post-training pipeline: full-context stages, memory-agent specialization, SCE model merging, and joint final RL.
RL Stabilization: Task-Balanced and Task-Specific Schemes
Long-context RL brings acute reward variance and instability. QwenLong-L1.5 introduces task-balanced sampling to equalize multi-task batch composition, mitigating entropy spikes and premature response length growth. Additionally, task-specific advantage estimation computes reward normalization within task-types, decoupling dense/sparse reward distributions and reducing cross-task interference.
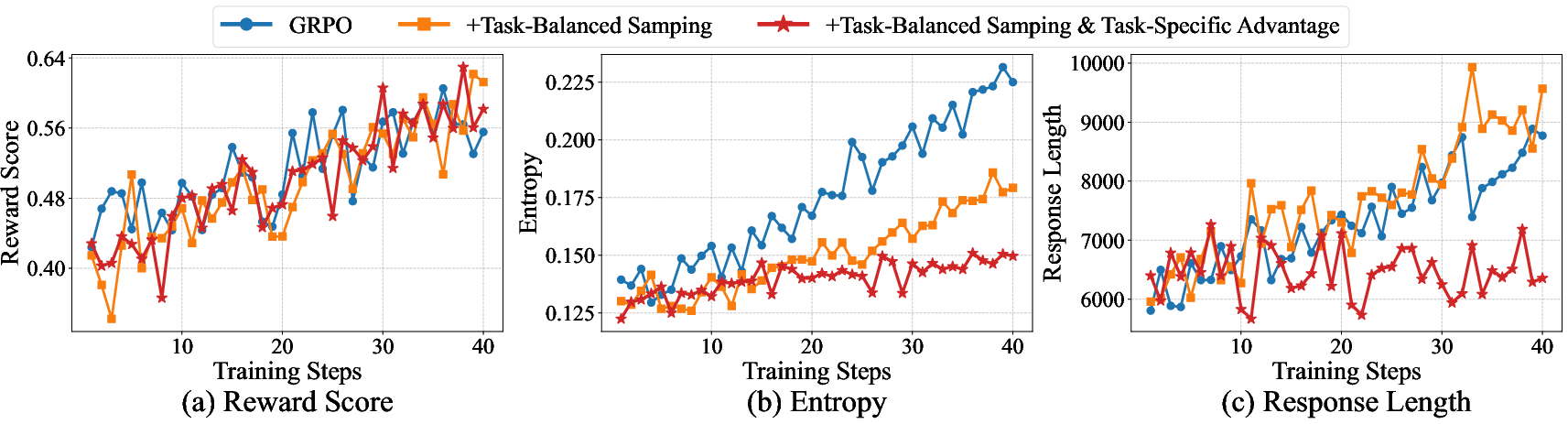
Figure 5: Task-balanced sampling + task-specific advantage estimation stabilize RL training: entropy and response lengths remain controlled without reward collapse.
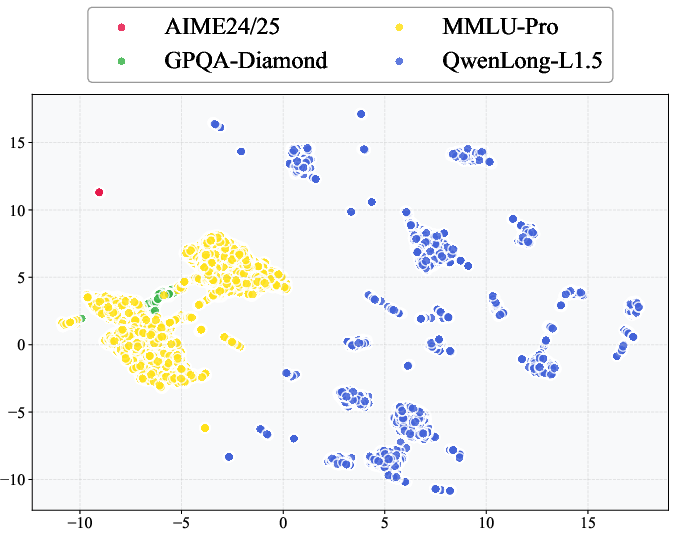
UMAP projections reveal the training data's multi-modal semantic clustering, underscoring the necessity for batch- and task-aware balancing strategies.
