Comparison of Text-Based and Image-Based Retrieval in Multimodal Retrieval Augmented Generation Large Language Model Systems
Abstract: Recent advancements in Retrieval-Augmented Generation (RAG) have enabled LLMs to access multimodal knowledge bases containing both text and visual information such as charts, diagrams, and tables in financial documents. However, existing multimodal RAG systems rely on LLM-based summarization to convert images into text during preprocessing, storing only text representations in vector databases, which causes loss of contextual information and visual details critical for downstream retrieval and question answering. To address this limitation, we present a comprehensive comparative analysis of two retrieval approaches for multimodal RAG systems, including text-based chunk retrieval (where images are summarized into text before embedding) and direct multimodal embedding retrieval (where images are stored natively in the vector space). We evaluate all three approaches across 6 LLM models and a two multi-modal embedding models on a newly created financial earnings call benchmark comprising 40 question-answer pairs, each paired with 2 documents (1 image and 1 text chunk). Experimental results demonstrate that direct multimodal embedding retrieval significantly outperforms LLM-summary-based approaches, achieving absolute improvements of 13% in mean average precision (mAP@5) and 11% in normalized discounted cumulative gain. These gains correspond to relative improvements of 32% in mAP@5 and 20% in nDCG@5, providing stronger evidence of their practical impact. We additionally find that direct multimodal retrieval produces more accurate and factually consistent answers as measured by LLM-as-a-judge pairwise comparisons. We demonstrate that LLM summarization introduces information loss during preprocessing, whereas direct multimodal embeddings preserve visual context for retrieval and inference.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how AI systems answer questions using both text and pictures, like the words and charts in a company’s earnings reports. The authors compare two ways to “find the right information” before the AI writes an answer:
- Convert pictures (charts, tables, slides) into text summaries first, then search using only text.
- Keep pictures as pictures, and use special tools that let the AI search across both text and images directly.
They want to know which way helps the AI find better information and give more accurate answers.
Key Objectives
The researchers set out to answer three simple questions:
- When you ask a question, is it better to store and search the actual images (like charts) instead of turning those images into text summaries?
- Does keeping the images make the AI’s final answers more correct and less “made up” (fewer hallucinations)?
- Do bigger, more powerful AI models benefit more from having real images than smaller models do?
How They Did It (Methods)
Think of the AI’s “retrieval” as a smart search engine. You ask a question, it searches a big library, pulls back the most helpful bits, and then uses those to write an answer. Here’s what they tested:
- Building a test set: They made a small, focused “quiz” of 40 realistic questions about a Fortune 500 company’s earnings. Each question needed info from both text (transcripts) and images (slides with charts).
- Two retrieval approaches:
- Text-only approach: Each slide image was turned into a paragraph summary first (like describing a chart in words). Then both the text chunks and the image summaries were stored and searched as text only.
- Direct multimodal approach: They used a model that can handle both words and pictures in the same “meaning space.” In everyday terms, it gives both text and images a kind of “meaning fingerprint” so the AI can compare them directly. This way, images stay images—no conversion to text—and the AI can retrieve them alongside text.
- Evaluating results:
- Retrieval metrics: They measured how well the search ranked the right documents using simple ideas:
- Precision@5: Of the top 5 items found, how many were actually relevant?
- Recall@5: Did the top 5 include most of the relevant items?
- mAP@5 and nDCG@5: These check not just what was found, but how well the best items were placed near the top.
