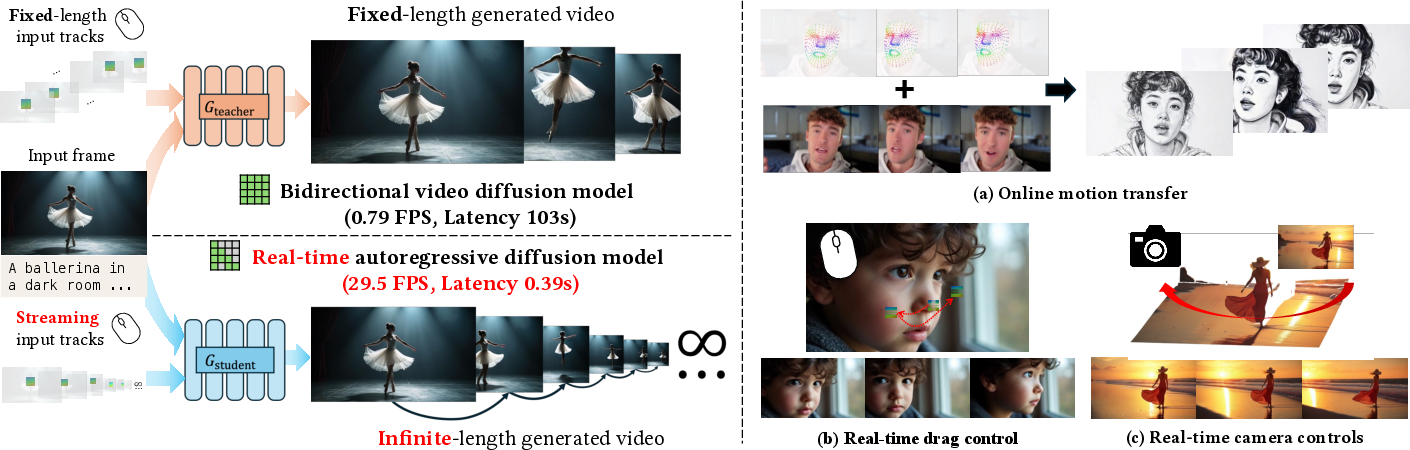
MotionStream: Real-Time Video Generation with Interactive Motion Controls
Abstract: Current motion-conditioned video generation methods suffer from prohibitive latency (minutes per video) and non-causal processing that prevents real-time interaction. We present MotionStream, enabling sub-second latency with up to 29 FPS streaming generation on a single GPU. Our approach begins by augmenting a text-to-video model with motion control, which generates high-quality videos that adhere to the global text prompt and local motion guidance, but does not perform inference on the fly. As such, we distill this bidirectional teacher into a causal student through Self Forcing with Distribution Matching Distillation, enabling real-time streaming inference. Several key challenges arise when generating videos of long, potentially infinite time-horizons: (1) bridging the domain gap from training on finite length and extrapolating to infinite horizons, (2) sustaining high quality by preventing error accumulation, and (3) maintaining fast inference, without incurring growth in computational cost due to increasing context windows. A key to our approach is introducing carefully designed sliding-window causal attention, combined with attention sinks. By incorporating self-rollout with attention sinks and KV cache rolling during training, we properly simulate inference-time extrapolations with a fixed context window, enabling constant-speed generation of arbitrarily long videos. Our models achieve state-of-the-art results in motion following and video quality while being two orders of magnitude faster, uniquely enabling infinite-length streaming. With MotionStream, users can paint trajectories, control cameras, or transfer motion, and see results unfold in real-time, delivering a truly interactive experience.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
