- The paper introduces a novel focal modulation-based codec that compresses speech to bitrates as low as 0.16 kbps without sacrificing semantic or acoustic fidelity.
- It achieves competitive performance with a UTMOS of 4.05 and a dWER of 2.18 on LibriSpeech test-clean, outperforming multi-codebook models in resynthesis and voice conversion.
- Ablation studies confirm that focal modulation and binary spherical quantization are crucial for balancing compression efficiency with high-quality generative and discriminative speech tasks.
FocalCodec: Low-Bitrate Speech Coding via Focal Modulation Networks
Introduction and Motivation
The FocalCodec framework addresses the persistent challenge in neural speech coding: achieving high-quality speech reconstruction and robust semantic representation at ultra-low bitrates, while maintaining architectural simplicity for downstream generative and discriminative tasks. Existing neural codecs often rely on multi-codebook designs, which increase complexity and computational cost, or sacrifice either semantic or acoustic fidelity at low bitrates. FocalCodec introduces a hybrid codec architecture leveraging focal modulation networks and a single binary codebook, compressing speech to bitrates as low as 0.16 kbps. The design is motivated by the need for efficient tokenization that preserves both semantic and acoustic information, enabling high-quality resynthesis, voice conversion, and downstream modeling.
Architecture and Design Choices
FocalCodec is built upon the VQ-VAE paradigm but innovates with a compressor-quantizer-decompressor pipeline between the encoder and decoder. The encoder utilizes the first six layers of WavLM-large, capturing both semantic and acoustic features. This choice is substantiated by prior work demonstrating that lower layers of self-supervised models retain significant acoustic detail, which is essential for hybrid codecs.
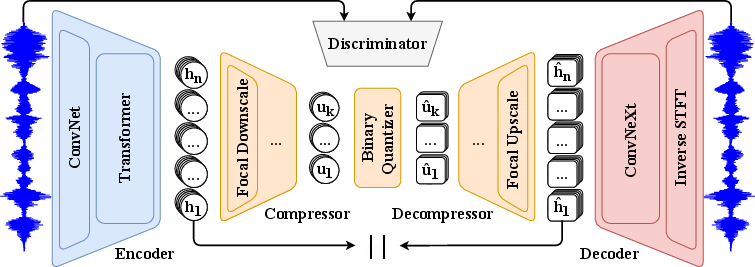
Figure 1: FocalCodec architecture. The encoder extracts features containing both acoustic and semantic information. These features are then mapped to a low-dimensional space by the compressor, binary quantized, and projected back by the decompressor. The decoder resynthesizes the waveform from these features.
The compressor employs focal modulation blocks, replacing conventional self-attention with a mechanism that aggregates global context and modulates local interactions hierarchically. This approach introduces translation equivariance, explicit input dependency, and efficient long-range dependency modeling, which are beneficial for speech representation. The quantizer utilizes binary spherical quantization (BSQ), a lookup-free method that projects latent vectors onto a unit hypersphere and applies binary quantization, resulting in a codebook size of 2L for latent dimension L. This enables granular quantization and high codebook utilization without the overhead of explicit codebook management.
The decompressor mirrors the compressor, reconstructing continuous encoder representations from quantized codes. The decoder adopts an asymmetric design, allocating more parameters to the encoder to prioritize representation quality, while using a lightweight Vocos architecture for efficient waveform synthesis. Training is decoupled: the compressor, quantizer, and decompressor are trained to reconstruct encoder features, while the decoder is trained to resynthesize audio from these features, using adversarial, reconstruction, and feature matching losses.
Experimental Results
Speech Resynthesis
FocalCodec demonstrates competitive performance in speech resynthesis across clean, multilingual, and noisy conditions. At 0.65 kbps (FocalCodec@50), it achieves a UTMOS of 4.05 and dWER of 2.18 on LibriSpeech test-clean, outperforming BigCodec and other state-of-the-art baselines in intelligibility and speaker similarity. The model generalizes well to multilingual speech and noisy environments, maintaining low dWER and high speaker similarity even at ultra-low bitrates.
Subjective Evaluation
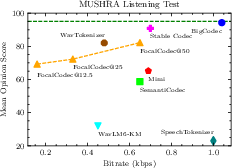
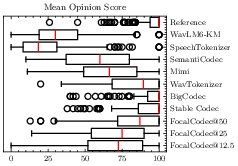
Figure 2: Subjective evaluation from 21 participants averaged over 10 samples. Left: Trade-off between mean opinion score and bitrate. Right: Distribution of mean opinion score. FocalCodec@50 median is marginally lower than BigCodec, Stable Codec, and WavTokenizer, but user preference remains comparable when accounting for variability.
Subjective MUSHRA tests confirm that FocalCodec is Pareto-optimal up to 0.50 kbps, with user preference comparable to higher-bitrate codecs. The trade-off between perceived quality and bitrate is well-balanced, and FocalCodec maintains strong downstream task performance.
Voice Conversion
FocalCodec achieves the highest speaker similarity in one-shot voice conversion tasks, outperforming multi-codebook hybrid codecs such as SpeechTokenizer and Mimi, despite its single-codebook design. This indicates effective disentanglement of speaker and content information, a property typically associated with more complex architectures.
