- The paper introduces a direct 4DMesh-to-GS VAE combined with a temporally-aware diffusion model that encodes 3D animation sequences into a compact latent space.
- The paper achieves high-fidelity 4D content with superior metrics (e.g., PSNR 18.47, SSIM 0.901) and rapid inference (4.5 seconds on a single A100 GPU).
- The paper demonstrates robust generalization to in-the-wild video inputs, enabling practical animation workflows by transferring video motion to 3D assets.
Gaussian Variation Field Diffusion for High-fidelity Video-to-4D Synthesis
Introduction and Motivation
The paper addresses the challenge of high-fidelity 4D content generation, specifically synthesizing dynamic 3D (i.e., 4D) objects from monocular video. The core technical bottlenecks in this domain are the high computational cost of per-instance 4D Gaussian Splatting (GS) fitting and the intractability of direct high-dimensional 4D diffusion modeling. The authors propose a two-stage generative framework: (1) a Direct 4DMesh-to-GS Variation Field VAE that encodes 3D animation sequences into a compact latent space, and (2) a Gaussian Variation Field diffusion model that learns to generate temporally coherent dynamic content conditioned on video and canonical GS. This approach enables efficient, scalable, and high-quality video-to-4D synthesis, with strong generalization to in-the-wild video inputs.
Methodology
Direct 4DMesh-to-GS Variation Field VAE
The VAE is designed to efficiently encode 3D animation data into a compact latent space, bypassing the need for per-instance 4DGS optimization. The process begins by converting mesh animation sequences into point clouds, from which displacement fields are computed relative to a canonical frame. A pretrained mesh-to-GS autoencoder is used to obtain the canonical GS representation. To encode motion, a cross-attention transformer aggregates temporal displacements into a fixed-length latent, with mesh-guided interpolation ensuring spatial correspondence between mesh vertices and GS points. The VAE compresses high-dimensional motion sequences (e.g., 8192 points) into a 512-dimensional latent, facilitating tractable diffusion modeling.
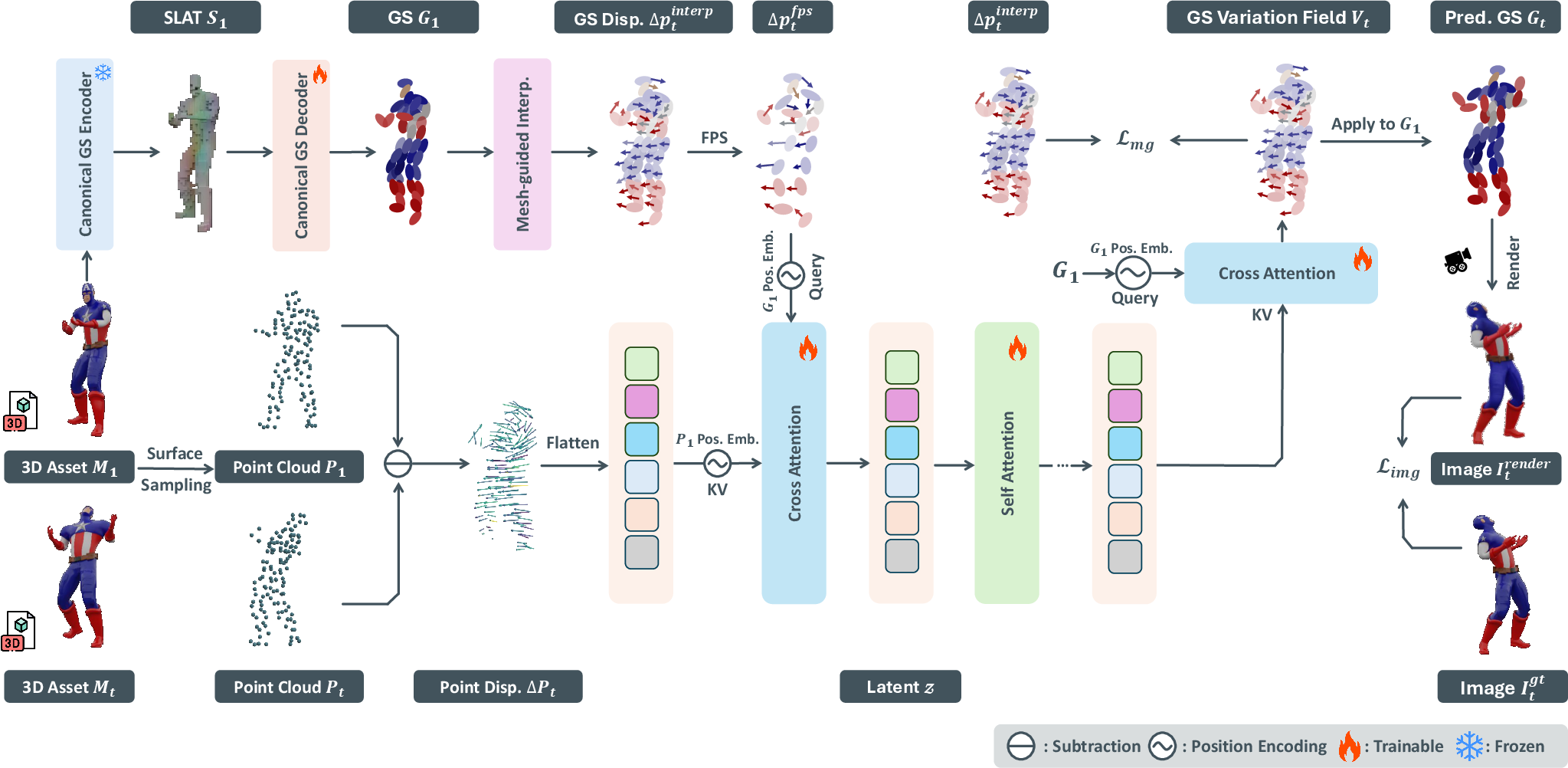
Figure 1: Framework of 4DMesh-to-GS Variation Field VAE. The VAE encodes 3D animation data into Gaussian Variation Fields in a compact latent space, optimized with image-level and mesh-guided losses.