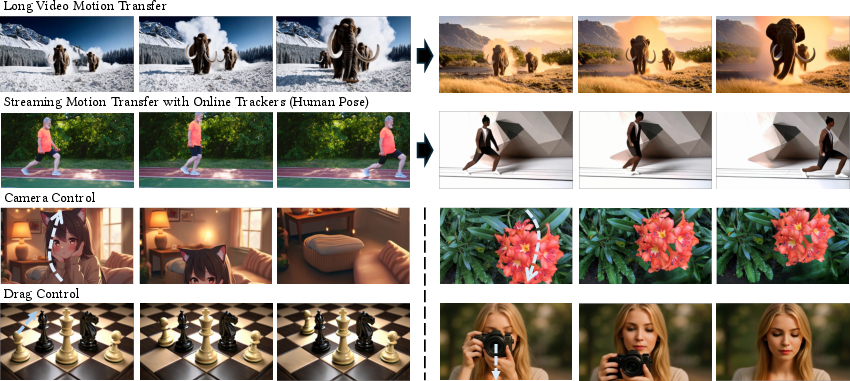
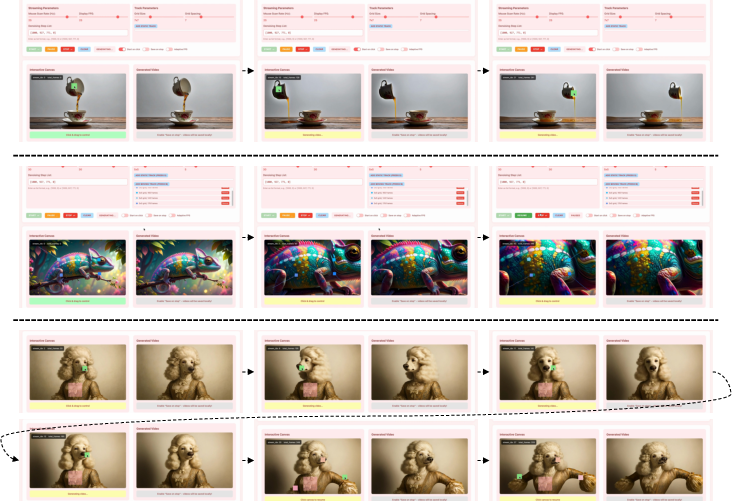
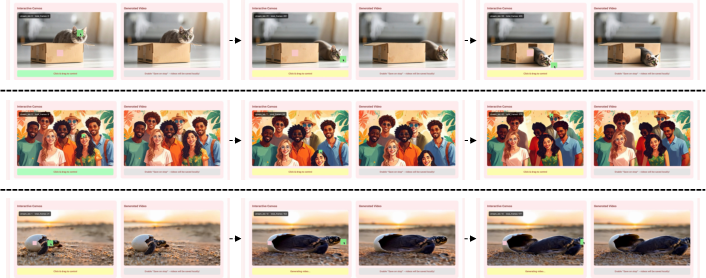
This paper introduces MotionStream, a new way to make videos in real time while you control how things move. Think of it like directing a movie: you can drag objects with your mouse, move the camera, or copy motions from another video, and you see the results immediately instead of waiting minutes.
MotionStream turns slow, “offline” video models into fast, “streaming” ones. It keeps video quality high and follows your motion instructions closely, all at interactive speeds on a single graphics card.
Key Objectives
The paper focuses on a few simple goals:
- Make video generation fast enough to react instantly when a user draws or edits motions.
- Keep videos looking good for as long as you want (not just a few seconds).
- Follow user-specified motion paths accurately, while still allowing natural-looking movement from a text prompt.
- Keep the speed steady, no matter how long the video gets.
How It Works (Methods)
To make this easy to understand, imagine two artists: a careful teacher who works slowly but produces beautiful paintings, and a fast student who learns to paint almost as well, but in real time.
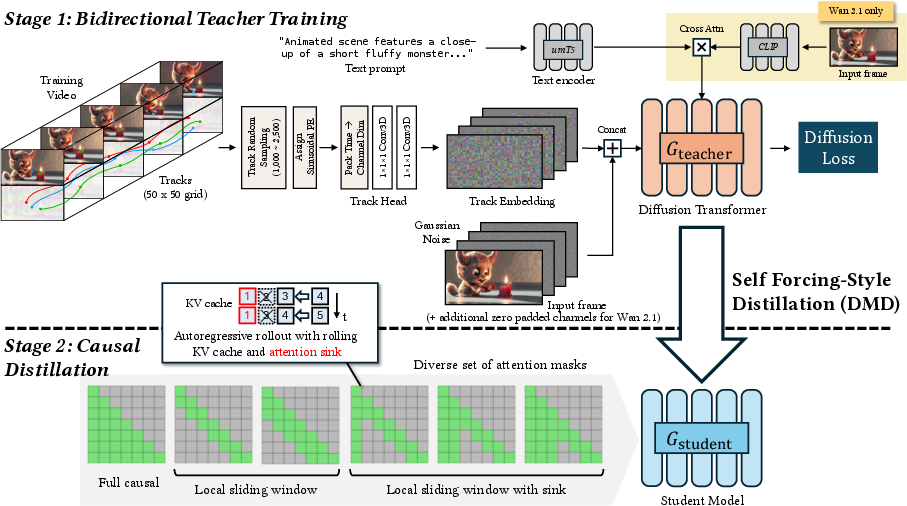
Starting with a “teacher” model
- The team begins with a high-quality video model that can follow both a text prompt (like “a brown dog runs on a beach”) and motion paths you provide (like the path the dog should follow).
- Motion paths are represented as “tracks,” which are just 2D points over time. Each track gets a unique ID turned into a special signal (called “sinusoidal embeddings”) so the model can tell different tracks apart quickly and accurately.
- They combine the tracks, the text prompt, and the starting image, and train the teacher model to produce realistic video clips that match the instructions.