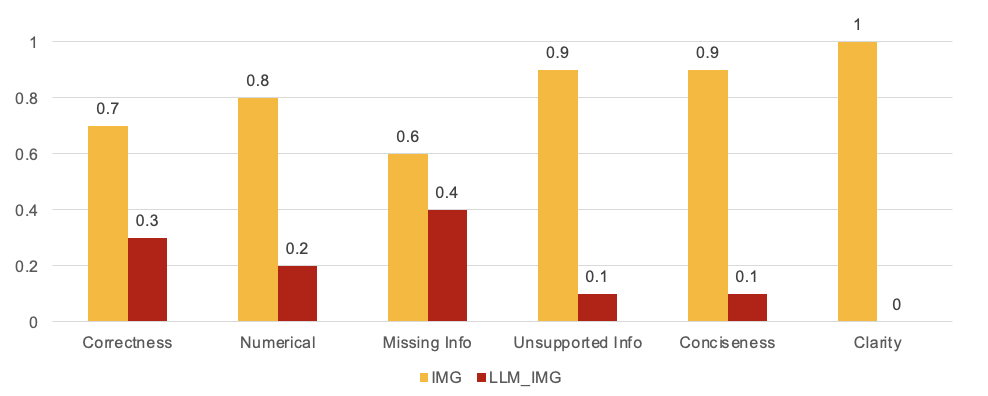
- Answer quality: After retrieval, different AI models wrote answers. Another AI “judge” compared pairs of answers for correctness, number accuracy, completeness, no made-up info, conciseness, and clarity.
An analogy: turning a chart into a paragraph is like describing a busy photo to a friend—you can capture the gist, but you’ll likely miss exact numbers, layout, or small details. Searching with real images is like letting your friend look at the photo directly.
Main Findings
- Better retrieval with real images:
- Mean Average Precision (mAP@5) improved by 13% (a 32% relative gain).
- nDCG@5 improved by 11% (about a 20% relative gain).
- Precision@5 rose by about 12.5%; Recall@5 rose slightly (~3%).
- Translation: The system that keeps images as images not only finds more relevant stuff, it ranks the best matches higher in the results list.
- Better final answers:
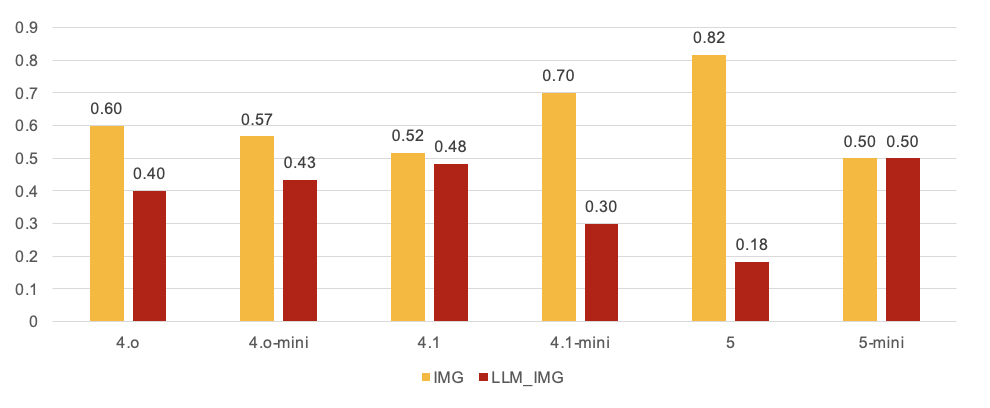
- Across models, the “keep images” approach won about 61% of pairwise comparisons overall.
- The biggest gains showed up in:
- Correctness (answers were more accurate),
- Numerical fidelity (numbers matched the charts),
- Fewer unsupported additions (far fewer hallucinations).
- Larger, more capable models benefited the most from having real images. Smaller “mini” versions saw smaller gains.
Why this happens: Converting images to text summaries loses important visual context (like exact numbers, labels, and the way information is laid out). Direct image handling preserves these details, which helps both the search step and the final answer.
Why It Matters
- For real-world tasks with charts and tables—like finance, medicine, or science—keeping images in their original form helps the AI:
- Find the right information faster,
- Avoid mistakes with numbers,
- Reduce made-up details (hallucinations),
- Produce clearer, more trustworthy answers.
- This suggests companies should consider “multimodal” retrieval (text + images) rather than converting everything into text, especially when visuals carry critical meaning.
