Running VLAs at Real-time Speed
Abstract: In this paper, we show how to run pi0-level multi-view VLA at 30Hz frame rate and at most 480Hz trajectory frequency using a single consumer GPU. This enables dynamic and real-time tasks that were previously believed to be unattainable by large VLA models. To achieve it, we introduce a bag of strategies to eliminate the overheads in model inference. The real-world experiment shows that the pi0 policy with our strategy achieves a 100% success rate in grasping a falling pen task. Based on the results, we further propose a full streaming inference framework for real-time robot control of VLA. Code is available at https://github.com/Dexmal/realtime-vla.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper shows how to make a big robot brain that sees, understands, and acts (called a Vision-Language-Action model, or VLA) react fast enough for real life. The team gets a popular VLA (“pi-zero”) to run at real-time video speed (30 frames per second) on a single gaming GPU (an RTX 4090). They prove it by making a robot catch a falling pen with a 100% success rate and explain a new way to run these models so robots can also react at very high control speeds (up to 480 times per second).
What questions did the paper ask?
- Can we run a large VLA model fast enough to process every camera frame (about 30 per second) without dropping any?
- Can we also make the robot’s low-level actions (like squeezing a gripper or changing force) update much faster (hundreds of times per second)?
- What engineering tricks are needed to cut the delays in the system?
- How close can we get to the “best possible” speed on this hardware?
- Can we redesign how VLAs run so vision, action, and even text reasoning work smoothly together in one continuous, real-time loop?
How did they do it? (Methods explained simply)
Think of the model like a very big team of workers doing math steps. The goal is to remove waiting, cut repeated work, and arrange tasks so everyone works at once.
1) Make the computer stop waiting on the CPU
They used something called “CUDA graphs,” which is like recording all the instructions once and then replaying them directly on the GPU. This cuts out a lot of slow “manager” overhead from the CPU (like someone shouting steps one by one). Result: big speedup.
2) Cut out repeated or separate steps
They combined math steps that can be merged without changing the result (like mixing ingredients before cooking instead of doing it in tiny bowls). Examples:
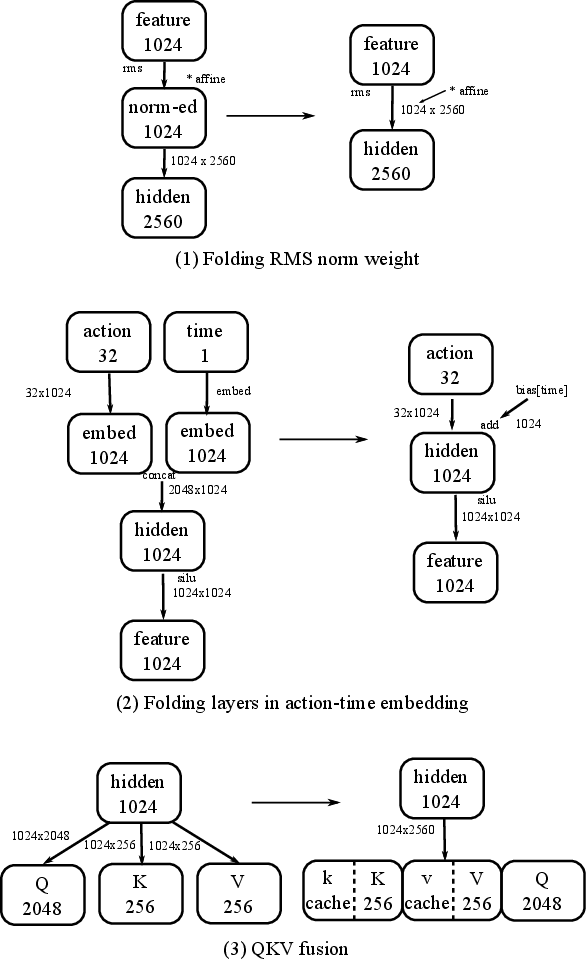
- Fusing normalization with the next layer (merge two steps into one).
- Precomputing tiny parts that never change (so you don’t redo them every time).
- Combining three projections (Q, K, V in attention) into one larger step and then slicing the result. All of this reduces the number of times the GPU has to start a new task.
3) Make the heavy math run faster on the GPU
Most of the time is spent in giant matrix multiplications (think: very big times tables), often called GEMMs. They:
- Tuned how data is chopped into tiles so the GPU cores stay busy.
- Fused layers in the feed-forward network so results are written to memory fewer times.
- Tweaked tricky cases where work didn’t split evenly across GPU cores.
- Fused small operations (adding bias, activations, residuals) into the big math to avoid extra passes.
4) Reduce other delays outside the model
- Resizing camera images efficiently.
- Using “pinned memory” and zero-copy data paths so moving data between CPU and GPU is fast.
- Keeping buffers static so the system avoids hiccups.
5) Estimate the best-possible speed (lower bound)
They used a “roofline” model: the fastest time is limited by either math speed or memory speed, whichever is the bottleneck. They also measured how much time is lost when the GPU has to wait between small tasks (“synchronization”). This shows they are within about 30% of the hardware’s practical limit—very close to optimal.
