- The paper introduces an LLM-based re-ranking framework that enhances explainability and fairness in recommendation systems by generating natural language explanations for ranked items.
- It leverages candidate generation from traditional recommenders combined with advanced fine-tuning (SFT, DPO, and NEF) to mitigate bias and improve ranking metrics such as NDCG and Hit Ratio.
- Experimental results on random baselines show significant gains in accuracy and reduced popularity bias, demonstrating the practical impact of integrating LLMs into recommendation workflows.
LLMs as Explainable Re-Rankers for Recommendation Systems
Problem Statement and Motivation
The lack of explainability and fairness in prevalent recommendation systems remains a paramount issue, as such systems tend to optimize for accuracy at the expense of transparency and individualization. Traditional recommenders are often subject to popularity bias, privileging frequently interacted items and systematically marginalizing niche preferences. LLMs, while offering promising advances in interpretability via natural language, are typically less precise than specialized recommendation algorithms when utilized for prediction tasks. The presented work advances the state of the art by introducing LLMs as explainable re-rankers, combining the robustness of traditional recommenders with the interpretability and adaptiveness of LLM architectures.
Framework Architecture
The methodology is distinguished by several key innovations. First, candidate items are generated using traditional recommendation algorithms including collaborative filtering (e.g., SVD), knowledge graph-based methods (RippleNet), and random retrieval, ensuring candidate diversity. These candidates are then subjected to an LLM re-ranking process which is explicitly trained to produce both accurate rankings and coherent, user-aligned explanations.
