- The paper introduces a novel reduction from multi-turn RL to iterative single-turn PPO, optimizing conversational outcomes using sparse, business-oriented rewards.
- It employs Monte Carlo rollouts to estimate a response-level Q-function, enabling token-level PPO that guarantees monotonic policy improvement.
- The framework leverages standard RLHF toolchains for deployment in outcome-driven applications, such as e-commerce sales and customer support.
Aligning LLMs Toward Multi-Turn Conversational Outcomes Using Iterative PPO
Introduction and Motivation
This paper formally defines and addresses the outcome-driven multi-turn conversational AI problem, focusing on applications requiring the optimization of long-term, trajectory-level objectives, specifically in settings such as sales assistance within e-commerce. Rather than merely generating plausible next-turn responses, the proposed framework aims to maximize sparse rewards that depend on the successful completion of business-oriented conversational goals (e.g., lead acquisition, purchase completion) over an entire dialogue. This is instantiated through the Suggested Response (SR) problem, highlighting the setting where an LLM agent suggests responses to business users, who may accept, edit, or reject the suggestions before sending them to customers.
The technical contributions articulate a reduction from multi-turn RL to a series of single-turn RL problems and propose an Iterative PPO algorithm that operationalizes this reduction, enabling effective on-policy batch-learning with standard RLHF toolchains.
The SR problem is modeled as a discrete-time episodic MDP, with states capturing the full conversational history (customer messages, SR agent's suggestions, business responses, and outcome flags) and actions corresponding to suggestions generated by the SR agent. The reward structure reflects binary, sparse feedback—nonzero only when the business’s target outcome is achieved. The agent's policy must therefore learn to plan over long-term dialogue histories, rather than optimize myopic, turn-level objectives.
A fundamental characteristic of the SR framework is that the SR agent's actions influence but do not directly determine the conversation's progression; the business user acts as an intermediary who may modify or ignore suggestions. The MDP is terminated upon successful outcome, explicit abandonment, or cessation of interaction by either party.
The illustrative scenario demonstrates practical challenges, such as balancing the acceptability of suggestions with their effectiveness at driving the dialogue toward downstream business outcomes (Figure 1).
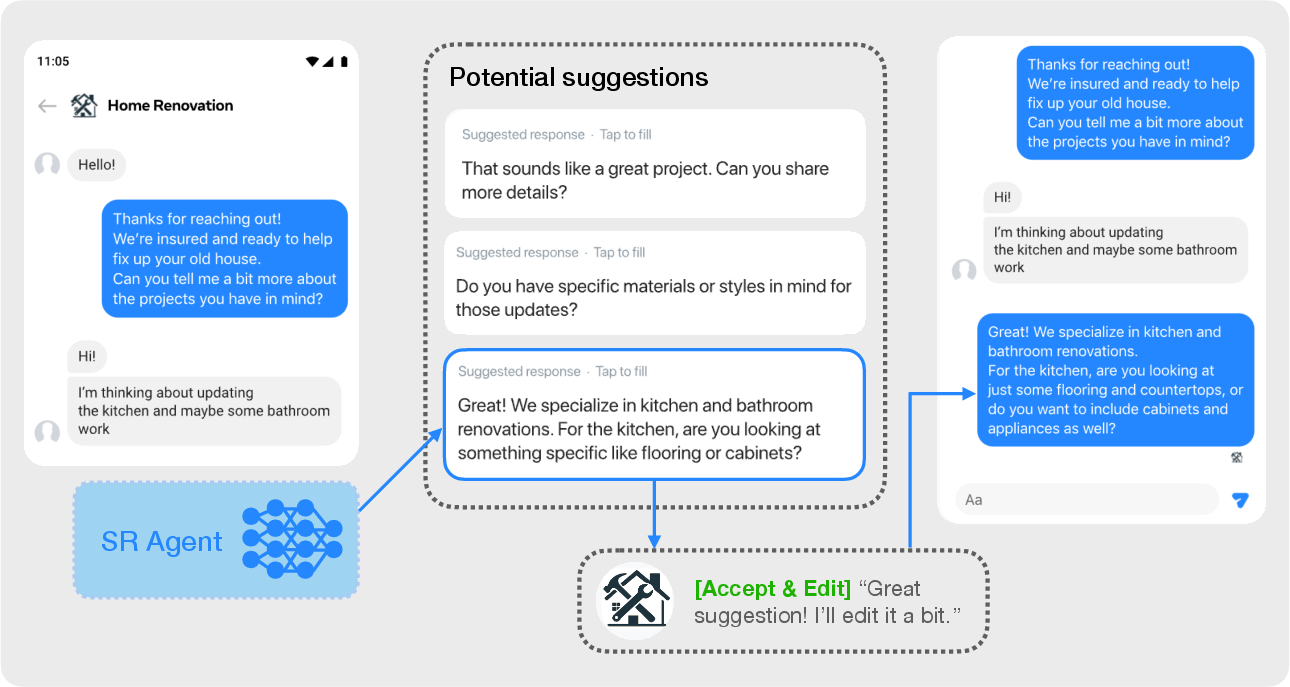
Figure 1: An example of the SR environment, showing how the LLM-generated response navigates the trade-off between outcome likelihood and business user acceptability.