Why this matters: Traditional models often need heavy add-on modules to understand motion and run slowly. Here, the motion control is lightweight and fast, making it easier to use later in real-time.
Training a “student” to be real-time
- The teacher is great but too slow for live control. So they “distill” (teach) a faster, causal student model to imitate the teacher.
- “Causal” means it generates video frame by frame, in order, like flipping a book one page at a time, instead of looking at the entire book at once.
- They use a technique called Self Forcing with Distribution Matching Distillation. In everyday terms: the student practices by generating its own frames chunk by chunk, and the teacher gives guidance to nudge the student’s video toward what a high-quality video should look like.
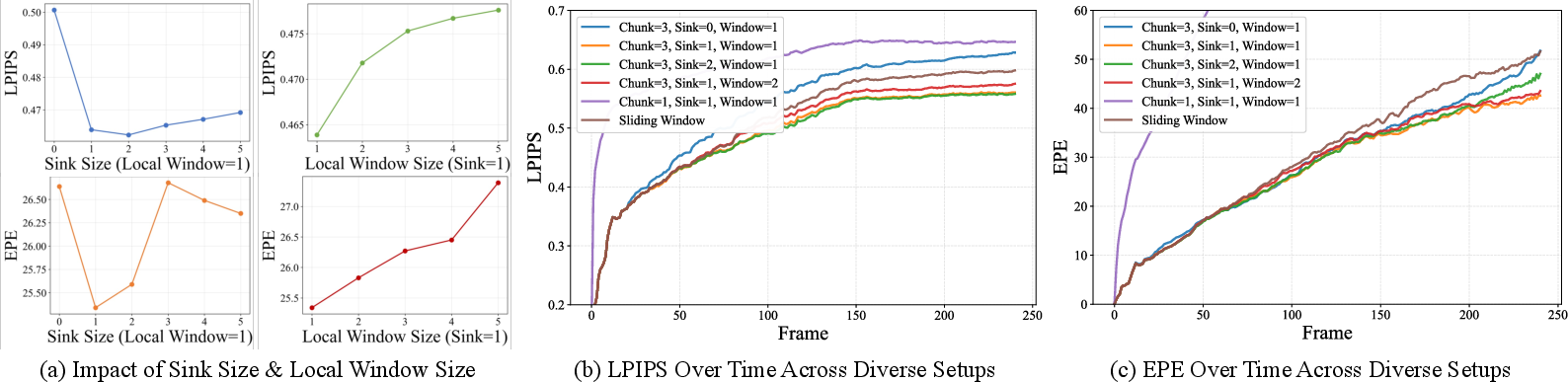
Handling long videos without slowing down or drifting
Making long videos in real time creates three problems: keeping quality high, avoiding errors that pile up, and not getting slower over time. MotionStream solves this with:
- Sliding-window attention: The model focuses mostly on the most recent frames, like remembering the last few steps in a dance so it stays in sync. This keeps speed constant because it doesn’t need to re-check the entire history.
- Attention sink: The model always keeps a strong “anchor” on the very first frame. It’s like pinning the start of a flipbook to the table so the rest of the pages don’t slide around. This prevents the video from drifting off course during long generation.
- Rolling KV cache: This is the model’s short-term memory. As new frames are made, old memory slides out while the anchor and the recent frames stay in. Training simulates this exact behavior so the model is stable during real use.
Together, these tricks let the model stream indefinitely at a constant speed without losing track of motion or style.
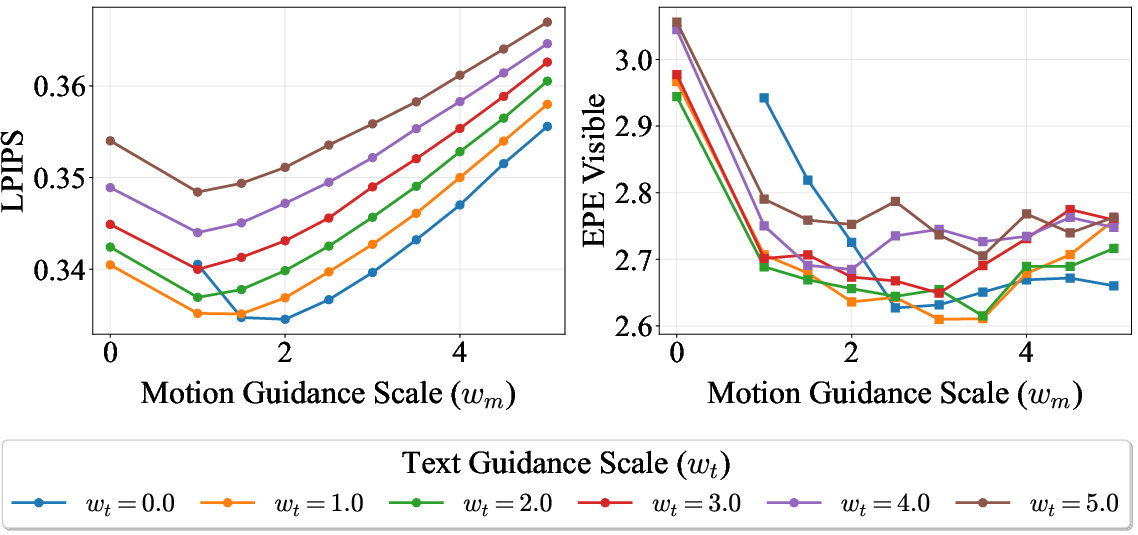
Balancing text and motion guidance
- Text guidance helps the video look natural and adds useful details (like “rainbow in the background”).
