RAG-Anything: All-in-One RAG Framework
Abstract: Retrieval-Augmented Generation (RAG) has emerged as a fundamental paradigm for expanding LLMs beyond their static training limitations. However, a critical misalignment exists between current RAG capabilities and real-world information environments. Modern knowledge repositories are inherently multimodal, containing rich combinations of textual content, visual elements, structured tables, and mathematical expressions. Yet existing RAG frameworks are limited to textual content, creating fundamental gaps when processing multimodal documents. We present RAG-Anything, a unified framework that enables comprehensive knowledge retrieval across all modalities. Our approach reconceptualizes multimodal content as interconnected knowledge entities rather than isolated data types. The framework introduces dual-graph construction to capture both cross-modal relationships and textual semantics within a unified representation. We develop cross-modal hybrid retrieval that combines structural knowledge navigation with semantic matching. This enables effective reasoning over heterogeneous content where relevant evidence spans multiple modalities. RAG-Anything demonstrates superior performance on challenging multimodal benchmarks, achieving significant improvements over state-of-the-art methods. Performance gains become particularly pronounced on long documents where traditional approaches fail. Our framework establishes a new paradigm for multimodal knowledge access, eliminating the architectural fragmentation that constrains current systems. Our framework is open-sourced at: https://github.com/HKUDS/RAG-Anything.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy Explanation of “RAG-Anything: All-in-One RAG Framework”
What is this paper about?
This paper introduces RAG-Anything, a system that helps AI answer questions by looking up information not just in text, but also in images, tables, and math formulas. It’s like giving an AI an “open-book exam” where the book includes words, pictures, and charts—then teaching it how to find the right page, panel, or cell to get the correct answer.
What questions are the researchers trying to answer?
The authors ask:
- How can we make AI search and understand information that’s not only text, but also pictures, tables, and equations?
- How can we connect all these different formats so the AI doesn’t get confused?
- How can we make the AI good at finding answers in very long documents where the clues are spread out across pages and formats?
How does their system work? (Methods in simple terms)
Think of a messy binder full of reports, charts, and tables. RAG-Anything organizes this binder and builds a smart “map” so the AI can quickly find what it needs.
Here’s the idea step by step:
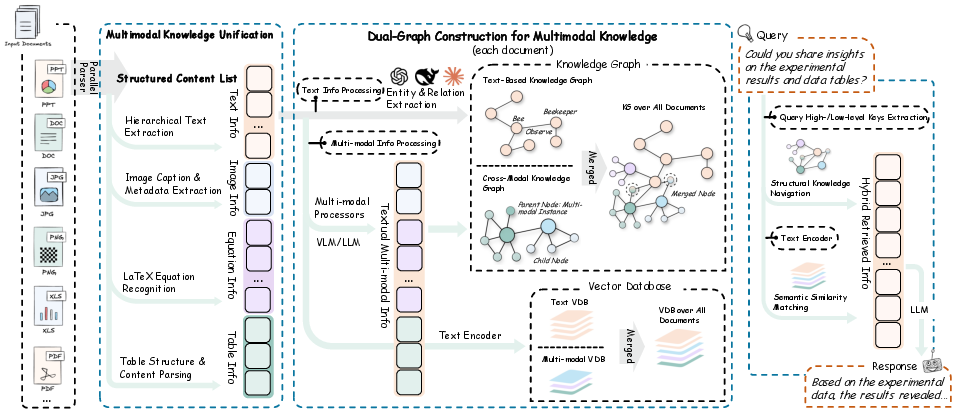
Step 1: Break documents into small, useful pieces (“atoms”)
The system splits each document into tiny parts: paragraphs, images with captions, tables with their headers and cells, and math equations with nearby explanations. It keeps the connections—for example, a figure stays linked to its caption.
Step 2: Build two connected maps (“graphs”)
A graph here is like a web of dots (things) and lines (relationships).
- Map A: The cross-modal map connects non-text items (images, tables, equations) to their meanings and nearby text. For example, a table becomes a set of nodes (row headers, column headers, cells) linked together.
- Map B: The text map connects people, places, terms, and relationships found in the text parts of the documents.
