- The paper introduces a novel framework that quantifies uncertainties in LLM in-context learning by decomposing aleatoric and epistemic factors.
- It employs entropy-based and Bayesian methods to estimate prediction variance and detect misclassifications with rigorous performance on sentiment tasks.
- Experimental evaluation on models like LLaMA-2 and OPT demonstrates improved detection of in-domain versus out-of-domain demonstrations and semantic shifts.
Uncertainty Quantification for In-Context Learning of LLMs
Introduction
The paper "Uncertainty Quantification for In-Context Learning of LLMs" investigates the reliability of responses generated by LLMs when implementing in-context learning. This learning paradigm enables LLMs to adapt rapidly to new tasks by using a prompt containing relevant demonstrations. Despite their success, LLMs face challenges like hallucination and predictive uncertainty, which could compromise the trustworthiness of their responses. This study aims to quantify and decompose uncertainties arising from aleatoric factors (variability in demonstrations) and epistemic factors (model configuration variabilities).
Uncertainty Sources in LLM Predictions
Uncertainty in LLM predictions can be traced back to the quality of demonstrations provided and the LLM's internal configuration settings. Demonstrations of insufficient quality can lead to incorrect predictions as they may not capture the full spectrum necessary for accurate task interpretation. On the other hand, variations in model configuration such as different decoding strategies (e.g., beam search or top-k sampling) may also yield divergent outputs, exacerbating epistemic uncertainty.
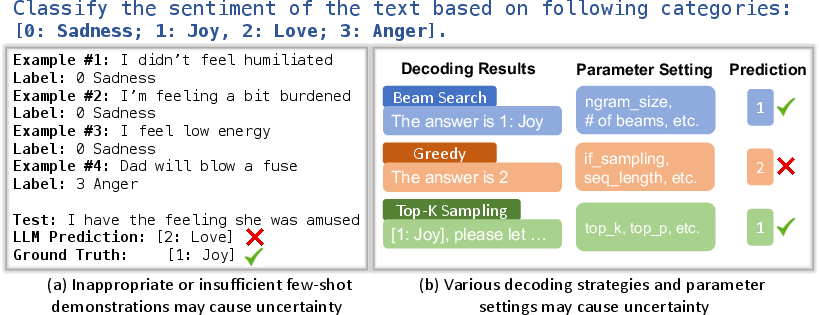
Figure 1: Uncertainty in LLM's prediction can stem from two aspects: a) Demonstration Quality: LLMs are likely to make wrong predictions if the demonstrations are inappropriate; b) Model Configuration: different decoding strategies (e.g., beam search and top_k sampling) and their parameter settings may return different predictions.
Framework for Uncertainty Quantification
The framework for estimating and decomposing uncertainty into its aleatoric and epistemic components is based on entropy measures. Epistemic uncertainty is characterized by the variability across multiple configurations, while aleatoric uncertainty is quantified through the variability in sampled demonstrations confined to a fixed model configuration. The authors deploy a robust Bayesian approach to disentangle these uncertainties and provide a structured methodology for their estimation in practical settings.
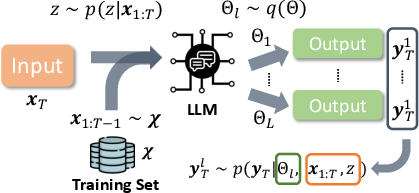
Figure 2: Uncertainty Quantification of In-context Learning Pipeline: we want to quantify the uncertainty that comes from 1) different in-context demonstrations x1:T; and 2) different model configurations Θl.
Entropy-Based Estimation Methodology
The estimation framework capitalizes on sequence-based variance and entropy in multiple decoded outputs. This involves generating numerous sequences from a given demonstration set and evaluating the entropy of token distributions to estimate uncertainty effectively. By iterating this process across multiple sets, the framework can aggregate a comprehensive uncertainty quantification matrix that succinctly captures the model's prediction reliability.