Downstream Tasks
On discriminative tasks (ASR, SI, SER), FocalCodec@50 ranks among the top models, with WER and error rates comparable to or better than multi-codebook and fine-tuned semantic codecs. On generative tasks (speech enhancement, separation, TTS), FocalCodec@50 and its lower-bitrate variants maintain high performance, with [email protected] excelling in TTS due to its compact token sequence, which simplifies autoregressive modeling.
Mel-Spectrogram Analysis
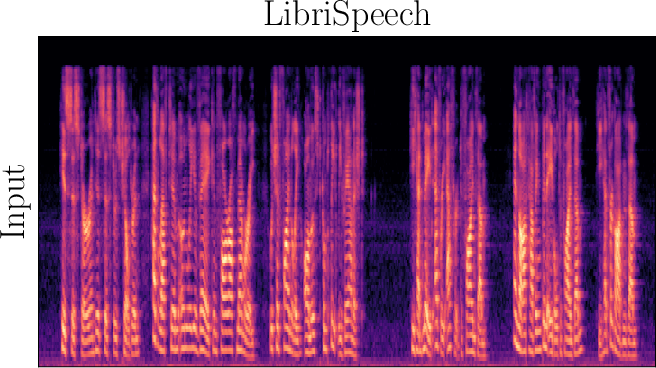
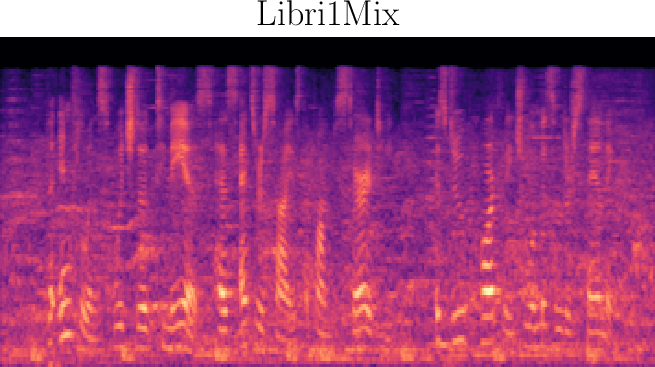
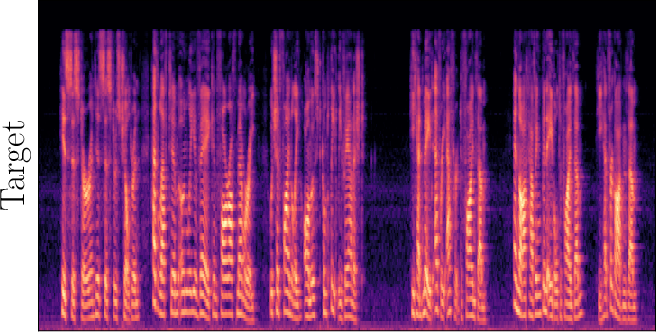
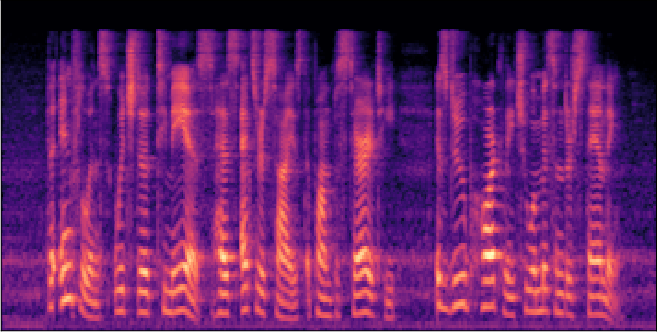
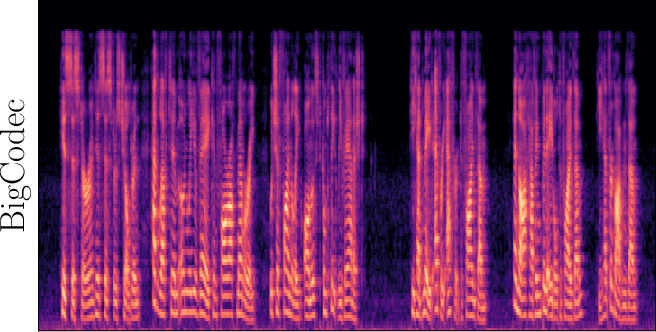
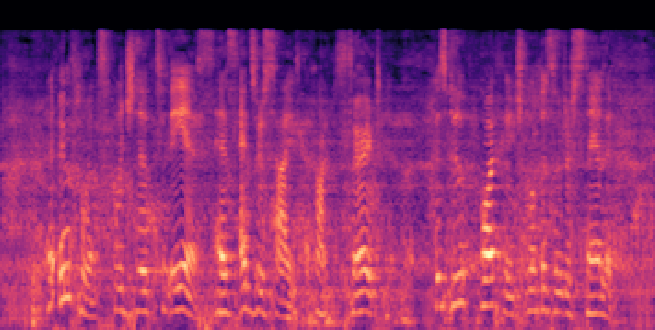
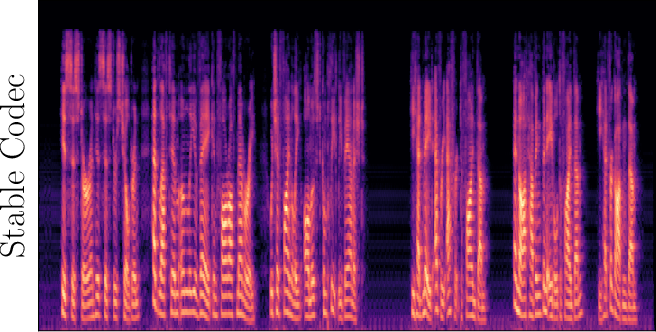
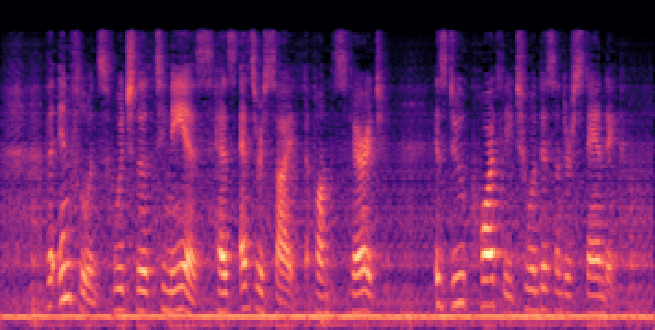
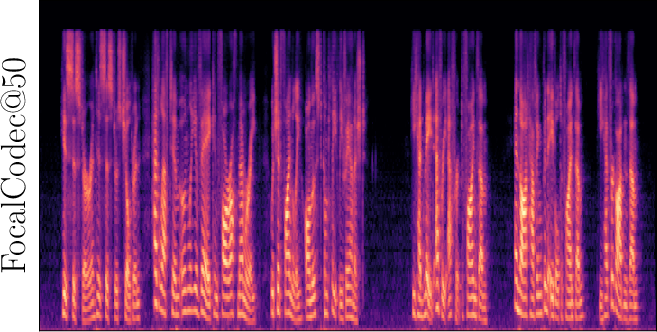
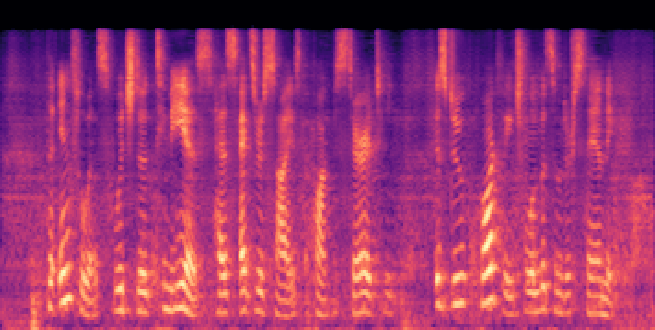
Figure 3: Reconstructed Mel-spectrograms from LibriSpeech (left) and Libri1Mix (right).
Spectrogram analysis reveals that FocalCodec preserves speech energy in relevant frequency bands, outperforming purely acoustic codecs in denoising and intelligibility, and avoiding artifacts introduced by other hybrid codecs.
Ablation and Comparative Studies
Ablation studies validate the architectural choices: replacing focal modulation with Conformer or AMP blocks, or substituting BSQ with vanilla LFQ, degrades performance in both objective and subjective metrics. The use of focal modulation and BSQ is critical for achieving the observed trade-off between compression and representation quality.
Comparisons with TS3-Codec, a transformer-only streaming codec, show that FocalCodec@50 surpasses TS3-Codec in all evaluated metrics, and FocalCodec@25 remains competitive at a significantly lower bitrate.