- The system then merges these two maps by matching shared entities (like the same concept or name), creating one unified “knowledge map.”
Step 3: Search using two strategies at once (“hybrid retrieval”)
When you ask a question, the system:
- Follows the map (structural navigation): It tracks connections between related nodes, like moving from a question about “Figure 1’s right panel” to the correct subfigure, axis labels, and caption.
- Matches meaning (semantic search): It also searches for pieces that are most similar in meaning to your question, even if there isn’t a direct link in the map.
These two search results are combined and ranked, balancing structure (how things are connected) and meaning (how similar they are to your question).
Step 4: Build the answer from both text and visuals
The system gathers the best text snippets and re-attaches the original visuals (like the actual chart image) so the AI can “look” at them while answering. This helps it stay accurate and grounded in the evidence.
What did they find? (Main results)
The researchers tested RAG-Anything on two tough benchmarks with long, mixed-format documents:
- DocBench: 229 long documents with 1,102 questions across areas like academia, finance, law, and news.
- MMLongBench: 135 long documents with 1,082 questions across guides, reports, and more.
Key takeaways:
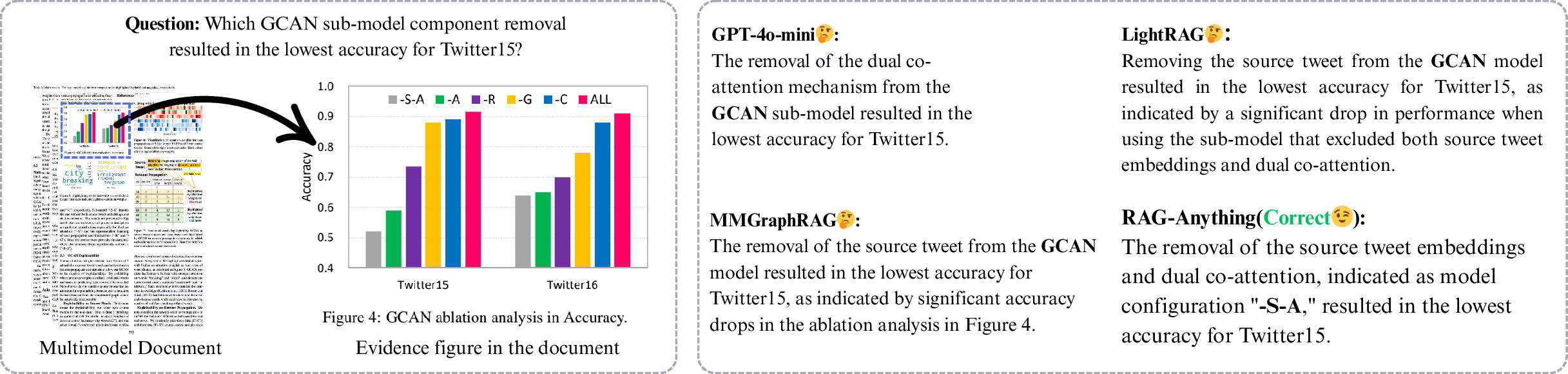
- It beat strong baselines (like GPT-4o-mini, LightRAG, and MMGraphRAG), especially when documents were long and contained many formats.
- The gains grew as documents got longer. On very long files (100+ pages), it was much more accurate than other methods.
- An ablation study (turning off parts of the system to see what matters most) showed the biggest boost comes from the graph-based design. A simple “chunk-only” approach (just splitting text without structure) missed important connections. Reranking helps a bit, but the graphs are the main reason for the improvement.
To make this concrete, the paper shows two examples:
- Multi-panel figure: The system picks the correct sub-figure by using the structure (panel → caption → axes), avoiding confusion with nearby panels.
- Financial table: It finds the exact number by navigating the table’s structure (row header → column header → cell), not by guessing from similar words.
Why is this important? (Implications)
Real-world knowledge isn’t just text—important facts live in charts, tables, and equations. RAG-Anything:
- Helps AI “see” and use all these formats together instead of flattening everything into plain text (which loses meaning).
- Makes AI better at long, complex documents where clues are scattered.