A Quick Note on Practical Impact
Using images directly can be a bit more work upfront (you have to extract slides, charts, and figures properly before indexing them). But the payoff is strong: better search rankings and more accurate answers. As tools that handle both text and images keep improving, this advantage will likely grow.
Conclusion
The paper shows that AI systems do better when they search and use real images, not just text summaries of those images. This improves how the system finds information (ranking and relevance) and how it answers questions (more correct, accurate, and grounded). For domains where visuals matter—like financial reports—the direct multimodal approach can make AI answers more reliable and useful.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper that future researchers could act on:
- Benchmark scale and diversity: The study uses only 40 question–answer pairs from a single Fortune 500 company’s earnings materials. It is unclear how results generalize across larger corpora, multiple companies, industries (e.g., healthcare, retail, energy), document types (annual reports, 10-K/10-Q, research reports), languages, and temporal drift across quarters/years.
- Public release and reproducibility: The benchmark (documents, annotations, relevance labels), code, and indexing artifacts are not released. Without access to the dataset, prompts, and retrieval pipelines, independent replication and extension is blocked.
- Retrieval corpus size and difficulty: The paper does not specify the full index size or whether distractor documents from other events/quarters were included. It remains unknown how direct multimodal embeddings perform at realistic scale with thousands to millions of chunks/slides and hard negatives.
- Embedding model coverage and fairness: Despite references to “two multimodal embedding models,” only Jina v4 is evaluated for multimodal retrieval and only OpenAI text-embedding-ada-002 for text. Results may be confounded by model choice. A balanced ablation across multiple text (e.g., E5-large, GTE), multimodal (CLIP/OpenCLIP, EVA-CLIP, E5-V), and capacity-matched embeddings is needed.
- Strength of the text-based baseline: The LLM-generated image summaries use a single captioner (GPT-5). The paper does not compare against specialized OCR- and doc-VLM baselines (Donut, Pix2Struct, ChartOCR, Table/Chart QA models) or structured extraction (JSON with numeric precision and layout). It is unclear if better captioners narrow the gap to multimodal embeddings.
- Ground-truth relevance labeling granularity: Relevance is adjudicated by page-number matches, which may be too coarse for slides with multiple figures or transcripts with multi-hop content. Graded relevance, multi-label relevance, partial credit, and layout-aware annotations could improve fidelity of mAP/nDCG measurements.
- Absence of statistical testing: Reported improvements lack confidence intervals, variance estimates, and significance tests (e.g., paired bootstrap, randomization tests). The robustness of observed gains across runs and seeds remains unknown.
- Judge-model bias and validation: GPT-5 serves as both generator (for some models) and judge, risking evaluation bias. No human assessments, multi-judge ensembles, or agreement analyses (e.g., Krippendorff’s alpha) are provided to validate LLM-as-a-judge reliability.
- Limited generation metrics: End-to-end evaluation relies solely on LLM-as-a-judge. There are no exact-match, F1, citation grounding, faithfulness checks, or numeric tolerance band evaluations against ground truth. This weakens conclusions about factuality and numerical fidelity.
- Missing ablations on retrieval configuration: Only k=5 is tested. The effects of k, reranking (BM25, LLM re-rankers), hybrid retrieval (lexical + dense), and query rewriting/self-RAG are not explored, leaving unclear whether gains persist under common retrieval enhancements.
- Chunking, segmentation, and resolution sensitivity: The study does not analyze how transcript chunk size, slide segmentation (whole slide vs. figure-level crops), or image resolution/detail settings affect performance. Failure modes (e.g., numeric misreads, small font) are not quantified.
- Robustness to real-world document noise: There is no stress-testing on scanned PDFs, low-resolution slides, watermarks, rotated tables, or varied file formats. The resilience of multimodal embeddings to noisy, non-standard documents is unknown.
- Cross-modal query generality: All queries are text-only. The effectiveness of image queries retrieving text (image→text) or mixed text+image queries remains untested, limiting conclusions about general cross-modal retrieval behavior.