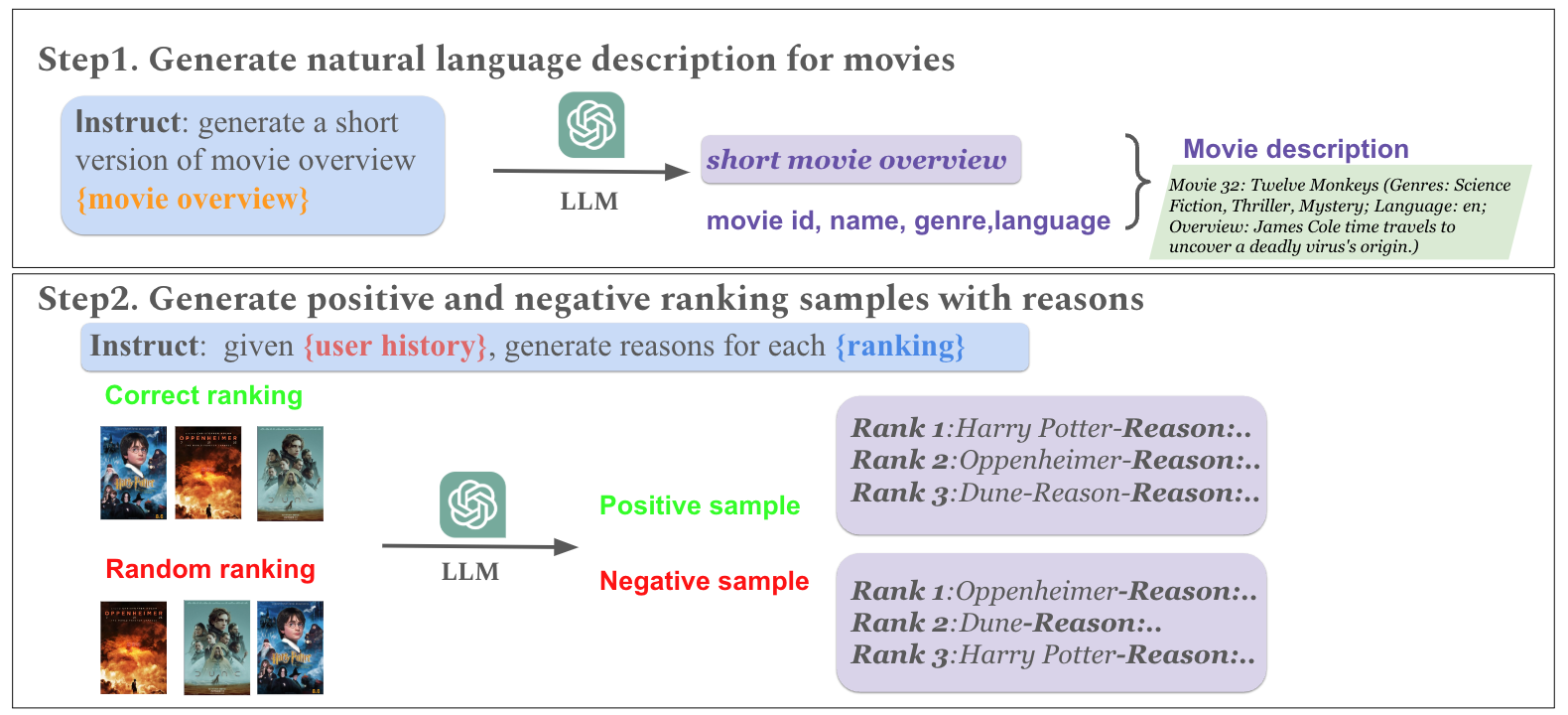
Figure 1: Design of the data extraction and construction pipeline for generation of training samples for LLM-based ranking/explanation.
The data construction leverages condensed movie summaries and explicit user histories, forming training samples with positive (correct) and negative (incorrect) rankings, the latter produced via permutation-based bootstrapping. This approach mitigates position bias and facilitates robust representation learning in the LLM. SFT (Supervised Fine-Tuning) primes the model with structured examples and prompt conditioning. Subsequently, Direct Preference Optimization (DPO), enhanced with RPO (Reward-Preference Optimization) weights, dynamically refines the margin between preferred and rejected rankings. NEF (Noisy Layer Fine-Tuning) is employed within SFT to protect against overfit and support generalization across data regimes.
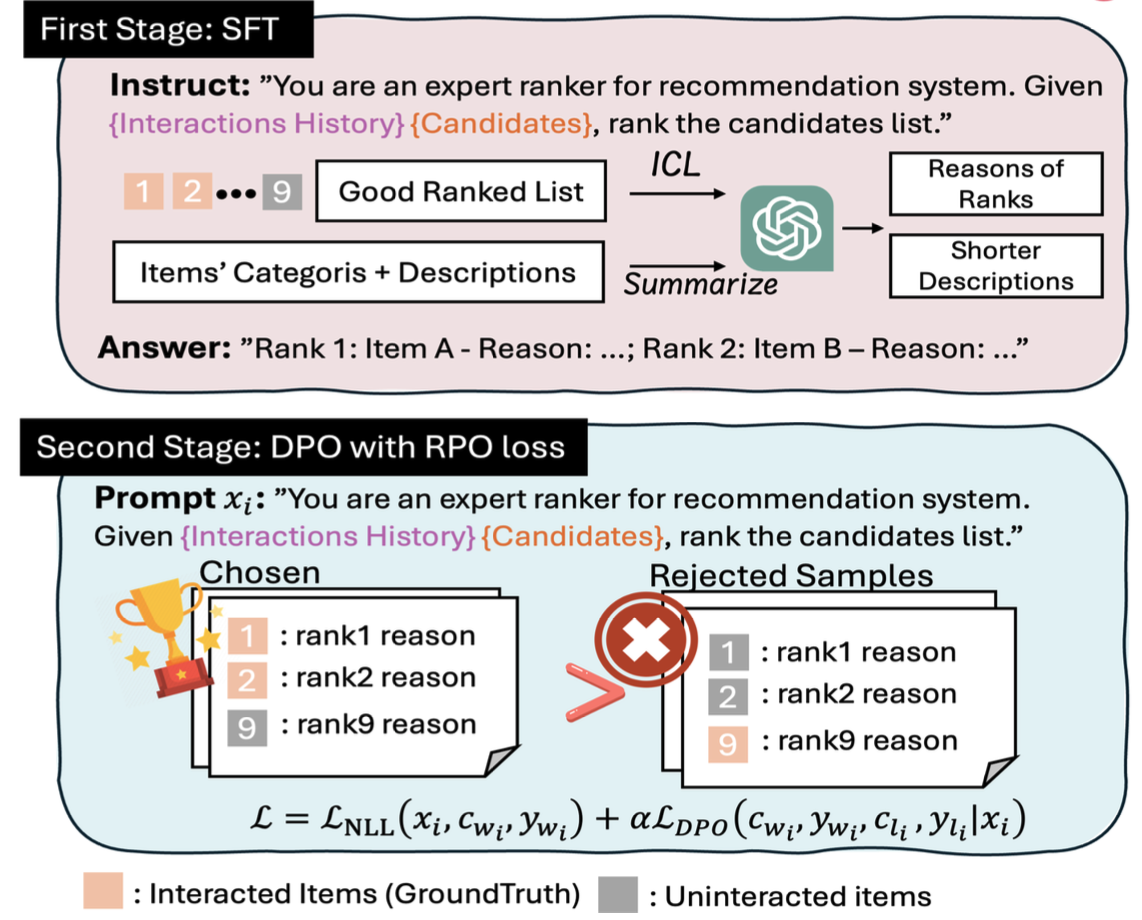
Figure 2: Training pipeline integrating SFT and DPO/RPO stages, enabling both ranking competence and explainability.
Inference and Bias Mitigation
During inference, user history and candidate lists are presented to the model. Candidate lists are shuffled to alleviate popularity and positional bias. Multiple bootstrapped reorderings are processed, and a self-consistency module aggregates ranked outputs by summing positional indices, thereby generating a final, robust top-N recommendation list. Explanations are generated for each recommended item, leveraging the contextual synthesis learned during fine-tuning.