The decoder reconstructs the Gaussian Variation Fields (positions, scales, rotations, colors, opacities) from the latent, using cross-attention with canonical GS attributes as queries. The final 4DGS sequence is obtained by applying the decoded variations to the canonical GS.
Gaussian Variation Field Diffusion Model
The diffusion model operates in the VAE's latent space, leveraging a Diffusion Transformer (DiT) architecture with both spatial and temporal self-attention. Conditioning is provided by visual features (extracted from video frames via DINOv2) and geometric features (canonical GS), injected via cross-attention. Positional priors based on canonical GS positions are incorporated to enhance spatial-temporal correspondence during denoising.
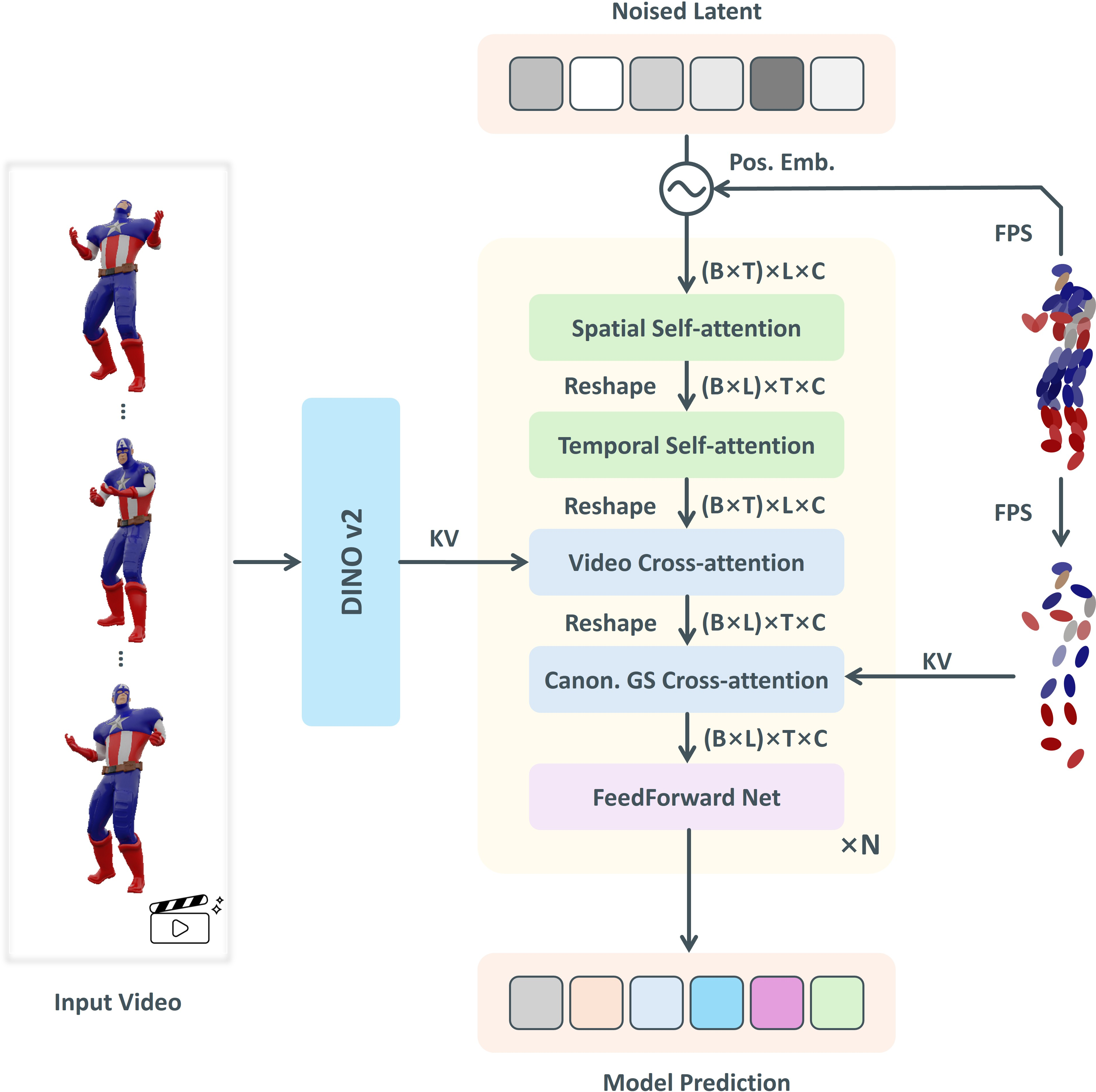
Figure 2: Architecture of Gaussian Variation Field diffusion model. The diffusion transformer denoises latent codes conditioned on video and canonical GS.