- Cost, latency, and operational trade-offs: Beyond noting preprocessing complexity, there is no measurement of end-to-end runtime, throughput, memory/compute cost, index size growth, or serving latency. Practical deployment trade-offs for production systems remain an open question.
- Domain-specific performance stratification: The paper does not break down results by content type (charts vs. tables vs. diagrams), numerically dense vs. qualitative visuals, or question types (numeric lookup vs. reasoning). Without stratified analysis, it’s unclear where multimodal retrieval helps most.
- Inconsistencies in model reporting: The abstract mentions two multimodal embedding models, but only Jina v4 is described in methods. The results table references “o1/o5-mini,” while methods list GPT-4o, GPT-4.1, and GPT-5 variants. Clarifying the exact model set and ensuring consistent nomenclature is necessary for interpretability.
- Summarization information loss characterization: While the paper claims information loss from text conversion, it lacks quantitative analysis of what is lost (e.g., numeric precision error rates, spatial/layout features). A systematic error taxonomy and measurement framework would make this claim actionable.
- Reranking and fusion with multimodal signals: The study does not examine multimodal rerankers, cross-attention fusion, or late fusion strategies that could further boost retrieval quality. How best to combine text and image signals at retrieval and generation time remains open.
- Index maintenance and drift: There is no exploration of incremental indexing, change detection, and drift handling across quarterly updates—critical for financial workflows with evolving content.
- Privacy, compliance, and security: The paper does not consider redaction, PII handling, and compliance for sensitive financial documents. Methods for secure multimodal indexing and retrieval are unaddressed.
- Explainability and provenance: The system does not provide retrieval explanations (e.g., why a slide was retrieved), nor citation/provenance tracking for generated claims. Techniques for transparent, auditable multimodal RAG are needed.
- Release of preprocessing pipeline: Although preprocessing complexity is flagged, no concrete pipeline (tools, heuristics, configs) is shared. Automated segmentation/classification of tables, figures, and charts across formats (PDF/PPT/DOCX) remains an open engineering gap to close for reproducibility.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed today by swapping text-only image summaries for direct multimodal embeddings in RAG pipelines. Each item notes sectors, likely tools/workflows, and feasibility dependencies.
- Multimodal earnings-call copilot for analysts — Finance
- What: Answer questions over transcripts and slide decks while retrieving native slide images (charts/tables) instead of text summaries; return cited thumbnails with page references.
- Tools/workflows: Azure AI Search (or equivalent) +
jina-embeddings-v4for unified text–image indexing; vision-capable LLMs (e.g., GPT-4o class); existing transcript/slide ingestion. - Dependencies/assumptions: Slide extraction to images; secure handling of non-public filings; access control; cost/performance for image embedding and storage.
- Compliance and audit verifier for investor materials — Finance/Accounting
- What: Cross-check numeric claims in MD&A, press releases, and investor decks against retrieved source charts/tables to flag discrepancies or hallucinations.
- Tools/workflows: Multimodal retrieval + lightweight numeric consistency checks; report with links to source slides and transcript snippets.
- Dependencies/assumptions: Time-aligned corpora (same quarter/event); policy for acceptable numeric variance; auditable logging.
- Investor relations self-service assistant — Finance/IR
- What: Shareholder-facing Q&A that retrieves authoritative slide visuals and transcript evidence with fewer unsupported additions.
- Tools/workflows: Multimodal RAG API behind web chat; human-in-the-loop review for sensitive responses; citation UI with thumbnails.
- Dependencies/assumptions: Legal/brand review; rate-limiting; disclosure controls.
- Enterprise knowledge search across slides, reports, and wikis — Software/Enterprise IT
- What: Natural-language search that returns the exact slide/diagram plus related text; useful for enablement, onboarding, and program management.
- Tools/workflows: Connectors to SharePoint/Confluence/OneDrive;
jina-embeddings-v4indexing of slide images and text; role-based access controls. - Dependencies/assumptions: Document hygiene and deduplication; storage quotas; permissions mapping.