- Motion guidance forces objects to follow the paths you paint.
- MotionStream combines both, so you get realism from text plus accurate motion from tracks. This balance helps avoid stiff or robotic-looking movement.
Extra speed with Tiny VAE
- A VAE is the part that turns the model’s internal video representation back into actual images.
- They train a smaller, faster decoder (Tiny VAE) to speed up the final step of turning latent frames into pixels, boosting frame rate even more with minimal quality loss.
Main Findings and Why They Matter
The researchers tested MotionStream on tasks like motion transfer (copying motion from real videos), mouse-based dragging, and camera control. Here’s what they found:
- Real-time speed: It reaches sub-second latency and up to 29 frames per second in streaming mode on a single GPU, which feels interactive.
- Long, stable videos: It can keep generating videos for very long periods without drifting or slowing down, thanks to the attention sink and sliding window.
- High motion accuracy: It follows tracks well, reducing errors between the intended motion and the final video.
- Strong camera control: Without being a 3D model, it beat several 3D view-synthesis baselines in quality and ran much faster.
- Better motion encoding: The sinusoidal track method was both more accurate and far faster than older methods that use an extra image encoder for tracks.
In short, MotionStream is fast, stable, and good at following your motion instructions, making it ready for interactive uses.
Implications and Potential Impact
MotionStream could change how people create videos:
- Artists and creators can “direct” videos live: drag objects, move cameras, and adjust prompts while watching the result immediately.
- Game and virtual world designers can simulate scenes in real time, even in open-ended, photorealistic settings.
- Educators and students can experiment with motion and camera moves without needing heavy hardware or waiting for long renders.
By making motion-controlled video generation fast and interactive, MotionStream turns video creation from a “render-and-wait” process into a live, playful experience.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps and unresolved questions that future work could address to strengthen and extend MotionStream.
- Ambiguity between occlusion and unspecified tracks remains unresolved: the track tensor uses zeros for both cases, and stochastic mid-frame masking only partially mitigates artifacts. Can an explicit visibility/confidence channel or learned occlusion model remove this ambiguity?
- Control signal expressivity is limited to 2D point tracks; the system lacks native 3D controls (e.g., depth-aware trajectories, rotations, skeletal pose, segmentation, flow, or volumetric constraints). How would adding richer control modalities affect quality, latency, and stability?
- Long-horizon claims are not stress-tested at true “infinite” scales; evaluations extend to ~241 frames. What are failure modes over thousands of frames (e.g., identity drift, color shift, cumulative blur), and are periodic refresh/re-anchoring strategies needed?
- Attention sink is permanently anchored to the initial frame; no mechanism is provided for scene cuts, multi-shot sequences, or re-anchoring mid-stream. How should sinks be updated/reset without destabilizing generation?
- Camera control relies on monocular depth plus a global scale alignment, not end-to-end learned geometry. How robust is camera-following under depth errors, and can multi-view consistency or differentiable 3D priors improve geometric faithfulness?
- Robustness to noisy or adversarial control inputs is untested: no stress-test with tracker errors, outliers, or abrupt control perturbations. Can confidence-weighted tracks, outlier rejection, or controller-side filtering improve reliability?
- Scaling limits of track density are unknown: maximum number of simultaneously controlled tracks, confusion between IDs, and computational/memory cost under dense control are not reported.
- Joint text–motion guidance uses fixed weights (w_t=3.0, w_m=1.5); there is no adaptive or learned scheduler that adjusts guidance over time/regions. Can automatic, content-aware weighting or reinforcement learning improve alignment and realism?
- Limited evaluation scope: only PSNR/SSIM/LPIPS/EPE on DAVIS and a curated Sora subset; no human preference studies, FVD/KVD/VBench, or interactive user studies to assess perceived quality, responsiveness, and control fidelity.
- Interaction dynamics are under-characterized: latency jitter, cold-start latency, response to rapid user input changes, and graceful recovery from control mistakes are not measured in live sessions.
- Hardware generalizability is unclear: reported speeds use a single H100 GPU. What is performance, memory footprint, and quality on consumer GPUs (e.g., 4090/4080), laptops, or edge devices?