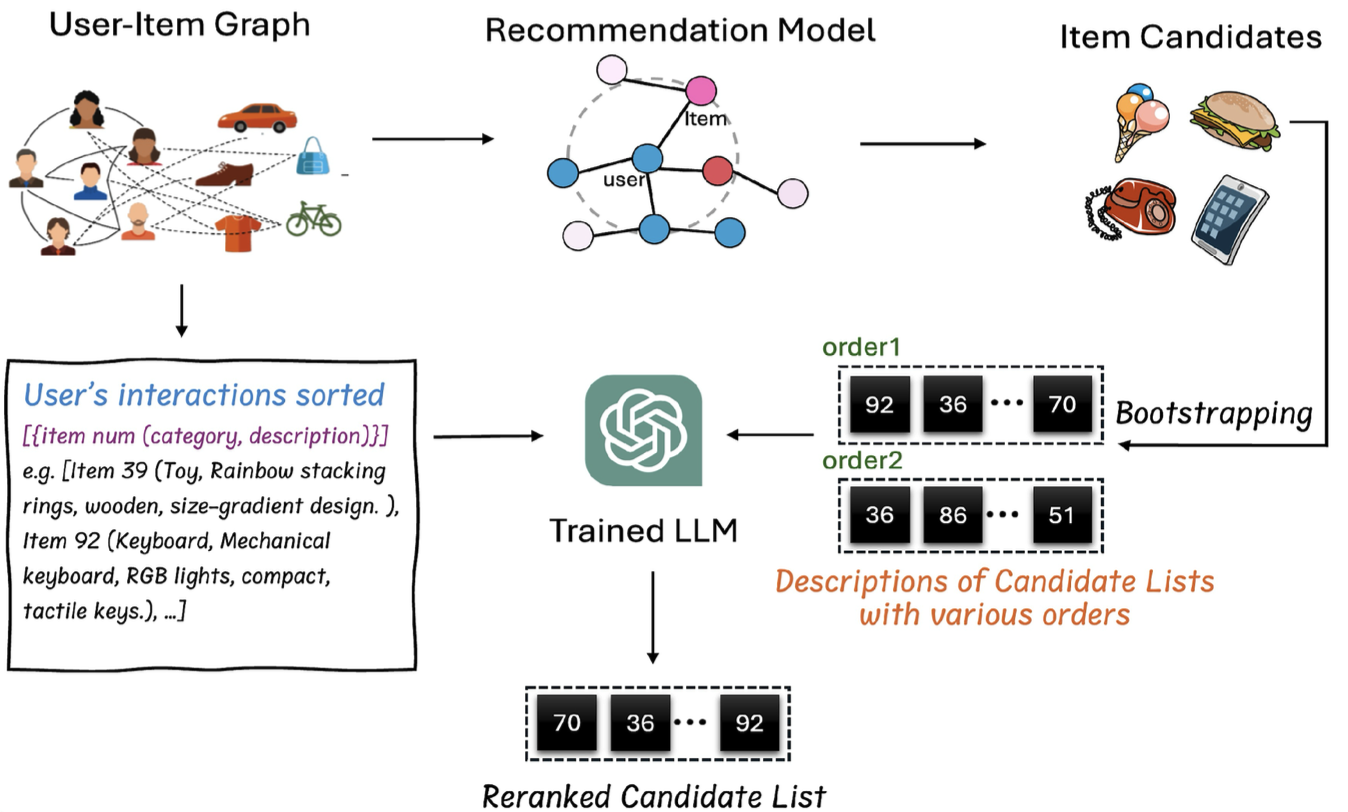
Figure 3: The deployed inference pipeline—LLM as a re-ranker utilizing bootstrapping and self-consistency for debiased rankings and explainability.
Experimental Analysis
Rigorous empirical evaluation was conducted over multiple retrieval paradigms (random, collaborative, graph-based). For weaker base recommenders (random, item-based CF), the LLM re-ranker produced statistically significant improvements in NDCG@3/5/10, Hit Ratio, Recall, and Precision, with p-values consistently below the 0.05 threshold. The strongest relative improvements are attained on random baselines, where the SFT-DPO pipeline elevates NDCG@3 from 0.3679 (non-ranker) to 0.5287, and Hit Ratio@3 from 0.7381 to 0.9167. For more robust recommendation bases incorporating knowledge graph context, marginal or non-significant gains were observed, indicating diminishing returns for LLM re-ranking in the presence of rich item relational data.
Explainability was evaluated via human assessments on a 5-point Likert scale. The SFT-DPO model generated reasons scored at 4.3 on average, surpassing the zero-shot baseline (3.6). Paired t-tests confirmed the statistical significance (p<0.01) of the gains. Explanations produced by the fine-tuned model exhibited comprehensive contextualization, integrating not only genre matching but also high-level narrative analysis and explicit user-history summarization.
Implications and Limitations