- Sets a template for future systems: represent all content as connected entities, search by both structure and meaning, and answer using both words and visuals.
In simple terms: this work makes AI much better at open-book problem solving in the real world—where “the book” includes paragraphs, pictures, spreadsheets, and formulas—and where the right answer may be hiding in a tiny table cell or a specific panel of a figure.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The following list identifies what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable gaps for future work:
- Formalize the graph construction pipeline: precisely specify the extraction routine R(·), entity/relation schemas, panel detection in figures, table parsing (including merged/row-spanning headers), and equation parsing to enable reproducibility and independent evaluation.
- Quantify graph extraction quality: report precision/recall for entity/relation extraction across modalities (text, images, tables, equations), and analyze error propagation from multimodal LLM-generated descriptions to the final graph.
- Robust entity alignment across modalities: current fusion relies on entity names; investigate synonymy, abbreviations, coreference, numeric entities, and unnamed visual elements, and measure alignment error rates and their impact on retrieval.
- Cross-modal embeddings vs textual proxies: retrieval appears to rely primarily on text embeddings of LLM-generated descriptions for non-text units; evaluate information loss and compare against true multimodal encoders (e.g., image/table/math-aware embeddings) in retrieval performance and efficiency.
- Learnable multi-signal fusion scoring: detail and evaluate the fusion function combining structural importance, semantic similarity, and modality preferences; explore learned weighting (e.g., learning-to-rank) versus heuristic scores and calibrate per-domain/per-modality.
- Query modality inference beyond lexical cues: assess robustness for implicit modality needs, multi-turn queries, non-English queries, and ambiguous phrasing; develop and evaluate stronger modality intent classifiers.
- Scalability profiling: characterize indexing/build times, memory footprint, graph size growth, and retrieval latency on large corpora (hundreds/thousands of long documents), and propose graph pruning or compression strategies.
- Incremental and streaming indexing: design and evaluate mechanisms for online updates (document edits, additions), partial re-indexing, and consistency maintenance in the dual-graph under dynamic corpora.
- OCR/layout robustness: test on noisy scans, multi-column layouts, rotated text, complex tables (nested/merged cells), and weakly-structured PDFs; quantify degradation and propose corrective preprocessing or layout-aware models.
- Coverage of modalities beyond those evaluated: the “Anything” claim is not validated for audio, video, interactive content, or code; extend the framework and benchmarks to these modalities and analyze alignment/fusion challenges.
- Equation handling and math reasoning: detail the symbolic representation of equations, how math semantics are embedded and retrieved, and evaluate on tasks that require formula-level grounding and derivations.
- Grounding and attribution: measure faithfulness (e.g., evidence citation, attribution checks) and introduce mechanisms to ensure answers are supported by retrieved nodes/assets, especially in multimodal synthesis.
- Unanswerable query handling: the method performs poorly on unanswerable cases; add abstention mechanisms, uncertainty estimation, and calibration to reduce false positives.
- Conflict resolution across modalities: define strategies for resolving contradictions (e.g., text vs figure/table) and evaluate their effect on factuality.
- Numeric and unit-aware retrieval: implement normalization (thousand separators, currencies, percentages, time), and test precision on numerical queries and table cell targeting across diverse formats.
- Detailed ablations per modality: isolate the marginal contributions of images, tables, and equations separately (not only “chunk-only” and “w/o reranker”) to establish where gains originate.
- Cross-page/entity linking algorithm: specify and evaluate cross-page alignment heuristics/algorithms (referenced in long-context gains), including their error rates and efficiency.
- Parameter sensitivity: report sensitivity analyses for hop distance in structural expansion, neighborhood size δ for context windows, top-k sizes, and fusion weights to guide practitioners.
- Reranker role and alternatives: given modest gains, explore stronger cross-modal rerankers, listwise ranking, or graph-aware reranking, and identify when reranking is essential versus redundant.
- Candidate deduplication and overlap handling: detail methods to collapse redundant candidates across retrieval pathways and quantify effects on answer accuracy and latency.
- Efficiency of synthesis with VLM: specify the VLM model, its conditioning strategy, compute costs, and latency impacts when dereferencing visuals; compare to text-only synthesis under matched constraints.