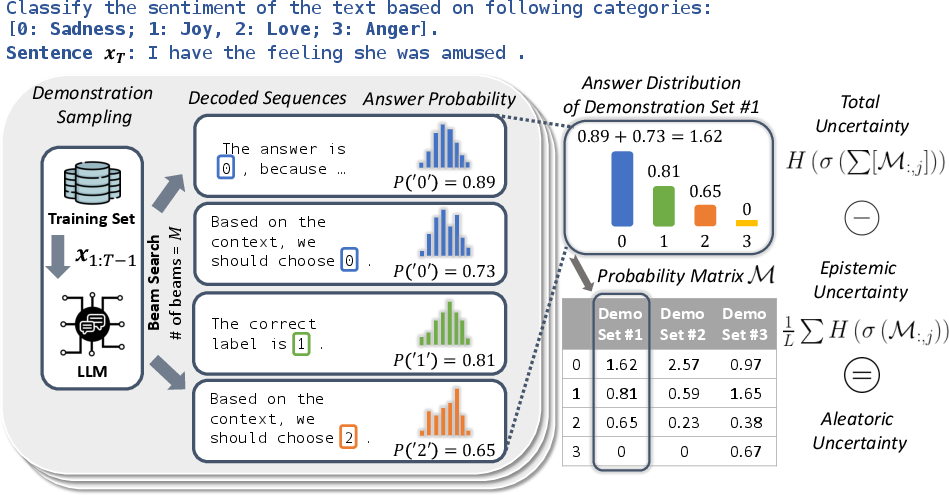
Figure 3: Framework of entropy-based uncertainty estimation, which consists of 1) generating M sequences based on a set of x1:T; 2) selecting token(s) relevant to the answer and extracting the probabilities; 3) aggregating the token probabilities of M sequences into a distribution of predicted labels; 4) iterating the process L times corresponding to L different demonstration sets and forming a probability matrix M.
Experimental Evaluation
The authors rigorously test the proposed uncertainty quantification metrics across multiple sentiment analysis datasets using various LLM architectures, including LLaMA-2 and OPT models. The experiments demonstrate that the epistemic and aleatoric decompositions provide superior estimates of misclassification rates compared to existing methods. Both precision-recall (PR) curves and Receiver Operating Characteristic (ROC) analyses confirm that the framework efficiently distinguishes in-domain from out-of-domain demonstrations and detects semantic shift scenarios.
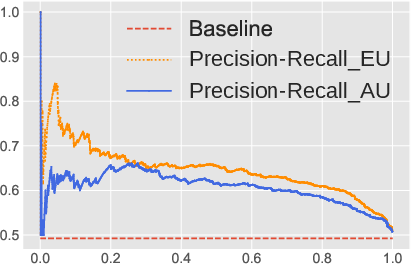
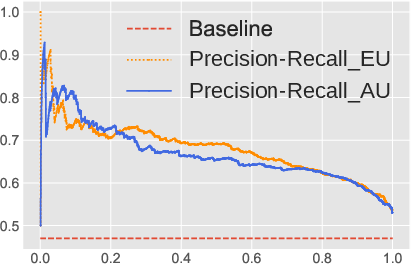
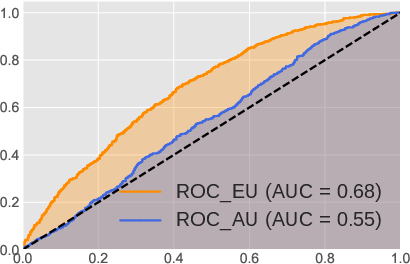
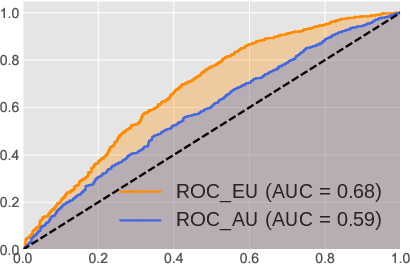
Figure 4: The performance of misclassification rate using two backbone LLMs: OPT-13B and LLaMA-2-13B on Emotion dataset. (a) and (b) demonstrate the precision-recall curves (x-axis is the recall and y-axis is the precision) for OPT-13B and LLaMA-2-13B; (c) and (d) demonstrate the ROC curve (x-axis is the false positive rate and y-axis is the true positive rate) for OPT-13B and LLaMA-2-13B, respectively.
Conclusion
The paper contributes a sophisticated framework for quantifying and decomposing uncertainty in LLM outputs. By leveraging Bayesian and entropy-based techniques, it advances the understanding of confidence in model predictions, crucial for deploying LLMs in practical contexts where reliability is paramount. Future directions involve refining the approach for generative tasks and extending applicability to other data and model types, promising further insights into uncertainty in expansive AI models.