- The paper presents DMPO that directly optimizes reinforcement learning objectives by replacing policy constraints with state-action occupancy measures in multi-turn tasks.
- It incorporates length normalization into the Bradley-Terry model, balancing trajectory lengths and mitigating compounding errors in noisy and clean settings.
- Experimental results show DMPO outperforms traditional methods like DPO and PPO, achieving higher rewards and more robust agent performance.
Direct Multi-Turn Preference Optimization for Language Agents
The paper "Direct Multi-Turn Preference Optimization for Language Agents" presents a novel loss function, DMPO, which directly optimizes reinforcement learning objectives in multi-turn scenarios. This study specifically addresses the challenges in applying Direct Preference Optimization (DPO) to multi-turn tasks, focusing on overcoming the inability to cancel the partition function and addressing length disparities between preferred and dis-preferred trajectories.
Introduction and Motivations
Developing language agents capable of solving complex tasks has emerged as a key objective within the AI community. While Behavioral Cloning (BC) techniques offer quick adaptation of LLMs to agent tasks, they are prone to compounding errors due to the accumulation of minor deviations in non-deterministic environments. In contrast, Direct Preference Optimization (DPO) excels in single-turn preference alignment but exhibits suboptimal performance in multi-turn settings due to its reliance on state-dependent partition functions.
The study introduces DMPO as a direct optimization method for reinforcement learning objectives in multi-turn scenarios. The key innovation involves replacing the policy constraint with a state-action occupancy measure constraint and incorporating length normalization into the Bradley-Terry model. This approach effectively addresses the partition function dependency on the current state, thereby facilitating more robust adaptation to multi-turn agent tasks.
Methodology
State-Action Occupancy Measure (SAOM)
The discounted state-action occupancy measure dπ(s,a) characterizes the likelihood of state-action pairs encountered under a given policy π. By utilizing the SAOM constraint instead of policy constraints, DMPO mitigates compounding errors more effectively. The SAOM constraint focuses on distributions of state-action pairs that approximate expert trajectories, thereby facilitating error correction when deviating from expert paths.
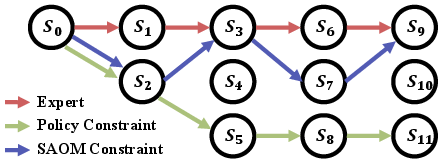
Figure 1: Illustration of expert trajectories and trajectories learned under the constraints of policy and state-action occupancy measure.
Derivation of DMPO Loss
DMPO directly optimizes the RL objective by canceling the partition function through SAOM constraints. The new RL objective is formulated as: $\max_{\pi_\theta} \mathbb{E}_{(s,a)\sim d^{\pi_\theta}(s,a)}[r(s,a)] - \beta \mathbb{D}_{KL}[d^{\pi_\theta}(s,a)||d^{\pi_{ref}(s,a)]$
Utilizing the length normalization technique, DMPO extends DPO to multi-turn scenarios by adjusting weights on state-action pairs based on a discount function ϕ(t,T). This reweighting is critical for balancing trajectory lengths in preference learning.
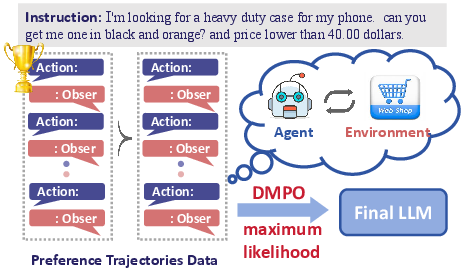
Figure 2: Illustration of DMPO loss, which directly optimizes the RL objective by maximizing the likelihood of the preferred trajectory over the dispreferred trajectory.
Experiments and Results
Robustness in Noisy Settings
In experiments conducted under noisy conditions, DMPO demonstrated superior robustness compared to DPO by effectively mitigating the effects of noise through early-stage preference prioritization.
Experiments with high-quality preference data revealed that DMPO consistently achieved higher rewards than traditional methods like PPO and SFT, particularly due to its ability to reduce compounding errors and optimize multi-turn trajectories effectively.
Hyperparameter and Length Impact
Tuning the γ hyperparameter showed that DMPO's ability to adapt importance weights on state-action pairs significantly enhances its performance, especially in clean settings where longer trajectories are available.
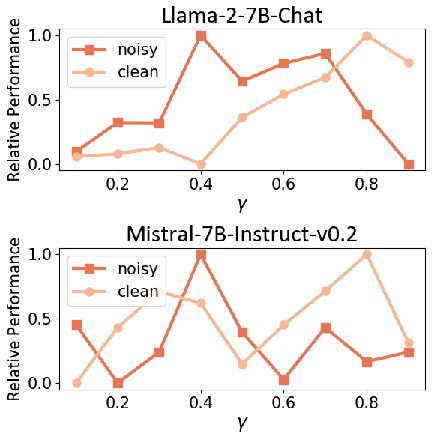
Figure 3: The effect of hyperparameter gamma on the relative performance of the model trained with DMPO loss on the WebShop dataset in both noisy and clean settings.
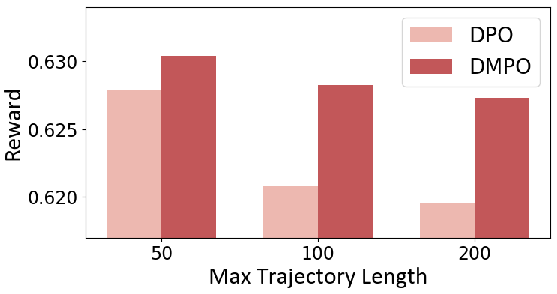
Figure 4: The effect of "loss" trajectories length on the performance of the model trained with DPO and DMPO loss in the noisy setting on ScienceWorld. The base model is Mistral-7B-Instruct-v0.2.
Conclusion
The DMPO loss function effectively addresses compounding errors and partition function dependencies in multi-turn agent tasks, offering a significant improvement over previous single-turn optimization methods. Its application in structured trajectory preference optimization suggests potential for broader AI advancements, particularly in dynamic sequence modeling and interactive agent systems. Future research could explore larger models and datasets to further validate its effectiveness.
This paper highlights the theoretical basis and empirical support for the DMPO's robust multi-turn optimization capability, marking a substantial advancement in preference-based reinforcement learning for language agents.