- The paper introduces a diffusion-based latent dynamic reconstruction model that efficiently generates deformable 3D Gaussian fields from a single image.
- It integrates camera conditions and motion losses, achieving superior video synthesis metrics and significantly reducing reconstruction time.
- The method enables unified video generation, novel view synthesis, and geometry extraction in a single forward pass, advancing 4D scene generation.
Diff4Splat: Controllable 4D Scene Generation with Latent Dynamic Reconstruction Models
Introduction
The paper "Diff4Splat: Controllable 4D Scene Generation with Latent Dynamic Reconstruction Models" introduces a novel approach for generating 4D scenes from a single image using a diffusion-based method. This approach aims to address the limitations of existing monocular 4D reconstruction methods, which often suffer from extensive optimization requirements or lack of flexibility. Diff4Splat unifies video diffusion models with geometry and motion constraints to efficiently predict a deformable 3D Gaussian field directly from a single image input. The resulting framework is capable of handling video generation, novel view synthesis, and geometry extraction in a single forward pass, significantly surpassing existing methods in both quality and efficiency.

Figure 1: Given a single image, a specified camera trajectory, and an optional text prompt, our diffusion-based framework directly generates a deformable 3D Gaussian field without test-time optimization.
Methodology
The core of Diff4Splat's framework is its innovative video latent transformer, which processes video diffusion latents to jointly capture spatio-temporal dependencies and predict time-varying 3D Gaussian primitives. This method is supported by a large-scale 4D dataset construction pipeline, which converts real-world videos into annotated spatio-temporal pointmaps. Key contributions include:
- Latent Dynamic Reconstruction Model (LDRM): This model integrates camera conditions with generated latent features, allowing for the prediction of a deformable Gaussian field that enables rendering at novel viewpoints and time instances.
- Deformable Gaussian Fields: By augmenting static 3D Gaussian representations with inter-frame deformation mechanisms, the model aptly handles dynamic scene generation.
- Unified Supervision Scheme: A robust training strategy incorporating photometric, geometric, and motion losses ensures high-fidelity texture synthesis and enforces geometric constraints.
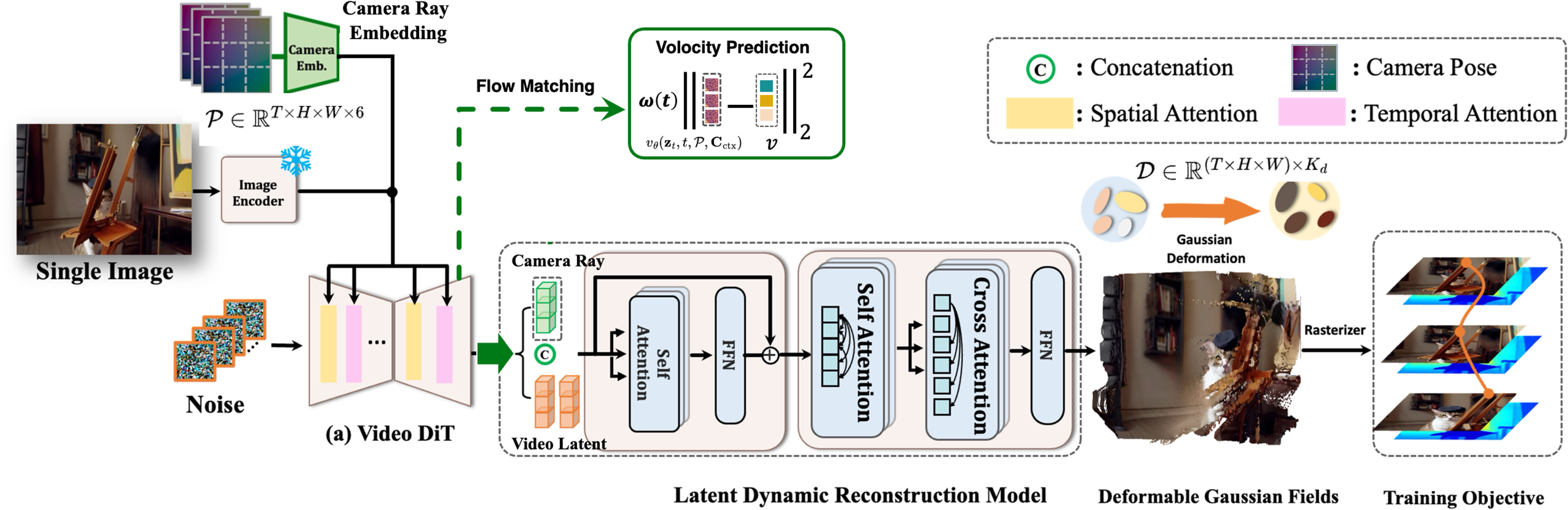
Figure 2: Architecture of Diff4Splat, showing a high-fidelity dynamic 3DGS generation method from a single image through key innovations.
Experimental Evaluation
The paper presents extensive evaluations demonstrating the model's superiority over current state-of-the-art methods. Key metrics such as Fréchet Video Distance (FVD), Kernel Video Distance (KVD), and CLIP-Score, alongside novel geometric integrity assessments, substantiate the model's performance. Diff4Splat achieves a reconstruction time of approximately 30 seconds, highlighting its efficiency advantage over optimization-heavy counterparts like Mosca, which requires significantly longer computation times.
Implications and Future Work
Diff4Splat represents a significant step forward in the field of 4D scene generation by offering a unified diffusion-based approach that efficiently balances quality and computational demands. Its ability to generate photorealistic and temporally-consistent scenes opens new avenues for applications in immersive XR content creation, realistic simulation environments for robotics, and autonomous driving.
Future work may focus on enhancing the model's temporal coherence and refining material property predictions to further expand its applicability across different domains. Additionally, tackling issues related to motion ambiguity and generalization to out-of-distribution inputs will be pivotal in achieving more robust performance.
Conclusion
In summary, Diff4Splat sets a new benchmark in controllable 4D scene synthesis by marrying the strengths of diffusion models with advanced geometric and motion constraints. Its ability to generate high-fidelity scenes rapidly, without the need for iterative optimization, marks a substantial advancement in the domain, paving the way for more scalable and efficient solutions in AI-driven scene generation.