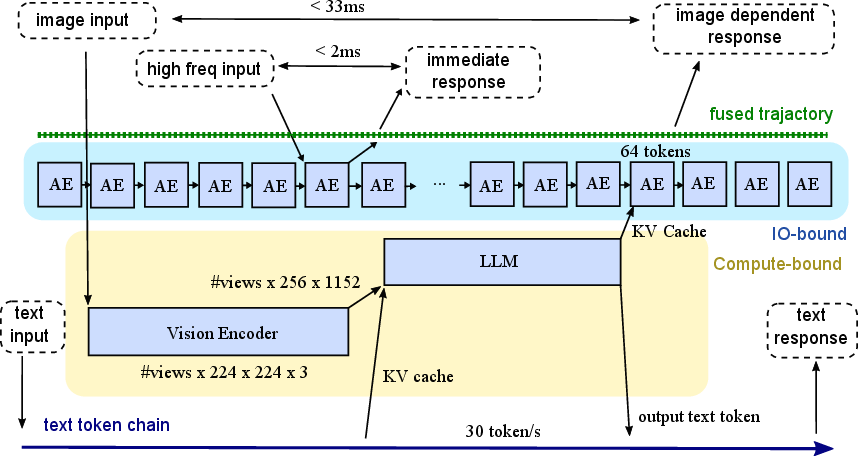
6) A new way to run everything continuously: Full Streaming Inference
They noticed two parts of the model behave differently:
- Vision-Language part (VLM): heavy math, runs best at camera speed (about 30 Hz).
- Action Expert (AE): more memory/bandwidth-limited, but can run very often at small steps.
By overlapping them on the GPU (like two teams working side-by-side), they can:
- Process vision at 30 frames/s, and
- Update actions up to 480 times/s,
- And even “piggyback” some slow text reasoning alongside the vision passes.
This creates three loops running together:
- A fast force/touch loop around 480 Hz (for quick reflexes).
- A vision loop at 30 Hz (for seeing the scene in real time).
- A slow text loop (<1 Hz) for planning/reasoning or talking to humans.
What did they find and why does it matter?
Here are the main results in plain terms:
- They cut single-step model time down to about 27.3 ms for two camera views (faster than 33 ms), so the model can handle every frame in a 30 FPS video without dropping frames.
- They reached about 20.0 ms (1 view), 27.3 ms (2 views), 36.8 ms (3 views) on one RTX 4090, beating a popular reference implementation.
- By overlapping the vision and action parts, they can support up to 30 vision cycles and 480 action updates per second on the same GPU.
- Real-world test: a robot gripper catching a falling pen had a 100% success rate, with end-to-end reaction time under 200 ms—about as fast as an average human reaction in this setup.
Why it matters:
- Real-time speed means the robot won’t miss critical visual moments (no dropped frames), reducing delays.
- High-frequency action updates mean smoother and safer control—important for tasks like grasping moving objects or reacting to touch.
- Doing this on a single consumer GPU makes it more accessible and affordable.
Real-world demo in simple terms
They built a rig with two grippers and a marker pen. The top gripper drops the pen; the bottom one must close at exactly the right time to catch it. A 30 FPS camera watches. The model learns from examples when to close. Thanks to the speedups, the system reacts fast enough every time, catching the pen in 10 out of 10 tests (and designed to generalize). This shows the system isn’t just fast in theory—it works in practice.
What could this change in the future?
If big VLAs can run at real-time speeds:
- Robots can handle quick, dynamic tasks (like catching, scooping, avoiding, or stabilizing) with fewer delays.
- We can combine vision, touch/force, and even text-based reasoning in one continuous system.
- With faster GPUs or better quantization (lower-precision math), we might reach 60–120 FPS vision, handle more cameras, and use even larger models (like 7B parameters) while staying real-time.
- Adding force or tactile sensors can make the ultra-fast 480 Hz loop even more useful, for precise, safe contact with the world.
Key takeaways
- The authors show that large VLA models can run at true real-time speed on a single consumer GPU by carefully removing overhead, fusing steps, and overlapping work.
- They introduce “Full Streaming Inference,” which keeps vision, action, and even text reasoning running together smoothly at different speeds.
- Their robot catching a falling pen proves the approach works in the real world.
- This opens the door to “reflexive” intelligent robots—fast, capable, and practical—ready for more complex, time-critical tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed to guide future research and engineering work.
- Generalizability beyond a single toy task: The real-world validation is limited to a “falling-pen” binary action with a single actuator; it remains unknown how the proposed optimizations perform on multi-DoF, contact-rich, or multi-step manipulation tasks with longer horizons and richer action spaces.
- Accuracy–latency trade-offs: The paper reports speed gains but does not quantify any impact of kernel fusions, graph simplifications, and concurrency on policy accuracy, stability, or output distribution compared to baseline inference.
- Robustness under real-world jitter: End-to-end latency variability (jitter) and its impact on control performance is not characterized under realistic conditions (camera timing drift, OS scheduling, concurrent processes, GPU contention).