The hybrid LLM re-ranking approach demonstrably improves both accuracy and interpretability, particularly for baseline recommenders lacking domain-specific contextual richness. However, there exists a ceiling effect when re-ranking outputs from strong graph-based models; LLMs fail to fully exploit the embedded graph structure, pointing to an architectural bottleneck. Integrating graph encoder representations as prefix tokens to the LLM, as suggested in recent work [he2024g], may facilitate deeper relational reasoning and unlock further performance gains.
Another notable limitation lies in dataset construction and human alignment. While t-tests confirm no significant difference between LLM-generated and manually curated data, the limited sample size suggests new methodologies are needed for large-scale, robust dataset quality assurance.
Prospective Directions
Future research should focus on the seamless integration of symbolic graph reasoning into language modeling, potentially through vectorized subgraph encodings or joint representation learning. Evaluation protocols for explainable recommendation must also mature—moving beyond Likert scales to more granular attribution tracing and causal reasoning metrics. There is also scope for enhancing the diversity of explanation modalities, such as counterfactual reasoning or contrastive rationales, thereby promoting user trust and system transparency.
Conclusion
The presented work establishes LLMs as competitive, explainable re-rankers for recommendation systems, outperforming baseline and zero-shot models in both ranking performance and explanation quality for less context-rich candidates. However, the integration of complex knowledge structures remains an open challenge. These findings lay the groundwork for future research in explainable, user-centric recommendations that leverage both statistical and semantic modeling paradigms.