- Sales and customer success “slide finder” — Software/Go-to-Market
- What: In-call assistant that retrieves the best slide/visual for a question (e.g., roadmap chart, architecture diagram) with instant preview.
- Tools/workflows: Multimodal vector index of slide repositories; Teams/Slack plugin; caching of frequently used assets.
- Dependencies/assumptions: Up-to-date asset tagging/versioning; latency budgets for retrieval.
- E-discovery and case-prep retrieval of exhibits and figures — Legal
- What: Locate diagrams, scanned exhibits, and figure-heavy attachments alongside text, reducing reliance on brittle OCR captions.
- Tools/workflows: Image-native indexing for PDFs and scanned docs; provenance tracking; exportable hit lists with image previews.
- Dependencies/assumptions: Chain-of-custody and evidentiary standards; PII handling; on-prem deployment options.
- Technical support and maintenance assistants — Manufacturing/Energy
- What: Retrieve schematics, exploded views, wiring diagrams, and procedure tables directly from manuals and service bulletins.
- Tools/workflows: PDF parsing to extract figures; multimodal index; task-specific prompts that accept both text and images.
- Dependencies/assumptions: Digitized manuals; distinction between tables vs images during ingestion; offline/edge inference in plants.
- Course and lecture assistant for study and content authoring — Education
- What: Answer questions that require figures from lecture slides/textbook diagrams; assemble citations with visuals for study guides.
- Tools/workflows: LMS integration; slide image indexing; vision-capable LLM for multimodal answers with safety filters for students.
- Dependencies/assumptions: FERPA/commercial content licensing; instructor opt-in; campus SSO.
- Healthcare admin and policy document retrieval (non-clinical) — Healthcare
- What: Retrieve charts and tables in payer policies, quality reports, and operational dashboards where visual context is critical.
- Tools/workflows: Multimodal RAG over policy PDFs and presentations; PII scrubbing; controlled vocabularies.
- Dependencies/assumptions: Exclude PHI and clinical imaging for now; compliance approvals.
- BI and dashboard search — Data/Analytics
- What: Search screenshots/exports of dashboards by business questions; return the dashboard visual and underlying commentary.
- Tools/workflows: Scheduled dashboard exports to images; multimodal index; answer UI embedding the retrieved visual.
- Dependencies/assumptions: Versioning of dashboards; governance for metric definitions.
- RAG evaluation harness and A/B testing — Academia/Industry MLOps
- What: Adopt the paper’s retrieval metrics (Precision@5, Recall@5, mAP@5, nDCG@5) and LLM-as-judge rubric to compare image-native vs summary-based pipelines on internal corpora.
- Tools/workflows: Small curated Q/A sets with page-level labels; pairwise answer comparisons; continuous evaluation in CI.
- Dependencies/assumptions: Ground-truth creation effort; judge model bias controls; reproducible seeds/prompts.
- Vendor selection and procurement criteria — Policy/IT Governance
- What: Update RAG solution RFPs to require native multimodal embedding retrieval, numeric fidelity tests, and hallucination controls.
- Tools/workflows: Standardized acceptance tests modeled on the paper’s benchmark design; pilot bake-offs.
- Dependencies/assumptions: Cross-vendor parity in vector DB support for multimodal embeddings; budget for trials.
Long-Term Applications
These use cases are promising but depend on further research, scaling, or ecosystem development (e.g., robust parsing, better multimodal reasoning, governance).
- Automated multimodal document parsing at scale — Cross-sector
- What: Turn-key pipelines that reliably segment, classify, and extract figures/tables/charts across PDFs, PPTs, and scans with minimal ops.
- Tools/workflows: Docling, Azure Document Intelligence, Unstructured, plus learned figure/table detectors; schema normalization.
- Dependencies/assumptions: High-accuracy figure vs table detection; error handling; standard metadata schemas.