The model is trained to predict the velocity in the diffusion process, with a loss that combines image-level reconstruction, mesh-guided displacement alignment, and KL divergence regularization.
Inference Pipeline
At inference, the canonical GS is generated for the first video frame using a pretrained 3D diffusion model. Visual features are extracted from the input video, and the diffusion model generates latent codes for the Gaussian Variation Fields, which are decoded to produce the animated 4DGS sequence. The pipeline is efficient, requiring only 4.5 seconds per sequence on a single A100 GPU.
Experimental Results
Quantitative and Qualitative Evaluation
The method is evaluated on Objaverse-V1/XL, with a test set of 100 objects and multiple metrics (PSNR, LPIPS, SSIM, CLIP, FVD). The proposed approach outperforms prior state-of-the-art methods, including both optimization-based and feedforward baselines, across all metrics. Notably, it achieves a PSNR of 18.47, LPIPS of 0.114, SSIM of 0.901, CLIP of 0.935, and FVD of 476.83, with a generation time of 4.5 seconds—substantially faster than optimization-based methods and only marginally slower than the fastest feedforward baseline.
Qualitative comparisons show that the method produces sharper textures, more accurate geometry, and superior temporal coherence compared to SDS-based and multiview-optimization approaches, which often suffer from spatial-temporal inconsistency and 3D misalignment.
Ablation Studies
Ablations demonstrate the importance of mesh-guided loss, motion-aware query vectors, and inclusion of color/opacity variations in the VAE. Removing positional embeddings from the diffusion model leads to a significant drop in performance, confirming their necessity for high-quality generation.
Applications and Generalization
The model generalizes well to in-the-wild video inputs, despite being trained solely on synthetic data. It can also animate existing 3D models according to the motion in a conditional video, enabling practical workflows where users generate 2D animations (e.g., with video diffusion models) and transfer them to 3D assets.
Implementation Considerations
- Architecture: The VAE and diffusion models are transformer-based, with cross-attention and temporal self-attention layers. The canonical GS autoencoder is based on a structured latent representation with sparse 3D transformers.
- Training: The VAE is trained in two stages (static GS finetuning, then joint 4D training), with AdamW optimizer and batch size 32. The diffusion model uses a cosine noise schedule and is trained for 1.3M iterations.
- Resource Requirements: Training requires multiple high-memory GPUs (V100/A100). Inference is efficient and suitable for deployment on a single high-end GPU.
- Scalability: The compact latent space (512D) enables tractable diffusion modeling for long sequences and high-resolution content.
- Limitations: The two-stage pipeline can suffer if the canonical GS is misaligned with the input video, as the diffusion model cannot fully compensate for large discrepancies. Future work may explore end-to-end 4D diffusion or joint optimization of canonical and dynamic components.
Implications and Future Directions
This work demonstrates that decomposing 4D generation into canonical 3DGS and dynamic variation fields, with efficient latent-space diffusion, enables scalable, high-fidelity video-to-4D synthesis. The approach bridges the gap between static 3D asset generation and dynamic 4D content creation, with strong generalization to real-world data. Future research may focus on end-to-end 4D generative models, improved alignment between video and canonical GS, and broader applications in animation, AR/VR, and robotics.
Conclusion
The proposed framework for video-to-4D synthesis leverages a Direct 4DMesh-to-GS Variation Field VAE and a temporally-aware diffusion transformer to achieve efficient, high-quality, and temporally coherent 4D content generation from monocular video. The method outperforms existing approaches in both fidelity and efficiency, generalizes to in-the-wild data, and enables practical animation of 3D assets from video. The decomposition into canonical and dynamic components, combined with compact latent-space modeling, represents a significant advance in scalable 4D generative modeling.