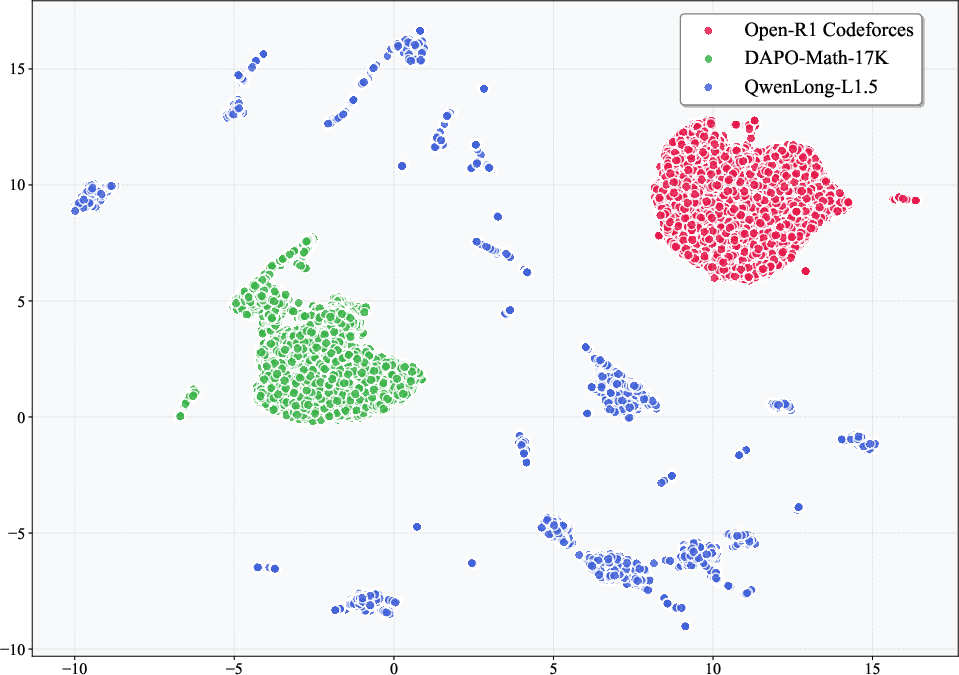
Figure 6: UMAP projection of long-context vs. standard RL training sets demonstrates multi-clustered, high-variance domains.
Negative Gradient Clipping & Adaptive Entropy Control (AEPO)
The highly localized, stepwise reward assignment in long-context RL leads to a significant fraction of "high-entropy negative rollouts"—where incorrect generations share large overlap with correct reasoning but diverge