- Resolution scaling remains limited (480p/720p); 1080p+ streaming quality, latency, and memory overhead are not evaluated. What architectural or decoding changes are needed for higher resolutions at real-time speeds?
- Temporal rate robustness is not studied: behavior under variable FPS, irregular control update intervals, or time warps (speed-ups/slowdowns) is unknown.
- Identity, color, and semantic consistency over long runs are not quantified; no identity preservation metrics or color constancy analyses are reported. How does the model handle subject permanence under long horizons and occlusions?
- Distillation design choices are under-ablated: DMD vs. alternative objectives (consistency distillation, teacher-free strategies, progressive distillation) and their impact on long-horizon stability and speed are not compared.
- Positional encoding in rolling KV caches uses RoPE; alternatives (e.g., ALiBi, dynamic rotary scaling, learned encodings) and their effects on extrapolation stability are not explored.
- KV cache precision/quantization is not addressed: can KV quantization or low-rank compression reduce memory and improve speed without harming quality?
- Physical plausibility and multi-object interaction are unconstrained: collision handling, occlusion reasoning, and scene physics are not modeled; what lightweight priors could mitigate implausible motion?
- Camera-control geometry is not validated with multi-view metrics (e.g., epipolar consistency); outputs may achieve parallax illusions without true 3D consistency.
- Mid-stream edits (adding/removing tracks, changing text prompts) lack smoothing mechanisms: how to avoid flicker or discontinuities when controls change on-the-fly?
- Generalization from synthetic teacher data is uncertain: teacher models are trained on OpenVid-1M plus Wan-generated videos. How well does the system transfer to diverse, real-world handheld footage and out-of-distribution content?
- Tiny VAE trade-offs are only lightly assessed; potential temporal flicker, details loss, and domain biases across content types (fast motion, HDR, low light) are not systematically evaluated.
- Training cost and reproducibility are not reported (compute hours, hyperparameters, seeds, code/data availability), hindering replication and fair comparison.
- Failure-mode taxonomy is missing: conditions that trigger artifacts (e.g., rapid depth discontinuities, large occlusions, sparse tracks) are not cataloged, making it hard to design targeted mitigations.
Glossary
- Attention sink: A set of persistent anchor tokens (e.g., the initial frame) kept in the attention context to stabilize long-horizon streaming generation. "A key to our approach is introducing carefully designed sliding-window causal attention, combined with attention sinks."
- Autoregressive model: A model that generates outputs sequentially, conditioning each step on previously generated results. "MotionStream is an autoregressive model that synthesizes video in a streaming manner, reacting to user-drawn motion trajectories on-the-fly."
- Bidirectional attention: Attention that attends to both past and future tokens in a sequence, enabling non-causal processing. "since diffusion models process the entire sequence in parallel with bidirectional attention."
- Causal attention: Attention restricted to current and past tokens, enabling streaming/AR inference. "We visualize attention probability maps for bidirectional, full causal, and causal sliding window attentions."
- Causal distillation: Distilling a non-causal (bidirectional) teacher into a causal student to enable real-time inference. "we distill this bidirectional teacher into a causal student through Self Forcing with Distribution Matching Distillation, enabling real-time streaming inference."
- Classifier-free guidance (CFG): A guidance technique that mixes conditional and unconditional predictions to steer generation strength without an explicit classifier. "Classifier-free guidance is an effective technique for steering diffusion models."
- Context window: The fixed-size subset of tokens the model attends to at each generation step. "without incurring growth in computational cost due to increasing context windows."
- Diffusion Transformer (DiT): A Transformer-based architecture used as the backbone for diffusion generative models. "We build our motion-guided teacher model on top of the Wan DiT family."
- Distribution Matching Distillation (DMD): A distillation objective that aligns the generator’s distribution with the data distribution via score matching. "Self Forcing with Distribution Matching Distillation"
- End-Point Error (EPE): A motion-tracking metric measuring L2 distance between predicted and reference trajectories. "motion accuracy is assessed via End-Point Error (EPE), computed as the L2 distance between visible input tracks and the tracks extracted from the generated videos."
- Flow matching loss: An objective for flow/diffusion models that trains the network to predict velocity fields along a noise–data interpolation. "which is then trained with a flow matching loss (top)."
- Joint guidance: Combining text and motion guidance in CFG to balance realism and trajectory adherence. "Therefore, we introduce a joint combination for simultaneous text and motion guidance:"
- KV cache: Cached attention keys and values reused across steps to speed autoregressive generation. "by incorporating self-rollout with attention sinks and KV cache rolling during training"
- LPIPS: A learned perceptual similarity metric for evaluating visual quality. "we design and train a smaller VAE decoder with a combination of adversarial loss and LPIPS regressing original VAE's latent space."
