- The paper presents a comprehensive evaluation of 12 uncertainty estimation methods applied to LLMs in both in-distribution and out-of-distribution QA settings.
- The methodology compares semantic, information-based, density-based, and reflexive techniques, highlighting that information-based methods excel on ID tasks while density-based and reflexive methods perform better on OOD tasks.
- The findings underscore the importance of selecting appropriate uncertainty metrics to improve trustworthiness and performance of LLM-driven QA systems in diverse contexts.
Measuring Aleatoric and Epistemic Uncertainty in LLMs: An Empirical Study
This essay provides an in-depth exploration and analysis of the paper titled "Measuring Aleatoric and Epistemic Uncertainty in LLMs: Empirical Evaluation on ID and OOD QA Tasks" (2511.03166). This paper undertakes a comprehensive empirical investigation into the robustness and efficacy of different Uncertainty Estimation (UE) methods applied to LLMs across both In-Distribution (ID) and Out-of-Distribution (OOD) datasets in Question-Answering (QA) tasks. The nuanced approach considers aleatoric and epistemic uncertainties, with implications for developing trustworthiness in LLM outputs.
Introduction
LLMs are increasingly pervasive in various applications, necessitating a mechanism to ascertain the trustworthiness of their responses. Uncertainty estimation plays a critical role in this context, where high-quality, robust measures are needed to discern the model's confidence in generating responses. This paper evaluates twelve diverse UE methods in tandem with four generation quality metrics, including LLMScore from LLM criticizers, to assess uncertainty in LLM-generated answers. The empirical study spans ID and OOD datasets, highlighting the challenges in evaluating random aleatoric uncertainty inherent within distribution data and epistemic uncertainty encountered with novel, unknown data.
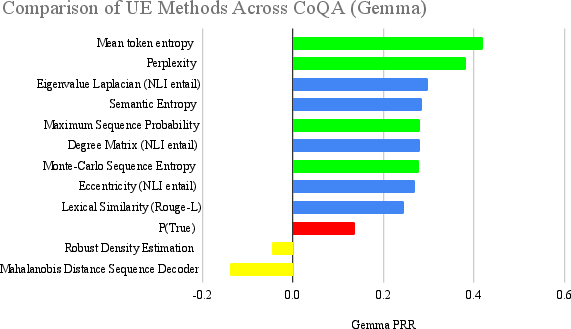
Figure 1: Ranking of UE Methods on CoQA, using LLMScore with Gemma.
Uncertainty Estimation Methods
The paper categorizes UE methods into four primary classes based on their approach and underlying principles:
Experiments and Results
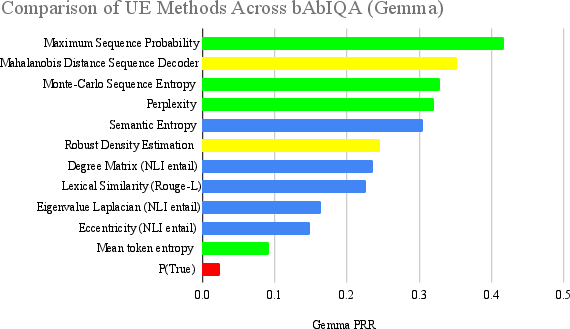
The paper rigorously tests these UE methods across three datasets: CoQA, bAbIQA, and ALCUNA. CoQA and bAbIQA serve as ID datasets, whereas ALCUNA provides insights into OOD scenarios. Results indicate that information-based methods excel in ID contexts, offering robust performance related to aleatoric uncertainty. Conversely, density-based methods and P(True) demonstrate superior capability in OOD contexts, effectively managing epistemic uncertainty.
Key findings suggest semantic consistency methods are generally reliable but not universally optimal. Information-based methods align well with the structured nature of ID tasks due to their token probability reliance. Density-based methods reveal their adaptability to novel data in OOD contexts. Reflexive methods like P(True) shed light on the LLM's potential self-awareness in estimating its own uncertainty.
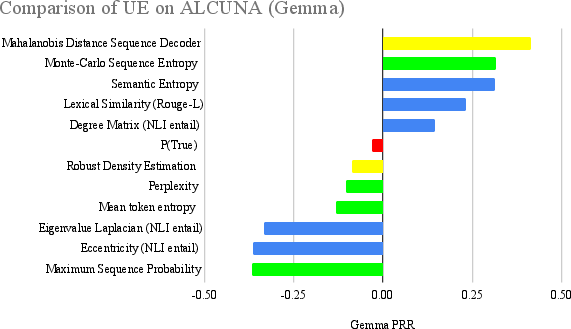
Figure 3: Ranking of UE Methods on ALCUNA, using LLMScore with Gemma.
Implications and Future Directions
The implications of this research span theoretical and practical domains. Practically, deploying the most suitable UE method based on data context and uncertainty type can enhance trust and efficacy in real-world applications of LLMs, such as QA systems and conversational agents. Theoretically, the study advances understanding of the mechanisms underlying uncertainty, aiding in the architecture design and refinement of upcoming models.
Looking forward, the research encourages exploration of more OOD datasets and suggests pre-training models on specific tasks to evaluate effects on UE performance. Future investigation may also consider evolving model architectures, like newer iterations of LLMs, to assess their inherent uncertainty handling mechanisms.
Conclusion
This paper presents a thorough evaluation of UE methods applied to LLMs, revealing nuanced insights into aleatoric and epistemic uncertainties. The careful selection and application of these methods are crucial for optimizing LLM performance and ensuring trustworthy AI systems. By disentangling different uncertainty types and evaluating method effectiveness across diverse datasets, this work lays a robust foundation for future inquiries into improving the reliability of LLM outputs in complex, dynamic environments.