late. Empirically, token entropy and gradient norm are tightly correlated (ρ=0.96, p<0.0001), implying undamped gradient spikes from exploratory tokens in negative trajectories.
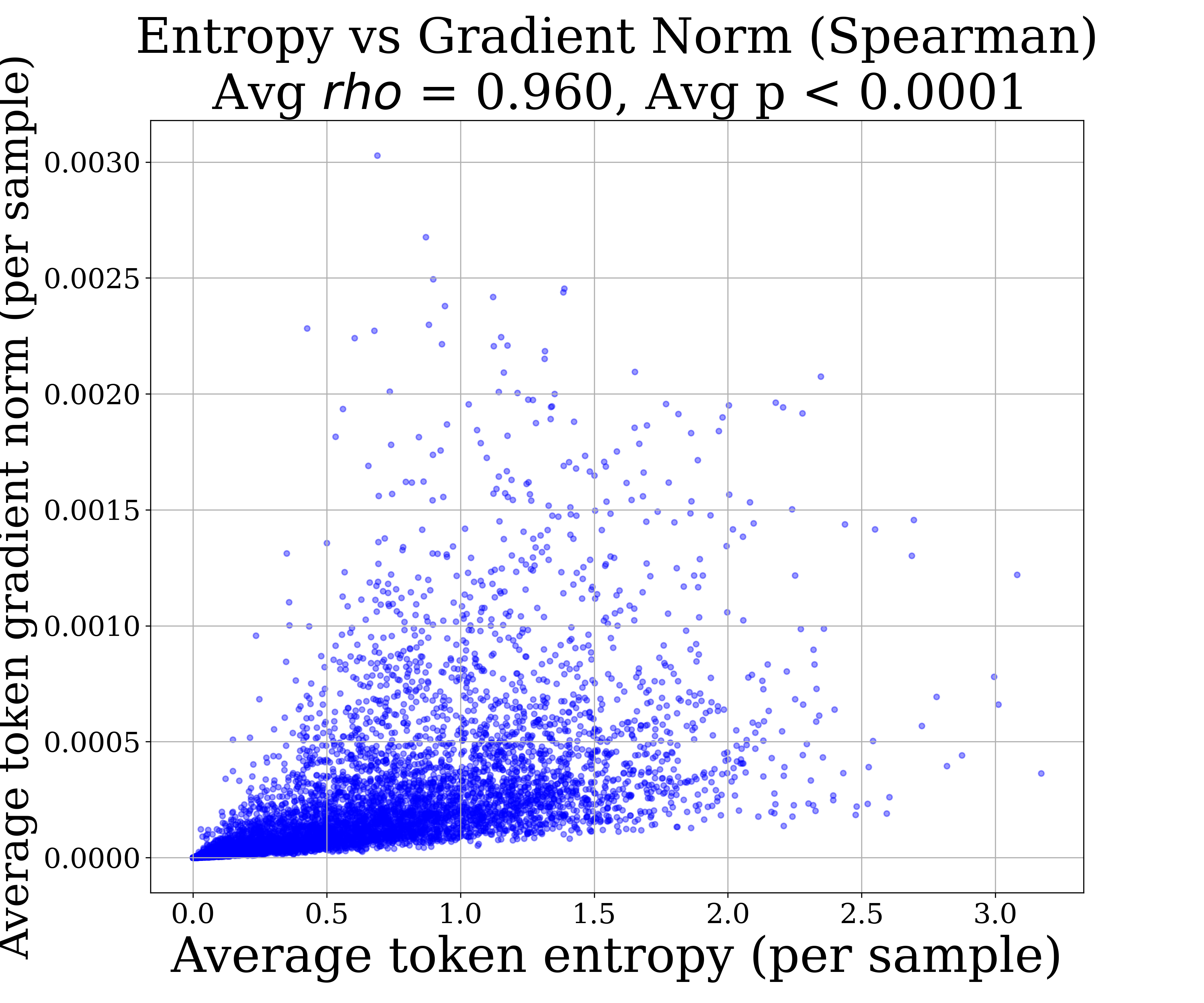
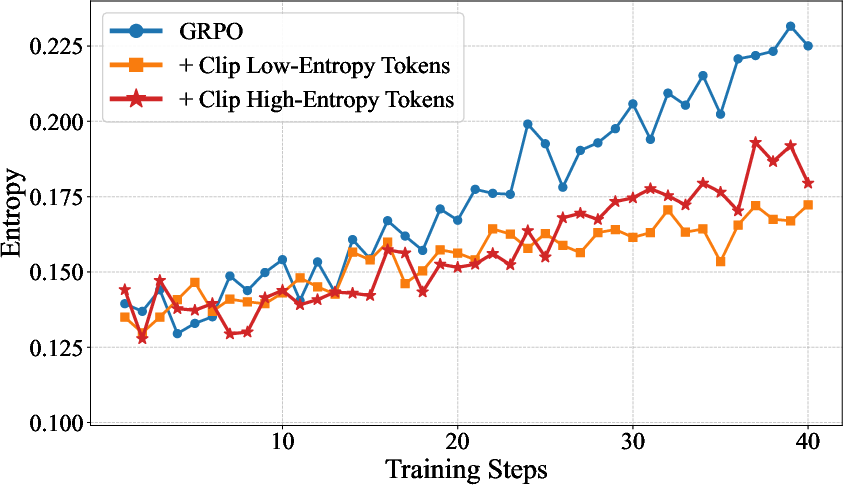
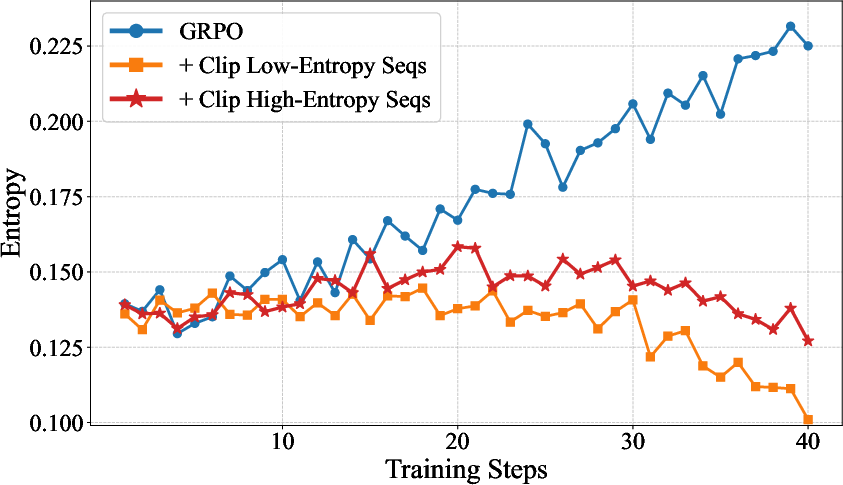
Figure 7: Strong correlation between token entropy and gradient norm in negative rollouts—high-entropy tokens dominate RL update variance.
