- The paper introduces Inferix, which applies a novel block-diffusion (semi-autoregressive) framework leveraging KV cache management to enable arbitrarily long, coherent video generation.
- The paper employs parallel inference strategies and distributed GPU techniques to address high computational and memory demands in high-resolution video synthesis.
- The paper integrates real-time streaming, interactive control, and built-in profiling to support dynamic simulation and rigorous benchmarking of long video sequences.
Inferix: A Block-Diffusion based Next-Generation Inference Engine for World Simulation
Introduction
The rapid development of large-scale world models for video generation demands new inference paradigms tailored to the distinct requirements of physically consistent, high-resolution, and minute-long video synthesis. The paper "Inferix: A Block-Diffusion based Next-Generation Inference Engine for World Simulation" (2511.20714) introduces Inferix, a specialized inference engine architected for block diffusion (semi-autoregressive) frameworks, fundamentally distinct from classic fully autoregressive (AR) or bidirectional diffusion models. Inferix is explicitly designed for next-generation immersive world simulation, equipped with advanced inference, streaming, and benchmarking components to extend the capabilities and scalability of state-of-the-art video generative models.
Motivation and Paradigm Shift
Traditionally, video diffusion models mostly followed bidirectional paradigms (e.g., DiT), which support high parallelism but lack KV cache management, restricting variable-length generation and efficiency. In contrast, AR-based frameworks reintroduce KV caching but sacrifice quality and parallelizability. Block diffusion, or semi-autoregressive decoding, interpolates between these extremes by generating video in blocks—leveraging the context from previous blocks via KV cache—enabling both efficient, coherent, and arbitrarily long video synthesis.
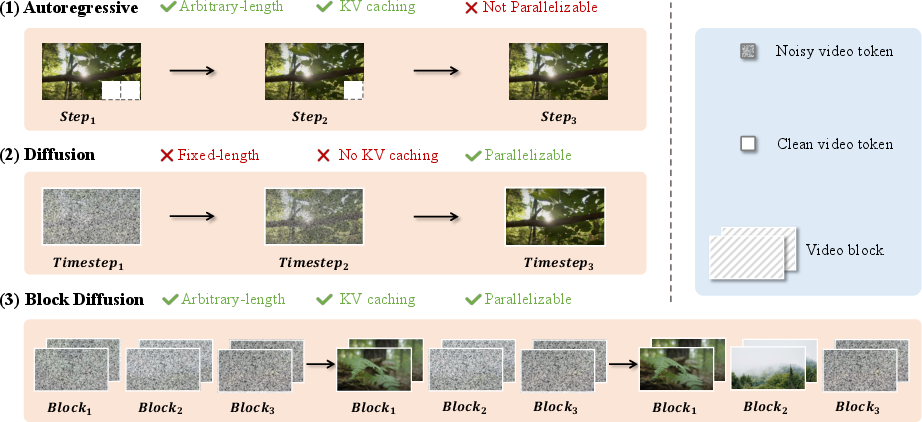
Figure 1: Block Diffusion combines autoregressive and diffusion strengths, offering KV caching, arbitrarily long video generation, and intra-block parallelism.
This paradigm reintroduces LLM-style KV cache management and positions block diffusion as the optimal strategy for sustained and consistent world modeling—an essential component for agentic AI, simulation, and advanced content creation.
Architecture and Core Components
Inferix’s core architectural innovation lies in an optimized, model-agnostic framework that generalizes the semi-autoregressive block diffusion pipeline, introducing the following major subsystems:
- Parallel Inference Strategies: To alleviate the substantial computational and storage load associated with long-form, high-resolution video inference, Inferix integrates a suite of distributed and sequence-parallel techniques (e.g., Ulysses-style sequence parallelism, ring attention) supporting blockwise workload partitioning across GPUs and node clusters.
- Advanced KV Cache Management: A unified interface abstracts block-wise KV cache storage, supporting efficient memory access patters (e.g., sliding window, selective chunked access, index-based fetching), flexible offloading, and future extension for multi-latent attention models.
- Flexible Model Abstraction and Pipelines: The system accommodates a broad set of block diffusion models (MAGI-1, CausVid, Self Forcing), allowing rapid integration of custom backbone architectures with minimal modification.
- Built-in Profiling: The profiler collects fine-grained resource utilization and user-defined metrics at minimal overhead, supporting scalable optimization and diagnosis.