- Broader evaluation and fairness: avoid page caps that disadvantage baselines (e.g., GPT-4o limited to 50 pages); include statistical significance tests, human evaluations, and alternative judges to reduce bias from a single proprietary model.
- Open-source reproducibility: reliance on proprietary models (GPT-4o-mini, text-embedding-3-large) limits replicability; provide results with open-source backbones (e.g., Qwen-VL, LLaVA, multilingual embeddings) and open evaluation pipelines.
- Multilingual support: test cross-language documents and queries, cross-script entity alignment, and multilingual NER/RE to validate generalizability beyond English corpora.
- Security and safety: analyze risks from prompt injection via retrieved text and images (e.g., adversarial figures), data leakage, and privacy for sensitive documents; propose mitigations.
- Cost and energy footprint: report token usage, API/model costs for multimodal description generation, indexing, reranking, and synthesis, and explore cost-quality trade-offs.
- Global graph across documents: extend from per-document graphs to a corpus-level multimodal knowledge graph; study entity linking across documents, versioning, and retrieval over global structures.
- End-to-end training: investigate supervised or reinforcement learning to jointly optimize extraction, retrieval, fusion, and synthesis for task-specific performance, rather than purely modular/zero-shot components.
- Additional metrics: go beyond accuracy to measure calibration, latency, throughput, and robustness; include failure analyses and error typologies to direct improvements.
- Handling extremely long contexts: evaluate beyond 200+ pages and characterize performance/latency curves; propose hierarchical indexing or multi-stage retrieval for ultra-long documents.
- User-in-the-loop retrieval: explore interactive refinement (feedback, reformulation, facet selection) and quantify gains in precision for complex multimodal queries.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now using the paper’s open-source framework, dual-graph indexing, and cross-modal hybrid retrieval, primarily over PDFs, slides, and web pages containing text, images, tables, and equations.
- Multimodal enterprise document QA copilot
- Sectors: software, manufacturing, telecom, consulting
- Description: A chat assistant that answers questions about policy documents, reports, manuals, and technical specs where evidence spans paragraphs, figures, tables, and formulas.
- Tools/Workflows: Dual-graph indexer (multimodal + text graph), vector DB for embeddings, modality-aware query router, hybrid retriever, VLM-backed synthesis; integrates with document management systems (SharePoint, Confluence).
- Assumptions/Dependencies: High-quality parsing/OCR (e.g., MinerU), adequate GPU/CPU for indexing long documents, reliable VLM for visual grounding, data governance for sensitive content.
- Financial report navigator and metric extractor
- Sectors: finance, insurance, accounting
- Description: Extracts and validates figures from annual/quarterly reports by targeting table cells (row–column–unit) and chart panels; supports cross-year comparisons and context-aware disambiguation.
- Tools/Workflows: “Financial Table Navigator” (row/column/unit graph), “Chart Insight Extractor,” reranker; exports to BI tools or spreadsheets.
- Assumptions/Dependencies: Accurate table structure extraction, domain prompts for financial terminology, consistent layout quality in source documents, human-in-the-loop for material decisions.
- Research paper assistant with figure/subpanel disambiguation
- Sectors: academia, R&D (biotech, AI, materials, pharma)
- Description: Answers figure-specific questions (e.g., which subpanel shows cluster separation) and links equations to surrounding definitions and results.
- Tools/Workflows: Multi-panel visual-layout graph (panels, axes, legends, captions), equation-to-text linkage, dual-graph retrieval; integrates with literature libraries.
- Assumptions/Dependencies: Access to full-text PDFs, reliable caption extraction, VLM capable of interpreting scientific plots; not a substitute for peer review.
- Regulatory and legal filings analysis
- Sectors: legal tech, compliance, government affairs
- Description: Query across multimodal filings and statutes; maps clauses to tables/graphs; supports due diligence and policy compliance checks.
- Tools/Workflows: “Regulatory RAG bot” with entity alignment between laws and exhibits, structural navigation for cross-references, citation trace for evidence.