- Monocular depth network: A model that predicts scene depth from a single image. "we first estimate scene geometry using a monocular depth network"
- ODE solution pairs: Paired states along an ODE trajectory used to train few-step samplers via regression. "using regression on ODE solution pairs sampled from the teacher."
- PSNR: Peak Signal-to-Noise Ratio, a reconstruction quality metric for images/videos. "Visual fidelity is measured using PSNR, SSIM, and LPIPS~\citep{zhang2018unreasonable},"
- Rectified flow matching: A flow-based training objective using a linear interpolation between data and noise. "We train the motion-guided teacher model through rectified flow matching objective"
- Reverse KL divergence: The divergence D_KL(p_gen || p_data) minimized to align generator and data distributions. "which minimizes the reverse KL divergence between the generator's output distribution and the data distribution:"
- RoPE (Rotary Positional Embeddings): A positional encoding method that encodes relative positions via rotations in attention space. "In our approach, because the KV cache is continuously updated, RoPE values are assigned based on cache position rather than absolute temporal index."
- Self Forcing: A distillation paradigm using autoregressive rollouts and a critic to enable fast causal generation. "Our training pipeline starts from the Self Forcing paradigm"
- Self-rollout: Training-time generation that conditions on the model’s own previously generated outputs to match inference dynamics. "by incorporating self-rollout with attention sinks and KV cache rolling during training"
- Sinusoidal positional encoding: A deterministic encoding mapping positions to sinusoidal vectors for conditioning/identification. "derived from a randomly sampled ID number through sinusoidal positional encoding."
- Sliding-window attention: Causal attention that restricts context to a fixed recent window to keep latency constant. "A key to our approach is introducing carefully designed sliding-window causal attention"
- Track embeddings: Learnable vectors placed at spatial locations to represent 2D motion tracks as conditioning signals. "the input track-conditioning signal c_m ... is constructed by placing visible track embeddings at spatially downsampled locations"
- Track head: A lightweight module that encodes motion track signals into features for the generator. "we find that representing them with sinusoidal embeddings with a learnable track head achieves superior track adherence"
- Variational Autoencoder (VAE): A latent-variable generative model used to encode/decode video frames efficiently. "we design and train a smaller VAE decoder with a combination of adversarial loss and LPIPS"
Practical Applications
Immediate Applications
Below are actionable, real-world uses you can deploy with MotionStream’s current capabilities (real-time, streaming, motion-controlled video generation with sub-second latency on a single GPU; 480p/720p at 17–10 FPS, up to 29 FPS with Tiny VAE), along with target sectors, potential tools/workflows, and key assumptions.
- Real-time motion-controlled video editing and animation in creative suites (Software/Media/Entertainment)
- Use cases: drag-to-animate a subject from a still image; transfer motion from a reference clip; paint trajectories; preview edits live; interactive camera moves from a single photo.
- Tools/workflows: After Effects/Premiere/DaVinci/Nuke plugin; “Animate from Still” in Photoshop-like apps; MotionStream SDK for track painting and joint text-motion prompting; live preview with streaming export.
- Assumptions/dependencies: high-end GPU (e.g., A100/H100-class or cloud instance); robust track extraction (e.g., CoTracker3) and optional depth estimation; UI for track visibility/occlusion disambiguation; content safety/watermarking in production.
- Live broadcast and streaming graphics (Media/News/Sports)
- Use cases: on-air animation of stills; quick virtual camera moves on press photos; real-time motion overlays for highlights/recaps.
- Tools/workflows: OBS/VMix plugin; newsroom control panel to paint camera paths and render in <1 s latency; Tiny VAE for FPS boost.
- Assumptions/dependencies: reliable 720p quality acceptable for broadcast lower-thirds/insets; moderation/watermarks for synthetic content; GPU availability in the control room.
- Interactive previsualization (previz) for film, TV, and commercials (Media/Entertainment)
- Use cases: storyboard-to-animatic; iterate camera paths and subject motion live in reviews; “what-if” exploration with text-conditioned dynamics (e.g., weather changes).
- Tools/workflows: previz app with track painting and camera control; depth + COLMAP-based camera trajectory interpolation; instant scene blocking iterations.
- Assumptions/dependencies: monocular depth accuracy affects camera plausibility; creative teams accept photorealistic but non-physical dynamics; central GPU server for collaborative sessions.
- Social content creation and mobile companion experiences (Daily Life/Consumer Apps)
- Use cases: animate photos with finger-drag; personalize posts with motion transfer from trending clips; meme animation from a single image.
- Tools/workflows: smartphone app with cloud inference; simple “drag and prompt” UI; template library of preset trajectories.
- Assumptions/dependencies: mobile on-device compute likely insufficient; server-side inference with latency budgets; usage caps/cost controls; safety filters.