Implementation Considerations
FocalCodec is non-causal but can be streamed chunk-wise with acceptable performance at moderate chunk sizes. The model is trained on clean English speech at 16 kHz, with potential for further improvement through multilingual and higher-sample-rate training. The architecture is not optimized for music or environmental sounds, focusing exclusively on speech.
Implications and Future Directions
FocalCodec demonstrates that single-codebook, focal modulation-based architectures can achieve high-quality, low-bitrate speech coding without sacrificing semantic or acoustic fidelity. The efficient tokenization and robust representation learning make it well-suited for generative modeling, voice conversion, and downstream speech tasks. The use of BSQ and focal modulation introduces new avenues for scalable, efficient codec design.
Future work should address causality for real-time applications, expand training to broader domains and higher sample rates, and explore explicit mixture training for improved speech separation. The principles established by FocalCodec may inform the design of tokenizers for multimodal and cross-lingual speech models, as well as efficient codecs for edge deployment.
Conclusion
FocalCodec presents a significant advancement in low-bitrate neural speech coding, combining focal modulation networks and binary spherical quantization in a single-codebook architecture. It achieves competitive performance in speech resynthesis, voice conversion, and downstream tasks at ultra-low bitrates, with efficient token utilization and robust representation learning. The framework sets a new standard for codec simplicity and effectiveness, with broad implications for generative and discriminative speech modeling.