- Assumptions/Dependencies: Up-to-date corpora, strong entity-resolution (names/aliases), privacy controls; legal teams retain final judgment.
- Technical manual and field support agent
- Sectors: manufacturing, robotics, automotive, aerospace
- Description: Troubleshooting and “how-to” answers grounded in manuals, schematic images, and parts lists; precise retrieval of figure callouts and tables.
- Tools/Workflows: Manual ingestion pipeline, visual diagram graph (callouts ↔ parts ↔ procedures), modality-aware query hints (“see figure/table”).
- Assumptions/Dependencies: OCR quality for scans, accurate diagram parsing, safety constraints for operational guidance.
- Education: multimodal tutoring for textbooks and lecture notes
- Sectors: education, edtech
- Description: Tutors that explain equations in context, guide students through diagrams and tables, and answer targeted questions about problem sets with figures.
- Tools/Workflows: Equation-to-text explainer, panel-aware diagram QA, structured context assembly for LLM conditioning.
- Assumptions/Dependencies: Correct LaTeX/equation parsing, pedagogy-aware prompts; guardrails to prevent misinformation and exam misconduct.
- Publishing and documentation QA
- Sectors: publishing, technical writing, knowledge management
- Description: Evidence-grounded checks that captions, references, and numeric claims match figures/tables; detects misreferenced panels or mislabeled units.
- Tools/Workflows: Dual-graph validation pipeline (caption ↔ figure ↔ units ↔ referenced claims), discrepancy reports.
- Assumptions/Dependencies: Consistent document structure, access to source assets, willingness to adopt pre-publication QA workflows.
- Screenshot/slide-based BI Q&A (static dashboards)
- Sectors: analytics, sales ops, operations
- Description: Answers questions about charts embedded in slides or static dashboard exports; identifies trends or values when original data is unavailable.
- Tools/Workflows: Image panel graph, figure-axis-title alignment, hybrid retrieval; integrates with slide repositories.
- Assumptions/Dependencies: Sufficient image resolution and legible labels; limited without underlying datasets.
- Patent and prior-art search across multimodal filings
- Sectors: IP, legal, R&D
- Description: Cross-modal retrieval over claims, drawings, tables of parameters, and formulae to support novelty checks.
- Tools/Workflows: Dual-graph index of patents (drawings ↔ claims ↔ tables), semantic + structural ranking, controlled evidence trails.
- Assumptions/Dependencies: Jurisdiction-specific corpora, robust entity alignment, human IP counsel oversight.
- Public document transparency and civic Q&A
- Sectors: government, non-profits, journalism
- Description: Citizen-facing explorer that answers questions about public budgets, reports, and dashboards with charts and tables.
- Tools/Workflows: Open-data ingestion, structural navigation for budget tables, citation links to panels/cells.
- Assumptions/Dependencies: Availability of open data, multilingual OCR for diverse documents, fairness and accessibility standards.
Long-Term Applications
These use cases require further research, scaling, benchmarking, domain adaptation, or regulatory clearance before production.
- Clinical decision support with multimodal EHR (images + structured data + notes)
- Sectors: healthcare
- Description: Assist clinicians by retrieving and contextualizing radiology images, lab tables, and clinical notes for diagnosis and treatment planning.
- Tools/Workflows: “Multimodal EHR RAG” integrating PACS images, tabular labs, and notes; evidence-grounded synthesis in a VLM.
- Assumptions/Dependencies: FDA/CE approvals, PHI privacy/compliance, medical-grade VLMs, rigorous validation and bias assessment.
- Real-time market insight agent from streaming charts and filings
- Sectors: finance, trading, asset management
- Description: Continuous ingestion of charts, KPI tables, and news PDFs; answers questions and surfaces anomalies or trends.
- Tools/Workflows: Streaming index updates, time-aware graph overlays, alerting workflows.
- Assumptions/Dependencies: Low-latency pipelines, robust OCR for varied formats, domain-specific risk controls; potential market-impact considerations.
- Cross-paper visual meta-analysis and trend synthesis
- Sectors: academia, pharma, materials science
- Description: Aggregate and reason across plots and tables from many studies to detect consensus patterns or contradictions.