- UI/UX motion prototyping (Software/Design)
- Use cases: turn static screens into motion mocks; articulate micro-interactions or transitions via trajectory painting.
- Tools/workflows: Figma/Framer plugin; export lightweight videos or GIFs for stakeholder review; joint text-motion for secondary dynamics.
- Assumptions/dependencies: cloud API; designers provide clear motion intent; licensing for generated assets determined by organization policy.
- Game cinematics and animatics prototyping (Gaming/Software)
- Use cases: rapid “look dev” for cutscene angles, blocking, and motion beats from concept stills; interactive pitch videos.
- Tools/workflows: Unreal/Unity integration; camera path authoring with streaming previews; export reference clips for downstream animation teams.
- Assumptions/dependencies: outputs are visual guides (non-physical); pipelines handle versioning and asset provenance.
- E-commerce product videos from single images (Retail/Marketing)
- Use cases: micro-orbits, parallax, or dolly moves around a product shot; subtle motion accents for PDPs and ads.
- Tools/workflows: CMS-integrated service that ingests product images, applies depth + camera track presets, and returns short looping videos.
- Assumptions/dependencies: monocular depth errors on reflective/transparent items; human QC for flagship products; watermarking/disclosure policies.
- Education and training content authoring (Education)
- Use cases: quickly animate diagrams or scenes to teach motion/camera principles; classroom demos where students draw trajectories and see results immediately.
- Tools/workflows: web app with drawing pad for tracks; prompt templates for lesson plans; export to LMS.
- Assumptions/dependencies: non-physical plausibility is acceptable for visual explanation; school IT uses managed cloud GPU resources.
- Motion-augmented data for vision research (Academia/ML)
- Use cases: generate motion-conditioned sequences from labeled stills for pretraining; stress-test trackers/segmenters with controlled trajectories.
- Tools/workflows: scriptable API to sweep trajectory grids; automatic track visibility masks; metadata logging for synthetic provenance.
- Assumptions/dependencies: potential domain shift vs. real video; rights for training/evaluation; documentation of synthetic generation parameters.
- Accessibility-first creative assistance (Daily Life/Assistive Tech)
- Use cases: creators with limited motor function specify motion via simple clicks/short strokes and text prompts; automated consistency across shots.
- Tools/workflows: simplified UI modes; autocorrect of ambiguous tracks; voice prompts for motion intents.
- Assumptions/dependencies: robust defaults and recovery (e.g., mid-frame masking to avoid popping); safe prompting; cloud runtime.
- Lower compute cost for video-gen workflows (Energy/Green IT/Operations)
- Use cases: replace multi-minute offline diffusion renders with causal student at constant latency; scale to more iterations within the same power budget.
- Tools/workflows: internal creative pipelines switch to MotionStream student + Tiny VAE for draft/iteration phases; fallback to teacher for hero shots.
- Assumptions/dependencies: measure power/FPS vs. baseline diffusion; quality trade-offs deemed acceptable for iterative stages.
- Real-time API/SaaS for interactive motion control (Software/SaaS)
- Use cases: product teams embed “animate from still” into their apps; WebSocket streaming previews; pay-per-minute usage.
- Tools/workflows: REST/WebSocket endpoints: upload image + tracks + prompt -> stream; autoscaling on GPU fleets; content moderation gates.
- Assumptions/dependencies: concurrency planning; GPU scheduling; logging for provenance and audit trails.
Long-Term Applications
These ideas are feasible but need further research, integration, or hardware scaling (e.g., stronger on-device accelerators, better depth/geometry, stronger safety/consistency controls).
- AR/VR interactive cinematography and storyboarding (XR/Media)
- Vision: users move controllers to define camera paths around a still scene; immersive previews for directors and educators.
- Potential product: VR previsualization suite powered by MotionStream; real-time trajectory painting in 3D space.
- Assumptions/dependencies: on-device acceleration; improved depth/scene priors; latency <20 ms motion-to-photon; robust long-horizon stability.
- Live interactive avatars and characters (Media/Communications)
- Vision: combine with audio-driven models to animate portraits or characters with natural gestures from sparse user controls.
- Potential product: streaming avatar service for creators and customer support personas; gesture tracks + audio prompt.
- Assumptions/dependencies: identity preservation, lip sync, and safety; consistent long-duration behavior; licensing constraints.
- Real-time generative cutscenes and dynamic NPC vignettes (Gaming)
- Vision: adaptive story moments rendered on-the-fly based on player input; directors “draw” trajectories for cinematic reveals.
- Potential product: engine middleware generating in-situ cutscenes; authoring tools expose trajectory constraints and text beats.
- Assumptions/dependencies: temporal consistency guarantees; content moderation; deterministic seeds for QA; player comfort.
- Telepresence/teleoperation visualization (Robotics/Telecom)
- Vision: predictive visualizations from a single frame to mitigate network delay; operator draws intended motion to preview expected views.
