- The paper introduces a paradigm shift by exclusively using precomputed discrete codec units, bypassing continuous waveform processing for SSL.
- It employs a masked prediction approach with strategies like reconstruction, iterative clustering, and online clustering to match or exceed traditional SSL performance.
- Results show significant efficiency gains, with a 16.5x storage reduction and 2.3x speedup in training, while achieving competitive outcomes on SUPERB benchmarks.
Codec2Vec: Self-Supervised Speech Representation Learning Using Neural Speech Codecs
Introduction and Motivation
The proliferation of SSL paradigms in speech representation learning has catalyzed rapid progress in universal speech understanding, yet continues to face scaling barriers due to the reliance on high-dimensional continuous inputs (waveforms and spectrograms) and the attendant computational and storage costs. The recent emergence of neural audio codecs (DAC, Encodec, SoundStream) introduces highly compressed, information-preserving discrete units that offer a compelling alternative to conventional feature inputs. Building on these advances, "Codec2Vec: Self-Supervised Speech Representation Learning Using Neural Speech Codecs" (2511.16639) proposes a paradigm shift: the exclusive use of pre-computed discrete codec units throughout SSL pre-training, entirely decoupling the foundation model from continuous waveform processing. The approach promises not only substantial efficiency gains but also the potential for scalable, privacy-preserving, and low-latency speech representation learning.
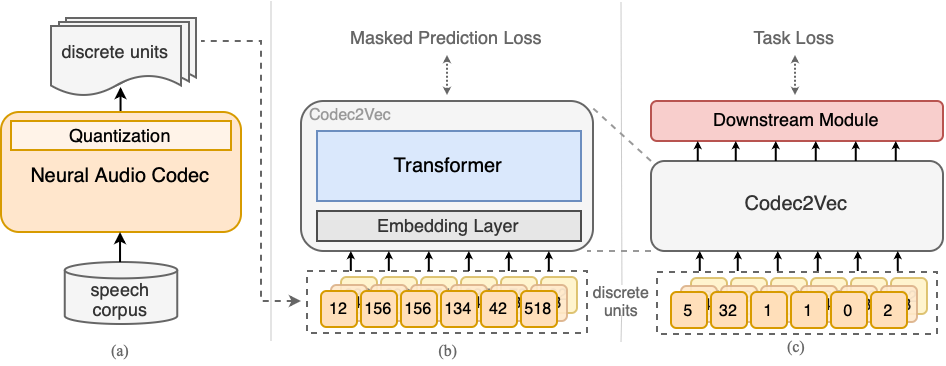
Figure 1: The Codec2Vec pipeline with three stages: (a) offline discrete codec unit extraction, (b) SSL masked prediction pretraining, (c) lightweight finetuning with discretized inputs for downstream tasks.
Methodology
Codec2Vec implements a canonical "pretrain-then-finetune" strategy where all input speech is first compressed by an off-the-shelf neural audio codec, specifically DAC (16kHz, twelve codebooks at 50Hz), resulting in discrete unit sequences that replace continuous representations. These units are mapped to embeddings and aggregated to serve as Transformer inputs. The SSL phase adopts masked prediction as the pretext task, in which random spans of codec unit sequences are masked and the encoder is tasked to predict the identity of the missing discrete units. This architectural bypass of online acoustic feature extraction eliminates the costly convolutional waveform encoder during SSL pre-training. Embedding initialization using pretrained codebook vectors and quantizer dropout enhance robustness.
Three training target derivation strategies are evaluated:
- Reconstruction-based: Predict original codec units, analogous to masked language modeling on discrete speech units.
- Iterative Clustering: Apply k-means clustering to latent representations, refining prediction targets in successive rounds (HuBERT-style iterative training).
- Online Clustering: Teacher-student scheme where a teacher model generates online cluster assignments as targets, updated via EMA of student (following DinoSR).
Experimental Evaluation
The framework is evaluated on the SUPERB benchmark, leveraging 960 hours of LibriSpeech for pre-training. Architecturally, a base Transformer (12 layers, 768 dimensions) is used, with masking applied to 8% of frames in 10-frame spans.
Results on the SUPERB suite (PR, ASR, KS, IC, SF, SD, SV, ER) confirm that Codec2Vec achieves task performance highly competitive with strong continuous-input SSL models:
- With exactly matched HuBERT training targets, the discrete-input Codec2Vec model roughly matches or, for some tasks, marginally exceeds waveform-based HuBERT.
- Cluster-based target strategies (iterative/online) further close the performance gap or outperform baselines in select metrics (e.g., SF, SD, ER).
- Reconstruction-based targets deliver weaker scores, reflecting suboptimality of direct codec unit prediction for abstract contextual modeling.
Notable task-specific results: For phoneme recognition (PR), semantic tasks (SF), and diarization (SD), cluster-based Codec2Vec variants sometimes outperform their waveform-input counterparts, despite the aggressive compression.
Storage and Computational Efficiency
A crucial empirical finding is the 16.5x reduction in dataset storage (60.4 GB waveform vs. 3.6 GB discrete units for the full LibriSpeech corpus), and a 2.3x acceleration in pre-training (356 vs. 830 GPU hours). With discrete units, entire datasets may be loaded into RAM, eliminating I/O bottlenecks and enabling efficient distributed training with minimal resource overhead. The offline codec extraction cost (≈6 GPU hours) is negligible compared to overall pre-training gains. These results substantiate the practicality of Codec2Vec in large-scale or resource-constrained SSL regimes.
Impact of Codec Choice
A direct comparison between DAC and Encodec-derived units shows that DAC consistently enables superior representation learning and downstream performance. The codec's architecture, quantization accuracy, and training objectives critically influence the informativeness of discrete units; thus, codec selection or tailored codec design for SSL remains an open optimization axis.
Discussion and Limitations
Codec2Vec's paradigm introduces several unresolved challenges:
- Codec Selection: Neural audio codecs vary widely in latent information retention. Systematic evaluation and codec optimization remain vital, especially for tasks sensitive to specific acoustic properties.
- Performance Trade-offs: While cluster-based Codec2Vec matches state-of-the-art SSL on most SUPERB tasks, deficits exist for ASR and IC, likely tied to quantization-induced bottlenecks and limitations in adapting continuous-target SSL objectives to fully discrete domains.
- Robustness: Real-world noise robustness is not fully characterized; the interaction of codec compression, input corruption, and SSL objectives under noisy conditions merits further investigation.
Implications and Future Directions
Practically, Codec2Vec facilitates scalable SSL on compressed speech corpora, enabling resource-efficient, privacy-preserving foundation model training. Theoretically, the results challenge the necessity of continuous input spaces for effective speech understanding, motivating a new class of self-supervised objectives and model architectures tailored for discrete modalities. Progress will hinge on codec advancements, refinement of clustering strategies, and specialized SSL losses for quantized units. The approach holds implications for direct deployment of SSL in edge and mobile environments, democratizing access to powerful speech models with minimal compute and storage demands.
Conclusion
Codec2Vec establishes discrete neural audio codec units as a viable and efficient substrate for SSL in speech, eliminating the reliance on continuous inputs without substantial performance compromise. The demonstrated efficiency (16.5x storage, 2.3x training time reduction) alongside competitive downstream metrics across SUPERB benchmarks encourage broader adoption and provide a blueprint for scalable, general-purpose speech foundation modeling. Future research should target codec-driven optimization and discrete-specific SSL objectives to extend the reach and capability of the Codec2Vec paradigm.