- Numerically grounded chart understanding — Finance/Science
- What: Extract precise numbers from charts (axes, legends) and verify claims programmatically, not only via vision-language reasoning.
- Tools/workflows: Chart parsers + multimodal RAG; hybrid neuro-symbolic checks; source-of-truth data linkage.
- Dependencies/assumptions: Robust chart OCR/structure extraction; tolerance to varied styles; auditability.
- Multimodal risk and compliance monitors — Regulated industries
- What: Continuous scanning of outgoing materials to prevent numeric/claims drift from source visuals; policy-aligned explanations.
- Tools/workflows: Scheduled re-indexing and diffing; policy rule engines; immutable evidence trails.
- Dependencies/assumptions: Governance frameworks; low false-positive regimes; regulator acceptance.
- Cross-modal multi-hop reasoning agents — Enterprise research
- What: Chain reasoning over slides, tables, and text across events (e.g., quarter-over-quarter trends), generating narratives with grounded visuals.
- Tools/workflows: Agents that plan retrieval across modalities/time; re-ranking; memory and tool-use orchestration.
- Dependencies/assumptions: Stronger multimodal LLMs; efficient context management; cost controls.
- Interactive visual grounding in answers — Product UX
- What: Answers that cite specific regions of images (bounding boxes/highlights) and allow click-through to the exact visual evidence.
- Tools/workflows: Region-aware retrieval; UI overlays; explainability APIs.
- Dependencies/assumptions: Stable visual grounding from LLMs; standardized annotation formats.
- Multilingual multimodal RAG — Global enterprises
- What: Query in one language and retrieve/answer across images and text in many languages with consistent numeric fidelity.
- Tools/workflows:
jina-embeddings-v4-class multilingual multimodal embeddings; locale-aware prompts; translation QA. - Dependencies/assumptions: High-quality multilingual vision-LLMs; region-specific compliance.
- On-prem/edge multimodal RAG — Healthcare/Defense/Industrial
- What: Private, low-latency retrieval of sensitive visuals (e.g., plant diagrams) on secure hardware.
- Tools/workflows: Containerized embedding/LLM stacks; GPU/accelerator planning; offline evaluation harness.
- Dependencies/assumptions: Hardware availability; model compression; strict access control.
- Standardized multimodal indexes and governance — Ecosystem
- What: Industry schemas for storing embeddings, image metadata, figure types, provenance, and citations to support audit and portability.
- Tools/workflows: Open standards and APIs; governance playbooks; lineage capture at ingestion and retrieval.
- Dependencies/assumptions: Cross-vendor alignment; backward compatibility; legal acceptance.
- Scientific and patent assistants with figure-first retrieval — Academia/IP
- What: Literature and patent search that prioritizes figures/diagrams alongside text for mechanism discovery and prior-art analysis.
- Tools/workflows: Domain-tuned multimodal embeddings; figure taxonomy; examiner-friendly citation bundles.
- Dependencies/assumptions: Access to full-text and figure corpora; legal text mining allowances.
- Real-time dashboard and stream retrieval — DataOps
- What: Live capture/index of evolving dashboards and operational visuals with temporal-aware retrieval and alerting.
- Tools/workflows: Snapshot pipelines; time-indexed multimodal vectors; drift detection.
- Dependencies/assumptions: Storage and cost budgets; snapshot governance; data latency SLAs.
- Open benchmarks across domains — Research community
- What: Public multimodal RAG benchmarks for medical imaging reports, legal exhibits, scientific charts, and education diagrams modeled after the paper’s design.
- Tools/workflows: Community datasets with page-level relevance labels; unified evaluation harnesses.
- Dependencies/assumptions: Licensing of corpora; annotation funding; robust judge protocols to reduce bias.
- 3D/interactive visual retrieval — Engineering/design
- What: Extend from 2D images to CAD/3D and interactive visualizations for retrieval and grounded explanations.
- Tools/workflows: Embeddings for 3D/interactive modalities; viewers with citation overlays; conversion toolchains.