- Potential product: operator HUD overlay generating view previews; interactive camera planning in constrained spaces.
- Assumptions/dependencies: not for safety-critical decisions; non-physical hallucination risk; calibration with real sensor feedback.
- Synthetic data engines for perception and policy learning (Robotics/Autonomy/Academia)
- Vision: large-scale motion scenarios generated from static imagery for pretraining trackers/segmenters; curriculum with controllable occlusions.
- Potential product: “MotionBench” generator with labeled tracks/visibility masks; evaluation harness for long-horizon drift.
- Assumptions/dependencies: quantify domain gap; standardized metadata; licensing; alignment with benchmark protocols.
- Personalized advertising at scale and automated A/B pipelines (Marketing/Finance)
- Vision: thousands of video variants from product stills conditioned on audience, copy, and trajectories.
- Potential product: campaign engine integrating PIM/DAM, prompt libraries, and compliance checks; real-time previews for marketers.
- Assumptions/dependencies: brand safety, IP clearance; watermarking/disclosure; guardrails for sensitive content; cost controls.
- Interactive educational simulators and labs (Education/EdTech)
- Vision: visually rich, user-driven motion/camera exercises; students draw controls to explore scene storytelling and composition.
- Potential product: courseware integrating trajectory tasks and instant feedback; rubric-based assessment of motion alignment.
- Assumptions/dependencies: non-physical but pedagogically valid; age-appropriate content filters; classroom-scale GPU access.
- Provenance and watermarking-by-design for streaming AI video (Policy/Governance/Standards)
- Vision: standardized, robust real-time watermark insertion and C2PA provenance at generation-time.
- Potential product: compliance SDK that tags frames during streaming; verification service for platforms/advertisers.
- Assumptions/dependencies: watermark robustness research; regulatory requirements; platform adoption.
- Edge/consumer deployment on GPUs/NPUs (Hardware/Edge AI)
- Vision: run at usable FPS on consumer GPUs or mobile NPUs via quantization, pruning, FlashAttention-3, and Tiny VAE-like decoders.
- Potential product: SDK profiles (server, desktop, mobile) with model variants; auto-select chunk/window sizes for stability vs. speed.
- Assumptions/dependencies: memory footprint optimization; thermal/power limits; integer quantization effects on quality.
- Real-time content moderation for generative video (Policy/Safety/Platform Ops)
- Vision: streaming moderation models that monitor prompts and frames; block/flag policy-violating content mid-generation.
- Potential product: “inference-side” guardrails with rollback/recover mechanisms; audit logs tied to trajectories and prompts.
- Assumptions/dependencies: low-latency detectors; false positive/negative management; user redress processes.
- Multi-user collaborative directing (Software/Productivity/Creative Platforms)
- Vision: several collaborators paint trajectories and prompts simultaneously; version control for motion “branches.”
- Potential product: cloud studio with shared timelines; per-user layers and locking; review/playback with annotations.
- Assumptions/dependencies: real-time synchronization; conflict resolution in motion directives; scalable GPU orchestration.
- 3D/4D content bootstrapping (3D/VFX/Robotics)
- Vision: use multi-view-like sequences from single images to seed NeRF/GS pipelines for rough 3D assets or scene proxies.
- Potential product: “2.5D-to-3D” bootstrapping assistant; consistency scoring and cleanup tools.
- Assumptions/dependencies: view-consistency remains a challenge; bias from generative hallucinations; downstream cleanup required.
- Healthcare communication and rehab engagement content (Healthcare/Patient Education)
- Vision: animate medical diagrams or rehab exercises from a still; therapists specify target limb trajectories for patient-friendly videos.
- Potential product: clinic content generator with curated prompt templates; export to patient portals.
- Assumptions/dependencies: clinical validation; strict content oversight; data privacy; accessibility requirements (captions, descriptions).
Notes on feasibility across applications
- Performance depends on hardware: reported 17 FPS (480p) and 10 FPS (720p) on a single H100; up to 29 FPS with a Tiny VAE. Consumer devices will likely need cloud inference or further optimization.
- Stability for infinite-length streams is improved via attention sinks and KV cache rolling, but extremely long, complex scenes still risk drift; window/sink settings affect quality and latency.
- Camera control quality depends on monocular depth and pose alignment; reflective/transparent or highly dynamic scenes are harder.
- Track visibility ambiguity can produce popping without careful UI or masking; the paper’s stochastic mid-frame masking mitigates but does not eliminate this risk.
- Joint text-motion guidance introduces flexibility but also requires prompt moderation and brand/content safety policies.
- IP, licensing, and provenance: training data sources and synthetic generation must comply with organizational/legal standards; adopt watermarking and C2PA provenance for deployments.
Collections
Sign up for free to add this paper to one or more collections.