QwenLong-L1.5 applies dynamic masking of negative-advantage samples, governed by batch entropy thresholds (AEPO): above threshold, negative gradients are masked (accelerating exploitation), below threshold, they are restored (preserving exploration). This yields stable entropy dynamics and robust reward improvement across prolonged RL runs.
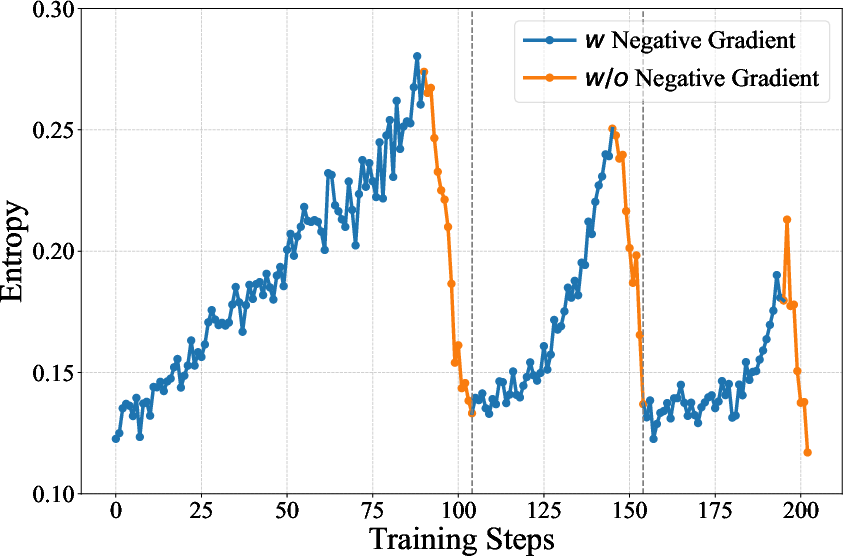
Figure 8: Batch entropy remains stabilized under AEPO—enabling longer, more reliable RL training without collapse.
Memory Management for Ultra-Long Contexts
To transcend the physical context window, QwenLong-L1.5 incorporates a memory agent paradigm: the input sequence is chunked, and at each step the model updates an explicit memory state and plans the subsequent focus of attention. Final answers are generated only after all segments are traversed and memory has implicitly "folded" global context into a compact state. End-to-end RL optimizes the above process over multi-million token sequences.
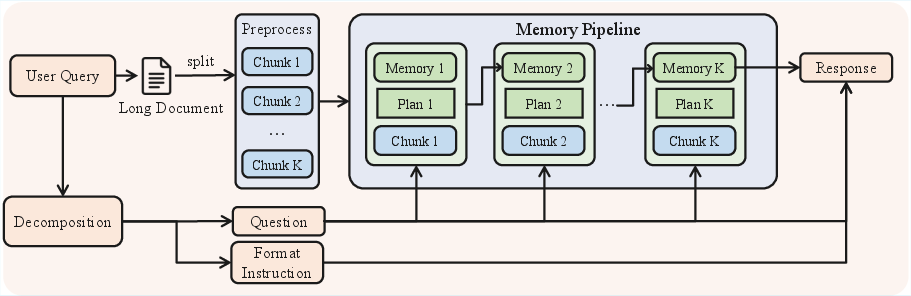
Figure 9: Memory agent workflow—iterative memory and plan updates enable scalable reasoning over chunked ultra-long contexts.
QwenLong-L1.5-30B-A3B delivers strong empirical results across all long-context benchmarks, surpassing or matching the performance of much larger closed models.
