- The paper's main contribution is presenting a systematic framework that decomposes multi-turn RL into environment, reward, and policy components.
- It demonstrates that dense reward signals, balanced SFT and RL data, and strong imitation priors significantly boost training efficiency and generalization.
- Experiments in TextWorld, ALFWorld, and SWE-Gym reveal that training in simpler settings can transfer skills to boost performance in complex, multi-turn tasks.
Multi-turn Agentic Reinforcement Learning
Overview
The paper "A Practitioner's Guide to Multi-turn Agentic Reinforcement Learning" presents an empirical framework for training LLMs as agents in multi-turn reinforcement learning (RL) environments. This guide systematically explores the design space for multi-turn RL by decomposing it into three key pillars: environment, reward, and policy. The study aims to identify effective design choices for creating efficient LLM agents capable of generalization across complex textual and embodied tasks.
Environment
Complexity and Generalization
The environment's complexity fundamentally determines agent performance by introducing challenges like spatial navigation, object manipulation, and extended planning required for multi-turn tasks. Experiments with TextWorld illustrate that agent performance degrades significantly with increased spatial and object complexity (Table 1). Interestingly, while agents struggle more with object complexity, they develop transferable skills that generalize across complex environments.

Figure 1: TextWorld w2-o3-q4 task example. The text in gray are the prompts. The bold text is the objective. The text in blue are the observations and the text in orange are the actions.
Agents trained on simpler environments demonstrated promising generalization to those with increased complexity, highlighting the effectiveness of leveraging transferable skills like spatial exploration and object manipulation.
Policy
Model Priors and Algorithms
The study emphasizes the significance of model priors, finding that good imitation priors can substantially reduce RL sample requirements. An optimal balance between supervised fine-tuning (SFT) and RL data allocation improves both task-specific accuracy and generalization (Table 2). The analysis shows that biased algorithms (PPO and GRPO) outperform unbiased alternatives (RLOO) in multi-turn settings, with the performance gap increasing in complex environments.
Reward
Dense reward signals significantly enhance multi-turn RL performance, as evidenced by improved training efficiency and convergence rates. The findings indicate an optimal reward density that depends on the optimization algorithm used. For example, PPO benefits most from dense feedback, whereas RLOO remains robust across different reward densities. This suggests that effective reward tuning is crucial to maximize learning efficiency in multi-turn environments.
Empirical results demonstrate that multi-turn RL formulations enable agents to generalize effectively across different domains, including TextWorld, ALFWorld, and SWE-Gym (Figure 2 and 5). By leveraging these specialized environments, the study establishes guidelines for training autonomous agents capable of handling real-world interactions.
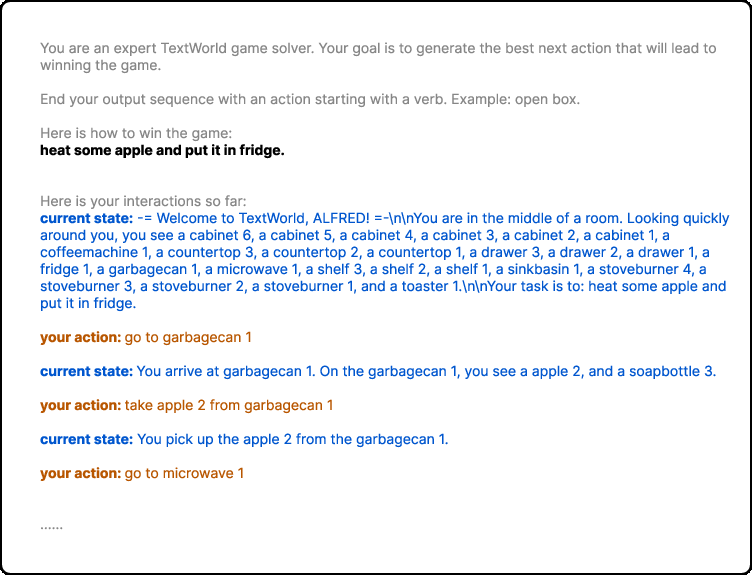
Figure 2: ALFWorld heat {additional_guidance} place task example. The text in gray are the prompts. The bold text is the objective. The text in blue are the observations and the text in orange are the actions.

Figure 3: SWE-Gym getmoto task example. The text in gray are the prompts. The bold text is the objective. The text in blue are the observations and the text in orange are the actions.
Conclusion
The research provides a well-defined, empirically-backed recipe for multi-turn agentic RL that integrates environment, policy, and reward design choices. The study underlines that multi-turn RL represents a distinct paradigm from single-turn optimization, requiring fundamental rethinking. The practical guidelines developed in this paper pave the way for designing robust agentic AI systems capable of complex multi-turn tasks in various interactive environments. By releasing the accompanying framework, future research can be accelerated, promoting the development of autonomous systems which are better suited to handle real-world dynamics.