- Dependencies/assumptions: Mature multimodal models for non-2D assets; heavy compute/storage planning.
Glossary
- Azure AI Search: A managed search service providing vector indexing and retrieval capabilities for documents. "Both approaches utilize Azure AI Search as the vector database backend and retrieve the top-5 most relevant documents for each query."
- Bi-encoder: A dual-encoder architecture that independently embeds queries and documents into the same space for efficient similarity search. "dense passage retrieval methods such as DPR leverage bi-encoders to map queries and documents into shared embedding spaces"
- BM25: A probabilistic lexical ranking function used in information retrieval to score document relevance based on term frequency and document length. "Traditional lexical retrieval baselines including TF-IDF and BM25 provide reference points for dense retrieval evaluation."
- CLIP: A vision-LLM trained via contrastive learning to align image and text embeddings for cross-modal tasks. "CLIP pioneered vision-language pretraining by learning transferable visual representations from natural language supervision, aligning image and text embeddings through contrastive learning on large-scale web data"
- Contrastive learning: A representation learning technique that pulls semantically similar pairs together and pushes dissimilar ones apart. "aligning image and text embeddings through contrastive learning on large-scale web data"
- Corrective retrieval: A retrieval strategy that adjusts or refines initial results to improve relevance before generation. "Advanced RAG methods further enhance retrieval through query rewriting, hypothetical document embeddings, corrective retrieval, self-reflective generation, and hybrid retrieval strategies"
- Cross-modal retrieval: Retrieving relevant content across different modalities (e.g., text-to-image or image-to-text) using shared representations. "Multimodal embedding models enable unified representations of text and images in shared semantic spaces, facilitating cross-modal retrieval."
- Dense Passage Retrieval (DPR): A neural retrieval approach that encodes queries and passages into dense vectors to enable semantic matching beyond exact keywords. "dense passage retrieval methods such as DPR leverage bi-encoders to map queries and documents into shared embedding spaces"
- Dense retrieval: Retrieval using learned embedding vectors to capture semantic similarity, rather than purely lexical overlap. "Current RAG systems handle text documents effectively through dense retrieval methods"
- Document Intelligence: Automated extraction and structuring of information from complex documents, often combining OCR and layout analysis. "advocating for Document Intelligence to extract and structure visual content before indexing"
- Donut: An OCR-free transformer model for document understanding that operates on visual tokens instead of recognized text. "Donut introduced an OCR-free document understanding transformer that learns from visual tokens rather than recognized text, reducing transcription errors but ultimately producing text sequences that discard visual layout and spatial relationships"
- Hierarchical and multi-granularity reasoning: A method that reasons across document elements at multiple levels of detail and structure to answer questions. "MHier-RAG proposed hierarchical and multi-granularity reasoning for visual-rich document question answering"
- Hypothetical document embeddings: Embeddings of synthesized or imagined documents that help improve retrieval without labeled relevance data. "Advanced RAG methods further enhance retrieval through query rewriting, hypothetical document embeddings, corrective retrieval, self-reflective generation, and hybrid retrieval strategies"
- Jina Embeddings v4: A universal multimodal and multilingual embedding model that maps text and images into a shared semantic space. "Jina Embeddings v4 further advances this capability with universal embeddings supporting multimodal and multilingual retrieval"
- LLM-as-a-judge: An evaluation methodology where a LLM assesses and compares answers for quality and correctness. "For end-to-end system evaluation, recent work introduces LLM-as-a-judge methodologies where LLMs assess response quality through pairwise comparisons"
- Low-Rank Adaptation (LoRA): A parameter-efficient fine-tuning technique that injects low-rank matrices into model weights to adapt embeddings or LLMs to new tasks. "Jina Embeddings v3 introduced task-specific Low-Rank Adaptation (LoRA) for text embeddings, enabling flexible adaptation across diverse retrieval scenarios"
- Macro-averaged: Averaging a metric across queries or classes without weighting, emphasizing equal contribution of each case. "Table \ref{tab:retrieval_results} presents the macro-averaged retrieval performance comparing direct multimodal embedding retrieval (IMG) against text-based image retrieval (LLM_IMG)."