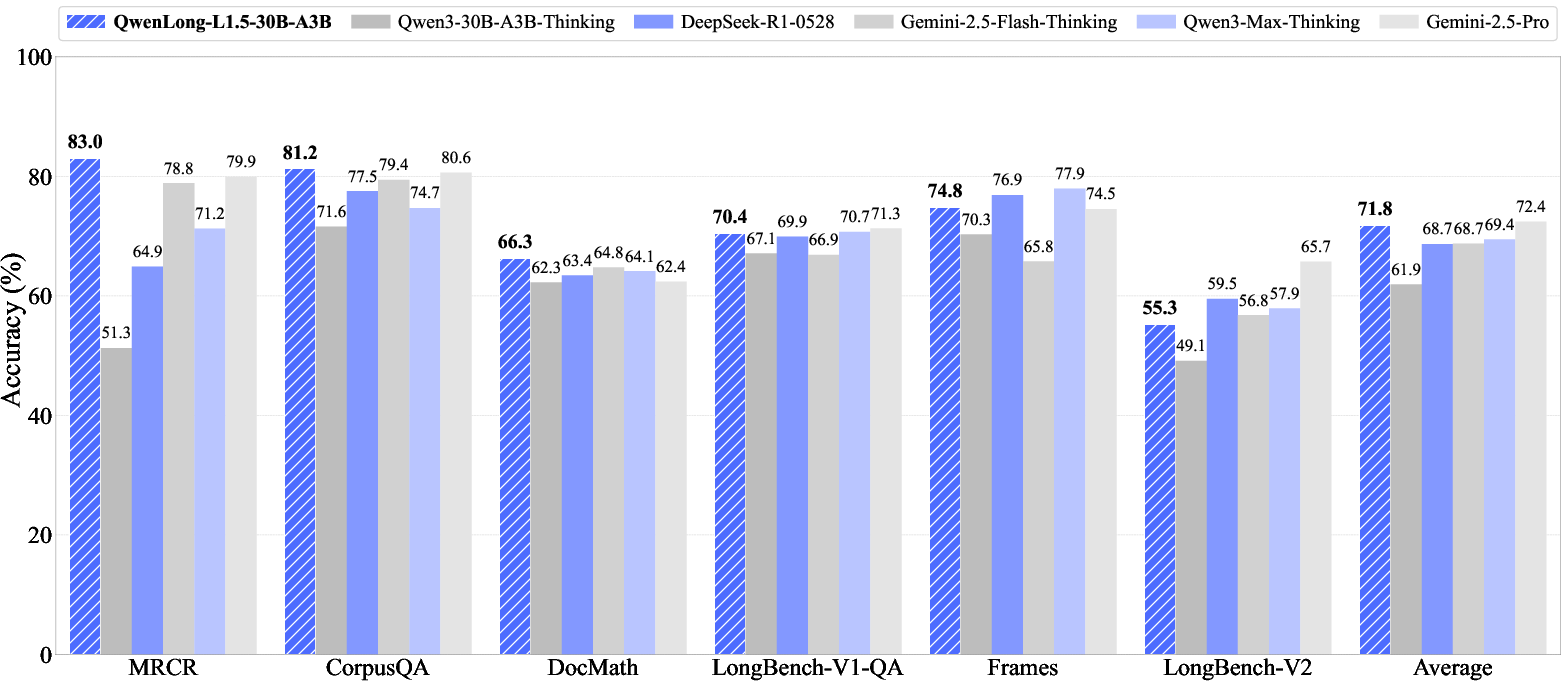
Figure 10: QwenLong-L1.5 achieves 9.9-point average gain over baseline and matches top proprietary models on long-context reasoning tasks.
Implications, Limitations, and Future Directions
QwenLong-L1.5 underscores the necessity of holistic post-training design for reasoning models: data synthesis, RL procedure, and agentic architecture must co-evolve. It is no longer sufficient to extend context at the architectural level—data must target the full spectrum of reasoning primitives, and RL must be explicitly stabilized with task- and entropy-aware controls. The observed positive transfer from long-context training to general tool use, science question answering, and multi-turn dialogue suggests long-context information integration is a portable fundamental skill for LLMs.
Practical limitations remain: synthesizing high-quality long-output (not just long-input) tasks, scaling to multi-modal environments, and developing token-level credit assignment remain open problems. The "data flywheel"—using an enhanced model as its own data generator—offers a path to amortize data curation costs and rapidly scale synthetic corpora.
Conclusion
QwenLong-L1.5 demonstrates that a principled post-training pipeline—combining rigorous data synthesis, robust RL stabilization, and scalable memory-agent design—can yield open models with long-context reasoning at parity with the strongest closed models. The architecture-agnostic methods outlined here are well-positioned for further impact as context requirements, agentic memory tasks, and deployment environments grow in complexity.