From Multi-Turn to Single-Turn RL: The Iterative PPO Reduction
Existing RLHF and token-level RL methods predominantly focus on single-turn (bandit) contexts, insufficient for the credit assignment problem inherent to multi-turn trajectories with delayed rewards. This paper introduces a theoretically grounded reduction that compresses the multi-turn problem into a sequence of single-turn RL problems.
The key mechanism is as follows: For a current policy π, a state-action value function Qπ is estimated via Monte Carlo rollouts from collected interaction data. This Q-function serves as a surrogate reward model in subsequent single-turn RLHF optimization (such as PPO), with token-level RL operating under the reward proxy induced by Qπ. Policy improvement is thereby achieved via response-level value estimation followed by token-level policy optimization. Iterating this process—collecting new data under the improved policy and updating Qπ—yields an efficient batch online policy iteration scheme (Figure 2).

Figure 2: The pipeline for reducing multi-turn outcome-driven RL to iterative single-turn optimization using standard RLHF methods.
This reduction offers several technical advantages:
- The policy improvement obtained at each iteration is globally monotone under mild assumptions due to the policy improvement theorem.
- The framework can directly utilize battle-tested, highly optimized single-turn RLHF toolchains for the response generation component.
- The batch online learning configuration enables practical deployment via standard A/B testing infrastructure, with safety and stability benefits compared to fully online RL.
Algorithmic Details: Iterative PPO
The Iterative PPO algorithm alternates between two explicit phases:
- Policy Evaluation: Trajectories are collected under the current policy π, and a supervised regressor is trained to estimate Qπ at the response level using Monte Carlo returns as targets.
- Policy Improvement: A new policy is optimized via single-turn, token-level PPO, using the fixed Qπ as a reward model for all generated suggestions.
This architecture provides strong theoretical guarantees: local improvement in response action distributions (relative to Qπ) translates to global improvement in conversation-level value. The framework extends naturally to KL-regularized objectives and can, in principle, be adapted to other RL algorithms compatible with token-level policy improvement.
Practical deployment aspects involve constructing initial policies via prompt-based LLM instruction, collecting broad policy rollouts through persona-style response perturbations to mitigate distribution shift, and applying off-policy evaluation if necessary for robust Q-value estimation.
Relation to Prior Work
Unlike approaches based on multi-turn preference optimization (e.g., MTPO, DPO extensions), which typically require laborious multi-turn comparison data, this reduction leverages only scalar outcome feedback and standard reward modeling. Compared to hierarchical RL methods such as ArCHer, which combine parallel Q-learning and RLHF, Iterative PPO provides a more direct dynamic programming-inspired reduction, supporting monotonic policy improvement and reduced algorithmic complexity. Fully offline approaches are less suited for continual deployment and adaptation to changing user populations, as is required in commerce and other real-world settings.
Implications and Future Directions
The Iterative PPO reduction is broadly applicable to any outcome-driven, multi-turn conversational system, provided rewards can be articulated at the level of conversational trajectories. It is immediately relevant to high-impact applications such as sales, customer support, tutoring, and agentic decision-making where long-range planning and effective credit assignment are crucial. By aligning policy learning with trajectory-level business or user outcomes, the framework can meaningfully improve the practical impact and safety of deployed conversational AI.
Important avenues for future research include:
- Development of robust exploration strategies (e.g., strategic persona modulation) to improve coverage of the action space and value function generalization.
- Extension to domains with more complex reward surfaces (beyond binary outcomes) and partially observed or delayed reward signals.
- Investigation of sample efficiency, robustness to offline evaluation biases, and adaptation mechanisms for rapidly changing conversational domains.
Conclusion
The paper presents a rigorously justified reduction from multi-turn, outcome-driven RL to iterative single-turn optimization for LLM-powered conversational agents. Iterative PPO permits the use of mature single-turn RLHF pipelines while provably improving trajectory-level returns in practical online deployments. This framework represents a technically elegant and scalable solution to the fundamental problem of aligning conversational LLMs with long-range user or business outcomes.