- Mean Average Precision (mAP@5): The mean of average precision scores across queries, computed over the top 5 results and sensitive to ranking order. "achieving absolute improvements of 13\% in mean average precision (mAP@5)"
- Multimodal embedding models: Models that create unified vector representations for different data types (e.g., text and images) to enable cross-modal search. "Multimodal embedding models enable unified representations of text and images in shared semantic spaces"
- Multimodal RAG: Retrieval-Augmented Generation systems that incorporate and retrieve both textual and visual content. "Comprehensive surveys on multimodal RAG highlight the growing interest in systems that handle diverse modalities including text, images, tables, and charts"
- Native image embeddings: Vector representations computed directly from image content, without converting images into text first. "its image features derive from text captions and descriptions rather than native image embeddings, potentially losing visual fidelity."
- Normalized Discounted Cumulative Gain (nDCG@5): A ranking metric that emphasizes placing highly relevant items earlier in the top-5 results. "normalized Discounted Cumulative Gain (nDCG@5) evaluates ranking quality by assigning higher weight to relevant documents appearing earlier in the ranking"
- OCR-free: Approaches that understand documents directly from pixels without optical character recognition. "OCR-free document understanding transformer"
- Pix2Struct: A model that learns visual language understanding via screenshot parsing to improve reasoning over charts and interfaces. "Pix2Struct further advanced chart and interface understanding through screenshot parsing as pretraining, demonstrating improved visual reasoning with language supervision"
- Precision@5: The proportion of the top 5 retrieved items that are relevant. "Precision@5 measures the fraction of retrieved documents that are relevant"
- Query rewriting: Automatically reformulating queries to improve retrieval effectiveness. "Advanced RAG methods further enhance retrieval through query rewriting, hypothetical document embeddings, corrective retrieval, self-reflective generation, and hybrid retrieval strategies"
- Re-ranking: Reordering initially retrieved candidates using additional signals (e.g., LLM judgments) to improve final ranking. "Reranking techniques using LLMs as re-ranking agents improve retrieval precision by reordering candidates based on query-document relevance"
- Recall@5: The fraction of all relevant items that appear within the top 5 retrieved results. "Recall@5 measures the fraction of all relevant documents successfully retrieved"
- Retrieval-Augmented Generation (RAG): A framework where generation is grounded in external retrieved knowledge to reduce hallucinations. "Retrieval-Augmented Generation (RAG) has emerged as an effective approach to improve factual accuracy and reduce hallucinations"
- Self-reflective generation: A technique where models critique and refine their outputs to improve correctness and coherence. "Advanced RAG methods further enhance retrieval through query rewriting, hypothetical document embeddings, corrective retrieval, self-reflective generation, and hybrid retrieval strategies"
- TF-IDF: A lexical scoring method weighting terms by frequency and inverse document frequency to rank relevance. "Traditional lexical retrieval baselines including TF-IDF and BM25 provide reference points for dense retrieval evaluation."
- text-embedding-ada-002: A widely used OpenAI dense text embedding model for semantic search and retrieval tasks. "OpenAI text-embedding-ada-002, a widely adopted dense embedding model for semantic retrieval"
- Unified semantic vector space: A shared embedding space where different modalities (text, images) are directly comparable by semantic similarity. "embed text and images into a unified semantic vector space"
- Vector database: A storage system optimized for indexing and retrieving high-dimensional embeddings via similarity search. "only these text summaries are stored in the vector database."
- Vector Search: Similarity-based retrieval over embedding vectors rather than keywords. "Vector Search"
- Vision-LLM: A model that processes and relates visual inputs and text to enable tasks like captioning and visual question answering. "a vision-LLM generates textual descriptions of each image"
Collections
Sign up for free to add this paper to one or more collections.