Key Decision-Makers in Multi-Agent Debates: Who Holds the Power?
Abstract: Recent studies on LLM agent scaling have highlighted the potential of Multi-Agent Debate (MAD) to enhance reasoning abilities. However, the critical aspect of role allocation strategies remains underexplored. In this study, we demonstrate that allocating roles with differing viewpoints to specific positions significantly impacts MAD's performance in reasoning tasks. Specifically, we find a novel role allocation strategy, "Truth Last", which can improve MAD performance by up to 22% in reasoning tasks. To address the issue of unknown truth in practical applications, we propose the Multi-Agent Debate Consistency (MADC) strategy, which systematically simulates and optimizes its core mechanisms. MADC incorporates path consistency to assess agreement among independent roles, simulating the role with the highest consistency score as the truth. We validated MADC across a range of LLMs (9 models), including the DeepSeek-R1 Distilled Models, on challenging reasoning tasks. MADC consistently demonstrated advanced performance, effectively overcoming MAD's performance bottlenecks and providing a crucial pathway for further improvements in LLM agent scaling.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how groups of AI “agents” (think: many AI chatbots) can debate each other to solve hard problems better. The authors show that where each agent sits in the speaking order really matters. Their big discovery is a simple rule called “Truth Last”: if the agent with the correct idea speaks last, the group is more likely to end up with the right answer. They also invent a way to approximate this in real life, even when we don’t know who’s right, called MADC (Multi-Agent Debate Consistency).
What questions did the researchers ask?
To make this easy to follow, imagine a classroom debate with several students:
- Does the order in which students speak change the final decision?
- Is there a best way to arrange who speaks when, so the group is more accurate?
- Can we copy the benefits of putting the correct student last, even if we don’t know who’s correct?
- Do these ideas still help when we add more debate rounds or more students (agents)?
How did they study it?
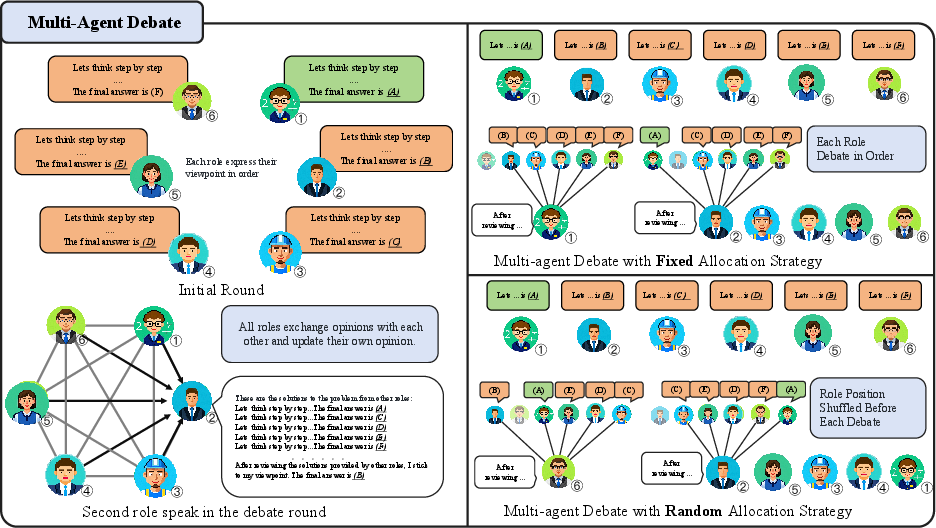
The team used groups of AI agents that debate the answer to a question, like a logic puzzle or a geometry quiz. Each agent thinks step-by-step (this is called Chain of Thought, like showing your work in math), shares its reasoning, listens to others, and updates its answer over one or more rounds.
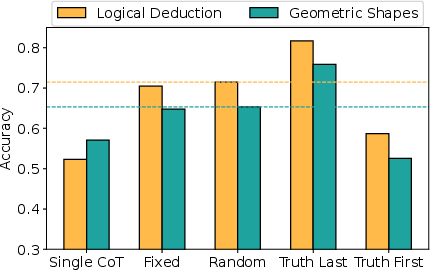
They tested different “role allocation strategies,” which is just a fancy way to say “who talks when”:
- Fixed: everyone keeps the same speaking order each round.
- Random: the speaking order changes randomly.
- Truth First: the agent with the correct idea speaks early.
- Truth Last: the agent with the correct idea speaks last.
Of course, in real life we don’t know who’s correct. So they designed MADC:
- Path consistency: Imagine each agent taking a path through their reasoning. If many agents’ paths point to the same answer at the same time, that answer is more “consistent.” It’s like multiple students working separately and independently landing on the same result—it’s a strong signal it might be right.
- MADC uses this agreement signal to guess which agent is most likely right and then arranges the speaking order so that agent goes later (imitating “Truth Last”) without needing to know the actual truth.
They tried this across 9 different LLMs (including GPT-4o-mini, Qwen, GLM, and DeepSeek-R1 Distill) on three kinds of hard tasks: logic puzzles, geometry descriptions, and multi-step math problems (MATH500).
Quick translations of technical terms:
- Chain of Thought (CoT): showing your steps, not just the final answer.
- Entropy: a measure of disagreement. High entropy = lots of mixed opinions; low entropy = more agreement.
- Path consistency: how much independent agents’ reasoning paths line up on the same answer.
What did they find?
Here are the main results, explained simply:
- Speaking order matters a lot. Putting the correct agent last (“Truth Last”) can boost accuracy by up to 22% on tough reasoning tasks.
- Order brings agreement. More orderly speaking arrangements make the group settle on a shared answer more easily (lower “entropy”), without hurting accuracy.
- MADC works in practice. Even when we don’t know who’s right, using path consistency to reorder speakers improves results across many models and tasks. It’s a drop-in method—you don’t have to change the prompts or the debate format.
- Later speakers have more power. Agents who speak later tend to sway the final decision more, whether they’re right or wrong.
- Fewer agents can flip the outcome. Under ideal conditions, only about half as many agents are needed to overturn a debate’s conclusion—showing how influential speaking order and late positions are.
- The benefits hold as you scale. The advantages of “Truth Last” and MADC remain when you add more debate rounds or more agents.
Why does this matter?
This research gives a simple, powerful insight: in AI group debates, who talks last can change the final answer. That means we can improve AI reasoning not just by making a single model bigger, but by organizing teams of models better.
The practical impact:
- More accurate AI teamwork: By reordering agents using MADC, we can get better answers without changing model prompts or training.
- Works across models and tasks: The idea is robust—from logic puzzles to geometry and math, and across both open and closed models.
- A new “scaling” lever: Beyond adding more agents or more rounds, smarter speaking order is a new way to boost performance.
In short, the paper shows that debate structure matters. If we let the most reliable voice speak last—and if we don’t know who that is, we estimate it by who many others independently agree with—AI teams can reason more accurately and consistently.
Collections
Sign up for free to add this paper to one or more collections.

