- The paper introduces a spectral codec that leverages FSQ quantization of mel-spectrograms to enable more effective non-autoregressive TTS synthesis.
- It employs a modified HiFi-GAN architecture with multi-band FSQ to simplify latent representations and enhance audio reconstruction.
- Results demonstrate comparable reconstruction quality and superior token accuracy, highlighting practical improvements for efficient TTS systems.
Spectral Codecs for Non-Autoregressive Speech Synthesis
Introduction
The development of neural Text-to-Speech (TTS) systems predominantly utilizes the mel-spectrogram as the speech representation, which is advantageous due to its compressibility into a latent space conducive for probabilistic prediction models such as VAEs. Traditional systems faced limitations due to over-smoothness resulting from regression losses. In recent times, discrete audio tokens produced by neural audio codecs have emerged as prominent speech representations for TTS tasks. These tokens, however, present complex data distributions that non-autoregressive models struggle to predict effectively. This work introduces a spectral codec that quantizes mel-spectrogram features to improve audio quality in non-autoregressive TTS.
Methodology
Spectral Codec Architecture
The proposed spectral codec utilizes a modified version of the HiFi-GAN architecture (Figure 1). The architecture encodes mel-spectrograms through residual blocks and quantizes them using Finite Scalar Quantizer (FSQ), allowing non-autoregressive models to predict them with relative ease. Three quantization methods were explored: standard RVQ, FSQ, and multi-band FSQ. The multi-band approach enhances performance by distributing mel-bands equally among separate encoders, creating distinct codebooks for each set.
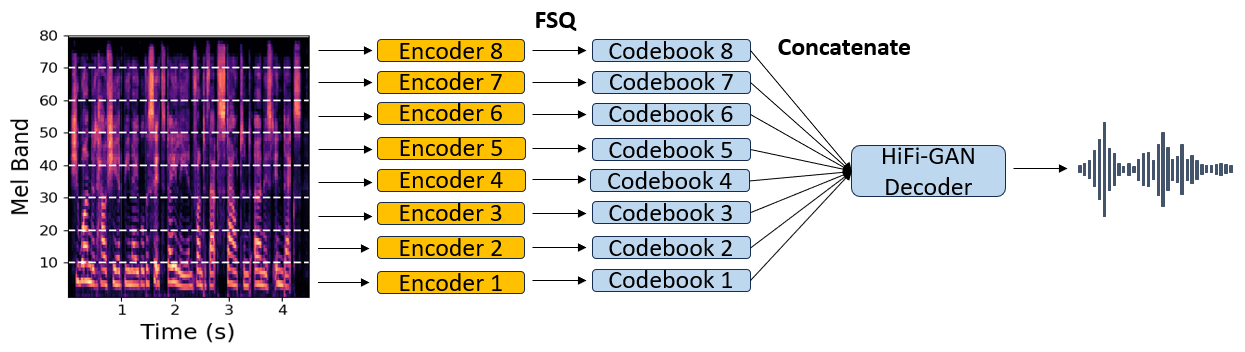
Figure 1: Architecture of the proposed multi-band spectral codec. Disjoint mel-bands are encoded separately and quantized using an FSQ. All codebook embeddings are concatenated and given as input to a HiFi-GAN decoder which predicts the final waveform.
Audio Codec Architecture
An inverted HiFi-GAN decoder is employed to create a symmetric encoder-decoder audio codec. This codec quantizes time-domain audio signals, similar to spectral codecs but operates over audio waveforms. The architecture includes symmetric upsampling and downsampling rates, maintaining competitive performance across reconstructed time-domain signals.
Training Objective and Evaluation
The models were trained with multi-resolution mel-spectrogram and STFT losses, incorporating discriminator setups to enhance phase estimation. Evaluation employed a combination of instrumental metrics and informal listening tests to assess codec efficiency. TTS models were trained with FastPitch, adjusted for softmax prediction of FSQ-encoded tokens to test synthesis quality.
Results and Discussion
In evaluating codec performances (Table 1), the spectral codec displayed similar perceptual quality to traditional audio codecs across metrics like ViSQOL and mel-spectrogram reconstruction. While time-domain losses indicated variability, the overall differences were minimal in reconstructions, emphasizing spectral codecs' potential for comparable quality despite the reduced complexity in token generation.
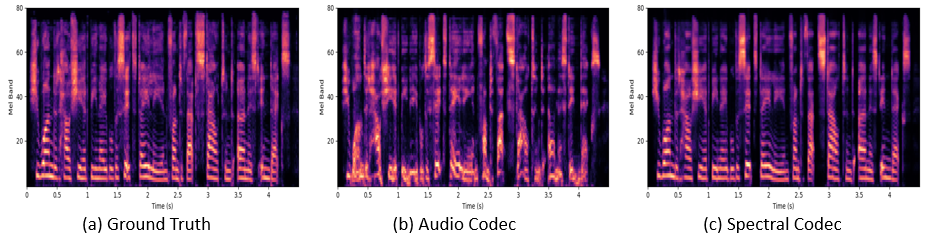
Figure 2: Mel-spectrogram examples: (a) ground truth speech, (b) TTS output generated from the audio codec with RVQ, and (c) TTS output generated from the multi-band spectral codec.
TTS performance indicated that non-autoregressive models trained on spectral codecs produced significantly higher quality audio compared to those trained on time-domain codecs (Table 2). Spectral codecs using FSQ provided superior synthesis results, achieving clearer and more accurate audio output. These models exhibited enhanced token accuracy, underscoring the advantage of a well-structured flat codebook in FSQ for TTS systems.
Conclusion
This study introduced a spectral codec paradigm that improves TTS outputs by simplifying the latent space predictions via FSQ. Comparisons between mel-spectrogram quantization and time-domain signal compression revealed comparable reconstruction quality, while the former facilitated superior audio synthesis in non-autoregressive models. Future work will expand on these findings across additional speech synthesis systems to further validate the proposed model's efficacy in varying contexts. The implications of shifting towards spectral codecs can influence the design of future high-efficiency TTS architectures.