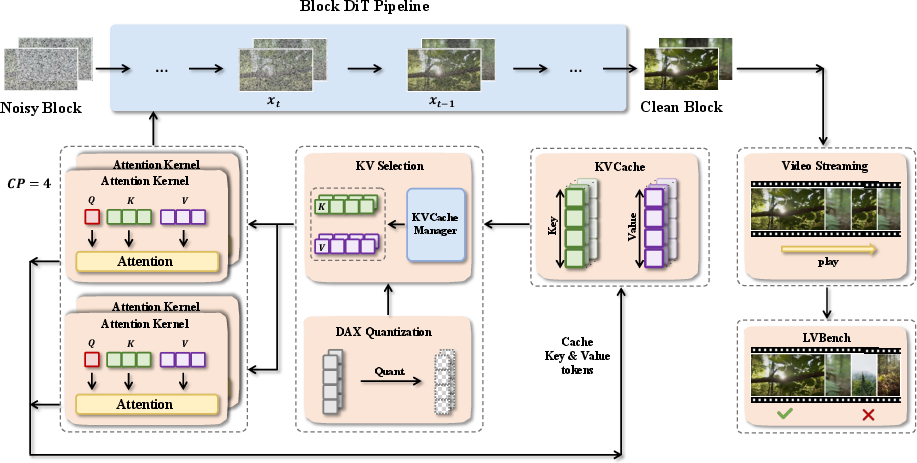
Figure 2: INFERIX augments block diffusion with parallelism, advanced caching, quantization, streaming, and evaluation pipelines.
This modular design establishes Inferix as both a unified inference interface for model developers and a scalable, efficient engine for deployment.
Inference and Simulation Challenges
Long-form world simulation inherently amplifies storage and computation challenges. Managing KV caches for each video block imposes significant GPU memory overhead, especially as previous block context must be retained to prevent drift and forgetting—crucial for long-horizon temporal consistency. Inferix employs a combination of cache compression, offloading, dynamic access scheduling (e.g., PagedAttention, sliding context), and quantization (e.g., DAX) to minimize hardware bottlenecks and improve throughput.
For computation, parallel attention mechanisms, reduction of denoising steps, quantization, and inference-time redundancy elimination are critical for scaling up to minute-long video synthesis on available GPU clusters.
Support for Streaming and Interactive Control
Inferix extends beyond simple video decoding by providing native video streaming capabilities (RTMP, WebRTC). This enables real-time, interactive world simulation where users or agents can issue dynamic prompts, alter narratives, or inject controlled events into the generation process. Inferix supports clearing and resetting cross-attention caches at user-defined prompt transitions, ensuring segment-specific control and eliminating prompt bleed-over.
LV-Bench: Long Video Benchmarking
To address the lack of rigorous benchmarks for long video generation, Inferix integrates LV-Bench, a curated dataset and evaluation protocol specifically targeting minute-long, high-fidelity video. The dataset itself is constructed from a heterogeneous mix of open-source sources (DanceTrack, GOT-10k, HD-VILA-100M, ShareGPT4V), processed through rigorous human-in-the-loop validation, and expands on prior short video benchmarks with denser and temporally diverse linguistic annotations.
The evaluation protocol expands classic metrics with the Video Drift Error (VDE) family, directly quantifying temporal consistency, sharpness drift, background stability, and subject identity preservation across long video horizons. This unified protocol, including five VDE-based metrics and extended VBench dimensions, enables precise, granular assessment of model performance over extended temporal scopes, revealing weaknesses in both quality and drift.
Practical and Theoretical Implications
Inferix addresses a critical gap in scaling world model inference for real-world, agentic, and simulation-based applications. Practically, it allows developers and researchers to deploy block-diffusion models for tasks such as agent training, embodied AI simulation, interactive gaming, and long-form content creation—with fine-grained, real-time control and profiling. Theoretically, its framework manifests a shift away from monolithic AR or pure diffusion architectures, underscoring the effectiveness of hybrid (semi-AR/block-diffusion) designs augmented by modern memory management and parallelism.
By formalizing KV cache management and integrating efficient profiling and distributed execution strategies into the core inference pipeline, Inferix makes new classes of inference-time adaptation and interactive simulation viable at production scale.
Future Directions
The roadmap for Inferix includes investigation into block-sparse attention, advanced KV cache features, more sophisticated distributed and high-concurrency deployment strategies, step distillation, and higher-fidelity real-time streaming. Notably, the system’s extensibility is designed to accommodate rapid advances in both backbone model architectures and inference optimization techniques emerging from both the LLM and video generation domains.
Conclusion
Inferix sets a new technical foundation for world simulation via block-diffusion by unifying and generalizing inference, cache management, benchmarking, and streaming into a scalable engine. Its design explicitly targets the operational and research requirements of next-generation video generative models, supporting efficient and extensible long video synthesis. The integration of LV-Bench further enables rigorous, multi-dimensional evaluation, facilitating transparent comparison and rapid iteration. As block diffusion models continue to gain prominence, systems like Inferix will be vital to both research progress and practical deployment.

