- The paper introduces a tuning-free framework that generates 4D scenes from a single image with strong spatial-temporal consistency.
- It employs adaptive guidance and modulation techniques to refine a 4D representation into coherent multi-view video outputs.
- Quantitative assessments and user studies validate its superior performance and real-time efficiency compared to state-of-the-art methods.
Free4D: Tuning-free 4D Scene Generation with Spatial-Temporal Consistency
The paper "Free4D: Tuning-free 4D Scene Generation with Spatial-Temporal Consistency" presents Free4D, a framework for generating 4D scenes from a single image without tuning, focusing on spatial-temporal consistency.
Framework Overview
Free4D introduces a framework to generate dynamic 4D scenes from a single image input, aiming to provide realistic 3D environments for applications such as video games and augmented reality. The proposed solution addresses limitations in existing methods, which typically rely on object-level focus or require extensive multi-view datasets for training. Free4D instead leverages pre-trained models to distill a consistent 4D scene representation efficiently.
Free4D begins by animating the input image using image-to-video diffusion models, followed by the initialization of a 4D geometric structure. This is refined into a spatial-temporally consistent multi-view video using novel strategies to maintain coherence over time.
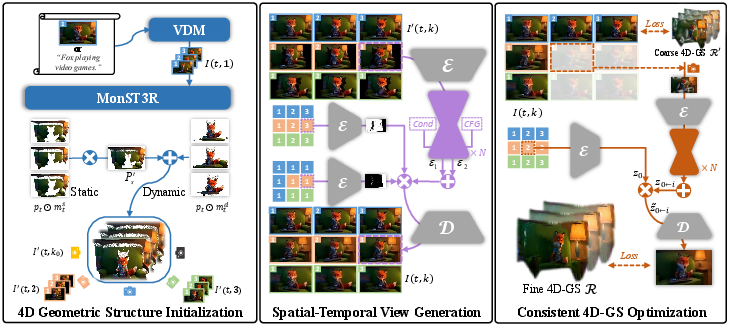
Figure 1: Overview of Free4D. Given an input image or text prompt, a dynamic video is generated, forming the basis for the 4D scene.
Spatial-Temporal Consistency Techniques
- Adaptive Guidance Mechanism: This mechanism uses a point-guided denoising strategy for preserving spatial consistency and a latent replacement strategy for enhancing temporal coherence.
- 4D Representation Refinement: The framework introduces a modulation-based refinement to align inconsistencies while extracting meaningful information from generated data.
The above techniques ensure that Free4D is capable of generating real-time, controllable 4D representations, which is a significant improvement over existing single-image-based approaches.
Experimental Results
Quantitative assessments and user studies demonstrate Free4D's effectiveness in generating highly aesthetic and dynamic video outputs with superior temporal consistency compared to contemporaneous methods. The paper presents multiple figures comparing Free4D's outputs against various benchmarks and ablation studies highlighting the impact of its novel strategies:
Implementation and Application Considerations
- Computational Efficiency: Free4D efficiently manages resource use by avoiding the need for large-scale dataset fine-tuning, highlighting its adaptability in real-world scenarios.
- Real-World Applications: By enabling high-fidelity scene construction from minimal input data, Free4D has potential applications in virtual production, live simulations, and adaptive environments in XR applications.
Conclusion
Free4D demonstrates how innovative tuning-free strategies can effectively generate 4D scene representations with high spatial-temporal consistency. By abstracting the complexities of dynamic scene generation into an efficient framework, Free4D opens pathways for practical applications and future exploration in integrating AI-driven scene generation technologies. Anticipated future work includes enhancing crispness and diversity in low-light conditions, addressing limitations such as handling large viewpoint changes, and improving scene fidelity in less-defined input scenarios.