- Tools/Workflows: Cross-document entity alignment (metrics, units, cohorts), panel-normalization, meta-analysis scaffolding.
- Assumptions/Dependencies: Standardization of figure types/units, high-quality caption/legend parsing, reproducibility frameworks.
- Contract analytics and audit automation
- Sectors: legal, accounting, compliance
- Description: Verify numeric consistency across clauses, tables, and exhibits; detect misaligned definitions or out-of-range values.
- Tools/Workflows: “Equation-to-table consistency checker,” constraint graphs, exception reporting.
- Assumptions/Dependencies: Formalization of legal constraints, domain ontologies, human review loops.
- Multilingual, multimodal cross-border document intelligence
- Sectors: global enterprises, regulators, NGOs
- Description: Retrieval across documents in multiple languages with mixed scripts, figures, and tables.
- Tools/Workflows: Multilingual OCR and embeddings, language-aware entity alignment, locale-specific units/notations.
- Assumptions/Dependencies: High-quality multilingual parsers, cross-lingual VLM performance, cultural/linguistic adaptation.
- CAD/schematics-aware maintenance copilots
- Sectors: energy, utilities, manufacturing, aerospace
- Description: Integrate vector drawings/schematics with procedures and parts tables; guide technicians through complex repairs.
- Tools/Workflows: CAD-to-graph conversion (layers, callouts, BOM linkage), device-specific workflows.
- Assumptions/Dependencies: Robust parsing of CAD formats (beyond static images), device-specific knowledge, safety certification.
- Government transparency portals with evidence-grounded exploration
- Sectors: public sector
- Description: Scalable public platforms providing verifiable answers grounded in charts/tables across agency reports.
- Tools/Workflows: Dual-graph indices for large corpora, provenance/citation tooling, accessibility features.
- Assumptions/Dependencies: Funding, data standardization, governance, fairness audits.
- SaaS platform for multimodal Graph RAG
- Sectors: software, AI platforms
- Description: Productizing dual-graph indexing, hybrid retrieval, and VLM synthesis as a managed service with connectors to enterprise content.
- Tools/Workflows: Ingestion connectors (DMS, cloud storage), multi-tenant graph + vector infrastructure, monitoring/observability.
- Assumptions/Dependencies: Scalability, cost controls (indexing/synthesis on long docs), security certifications (SOC2/ISO 27001).
Cross-cutting assumptions and dependencies
- Parsing/OCR quality is critical: scanned PDFs and complex layouts require robust tools (e.g., MinerU or equivalent).
- VLM availability and capability: synthesis depends on models that can reliably interpret charts, tables, and images; domain-tuned prompts/models improve outcomes.
- Computational and storage costs: dual-graph construction for large corpora is resource intensive; retrieval over long documents requires efficient indexing and reranking.
- Data governance and compliance: sensitive and regulated domains (healthcare, finance, legal) require privacy, auditability, and human-in-the-loop decision-making.
- Entity alignment and ontology design: accurate cross-modal linking hinges on well-defined entities, names, and domain ontologies; multilingual use adds complexity.
- Evaluation and reliability: application-specific benchmarks and error analysis are needed, especially for high-stakes settings; ablations show most gains come from graph-based retrieval, with reranking adding marginal improvements.
Glossary
- Ablation studies: Experiments that remove or alter components of a system to measure each part’s contribution to overall performance. "Our ablation studies reveal that graph-based knowledge representation provides the primary performance gains."
- Atomic knowledge unit: The smallest modality-specific element (e.g., a figure, paragraph, table, or equation) extracted for indexing and retrieval. "This process decomposes raw inputs into atomic knowledge units while preserving their structural context and semantic alignment."
- Belongs_to edges: Explicit graph edges linking fine-grained entities to their parent multimodal unit to preserve structural grounding. "belongs_to edges"
- Canonicalization: Standardizing heterogeneous inputs into a consistent representation to enable uniform processing and retrieval. "This canonicalization enables uniform processing, indexing, and retrieval of multimodal content within our framework."
- Candidate Pool Unification: The process of merging candidates returned by multiple retrieval pathways into a single set for final ranking. "Candidate Pool Unification."
- Cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them. "ranked by cosine similarity scores"
- Cross-modal alignment systems: Mechanisms that map and relate content across different modalities (e.g., text to image) for coherent retrieval and reasoning. "The framework introduces modality-aware query processing and cross-modal alignment systems."
- Cross-modal hybrid retrieval: A retrieval approach that combines graph-structured navigation with dense semantic matching across modalities. "our framework introduces a cross-modal hybrid retrieval mechanism"
- Cross-Modal Knowledge Graph: A graph whose nodes and edges encode entities and relations grounded in non-text modalities (images, tables, equations) and their textual context. "Cross-Modal Knowledge Graph:"
- Dense vector similarity search: Finding semantically related items by comparing high-dimensional embedding vectors. "we conduct dense vector similarity search between the query embedding and all components stored in embedding table "
- Dereferencing: Replacing textual proxies of visual items with the original visual content at synthesis time to preserve semantics. "we perform dereferencing to recover original visual content"
- Dual-graph construction: Building two complementary graphs (multimodal and text-based) and integrating them for richer representation and retrieval. "dual-graph construction"
- Embedding function: The model that converts items (entities, relations, chunks) into dense vectors for similarity-based retrieval. "embedding function tailored for each component type"
- Embedding table: The collection of dense vector representations for all retrievable items in the index. "embedding table"
- Entity alignment: Merging semantically equivalent entities across graphs to form a unified knowledge representation. "Entity Alignment and Graph Fusion."
- Graph fusion: Integrating multiple graphs by aligning and consolidating overlapping entities and relations. "Graph Fusion and Index Creation"
- Graph topology: The structural layout of nodes and edges in a graph, influencing how information can be traversed and inferred. "graph topology"
- Hop distance: The number of edges traversed in a graph when expanding neighborhoods during retrieval. "within a specified hop distance"
- Knowledge graph: A structured representation of entities and their relationships used for retrieval and reasoning. "our unified knowledge graph G"
- Layout-aware parsing: Document parsing that preserves spatial and hierarchical layout to maintain context and relationships. "layout-aware parsing modules"
- Long-context: Scenarios or documents where relevant information spans long sequences, often exceeding typical model context windows. "long-context documents"
- Modality-Aware Query Encoding: Encoding queries while inferring preferred modalities and lexical cues to guide cross-modal retrieval. "Modality-Aware Query Encoding."
- Multi-hop reasoning: Inference that requires traversing multiple linked entities/relations to connect dispersed evidence. "multi-hop reasoning patterns"
- Multimodal LLMs: LLMs that can process and integrate information from multiple modalities, such as text and images. "leverages multimodal LLMs"
- Named entity recognition: NLP technique for identifying and classifying proper nouns and key terms as entities in text. "leveraging named entity recognition and relation extraction techniques"
- Relation extraction: NLP technique for identifying semantic relationships between entities in text. "leveraging named entity recognition and relation extraction techniques"
- Reranking: Reordering initially retrieved candidates using a learned model to improve final relevance. "We use the bge-reranker-v2-m3 model for reranking."
- Semantic similarity matching: Retrieving items based on closeness in embedding space rather than explicit lexical overlap. "Semantic Similarity Matching."
- Spectral clustering: A graph-based clustering method using eigenvectors of similarity matrices to partition data. "spectral clustering for multimodal entity analysis"
- Structural knowledge navigation: Graph-based retrieval that follows explicit relationships and neighborhoods to gather relevant evidence. "Structural Knowledge Navigation."
- t-SNE: A nonlinear dimensionality reduction technique for visualizing high-dimensional data. "t-SNE visualization"
- Token limit: A hard cap on the number of tokens (text units) allowed in inputs or components for processing. "token limit"
- Unified embedding space: A shared vector space where heterogeneous items (entities, relations, chunks across modalities) are jointly represented. "This creates a unified embedding space"
- Vision-LLM (VLM): A model that jointly reasons over visual and textual inputs to produce grounded outputs. "VLM integrates information from query, textual context, and visual content."
Collections
Sign up for free to add this paper to one or more collections.