- End-to-end timing breakdown: The reported inference time excludes camera ISP/USB delays and actuator command latency; a full closed-loop measurement (sensor-to-actuator) under load is missing.
- Dynamic-shape and dynamic-branch support: CUDA graph capture assumes fixed shapes and static execution paths; how to maintain performance when prompts, number of views, chunk lengths, or token counts vary at runtime remains unresolved.
- Portability across hardware: The approach is validated on a single RTX 4090; no evidence is provided for portability, performance, or tuning requirements across other GPUs (RTX 40/50 series, A100/H100, Jetson-class devices) or different drivers.
- Maintainability and correctness of custom kernels: There is no formal equivalence checking or test suite demonstrating numerical accuracy and stability of fused Triton kernels (e.g., RMSNorm folding, gated FFN fusion, QKV fusion with RoPE) across edge cases and model variants.
- Attention optimization choices: Softmax/attention remains “torch” defaults; the paper does not evaluate integrating FlashAttention/FlashDecoding or alternative attention kernels in the VLM/AE and their effect on latency and accuracy.
- Memory footprint and fragmentation: Practical VRAM usage, KV-cache memory growth with longer contexts, and fragmentation under streaming workloads are not analyzed; strategies like KV-cache compression (e.g., PQCache) are not evaluated.
- Quantization pathway: The paper mentions potential INT8 benefits but provides no pipeline for safe quantization of VLM/AE (including mixed-precision accumulation, calibration, and error bounds) under real-time constraints.
- Multi-view scaling limits: Performance and accuracy scaling with more cameras (>3 views), variable resolutions, and dynamic camera selection/fusion (active view arbitration) are not explored or benchmarked.
- Concurrency scheduling and priorities: Overlapped VLM+AE streams are demonstrated proof-of-concept, but the scheduling policy (stream priorities, preemption, resource contention, fairness) and effects on determinism are not specified.
- Synchronization overhead mitigation: The “software barrier” approach is only used as an estimator; its practical viability, safety (deadlocks, livelocks), and performance impact when integrated into real kernels remains untested.
- Full Streaming Inference implementation details: The proposed framework (persistent megakernel, trajectory buffers, fusion rules, token-windowing, commitment semantics) is only conceptual; concrete algorithms, APIs, and correctness criteria are absent.
- AE redesign for high-frequency control: The AE’s “gradual” generation (RTC-like decoding) and training procedure to ingest high-frequency sensor streams (force, current, tactile) are not implemented or validated; data requirements and loss functions remain unspecified.
- Fusion/update rules for 480 Hz trajectory buffer: The policy for reconciling overlapping AE updates, conflict resolution, and consistency guarantees in the trajectory buffer are not described or evaluated.
- Sensor synchronization and time alignment: Methods to time-align multi-rate signals (cameras at 30 Hz, sensors at kHz, AE at 480 Hz) and compensate for delays (ISP/USB, controller) are not specified; the required timestamping precision and clock sync are unknown.
- Safety and failure handling: There is no discussion of safety-critical behavior (e.g., emergency stop logic, action bounding, watchdogs), recovery from dropped frames, or out-of-distribution sensor spikes in the proposed high-frequency control loop.
- Long-duration reliability: Sustained performance over hours (thermal throttling, clock drift, memory leaks, kernel failures) and warm-up effects are noted but not systematically characterized or mitigated.
- Impact on learning/training: How architectural changes (fused norms, QKV fusion, AE gating fusion) affect training compatibility, checkpoint portability (openpi), and fine-tuning stability is not addressed.
- Text stream piggybacking feasibility: The idea of piggybacking autoregressive text decoding onto visual encoding (30 tokens/s) is unimplemented; its correctness (weight reuse ordering), memory scheduling, and effect on visual throughput/accuracy require validation.
- Benchmarking methodology: A standardized, reproducible benchmarking harness (with seeds, datasets, prompts, view counts, chunk lengths, and reporting of confidence intervals) is missing; comparisons with vendor frameworks (TensorRT, CUTLASS) are limited.
- Applicability to larger models: Scaling to 7B+ parameters is proposed but not empirically studied; bandwidth vs. compute constraints, kernel tiling re-optimization, and AE bandwidth bottlenecks at that scale are open questions.
- Generalization with prompts and language: Experiments use empty prompts and short chunk length (63); performance with complex language conditioning, longer contexts, and multi-turn instructions in real-time settings remains unexplored.
- Integration with real robot stacks: Concrete interfaces to motor controllers (e.g., CAN, EtherCAT), deterministic scheduling on embedded RTOS, and deployment on mobile robots (power, thermal, battery limits) are not covered.
- Failure case analysis: No ablations or error analysis showing when and why the optimized pipeline fails (e.g., extreme motion, occlusion, lighting changes, sensor noise) and how failures differ from baseline pipelines.
- Legal and safety compliance: The paper does not address compliance with industrial safety standards for high-frequency control loops or verification/validation practices required for deployment.
- Open-source completeness: While code is provided, it is unclear whether all fused kernels, tuning scripts, and test harnesses are included with documentation sufficient for replication and extension.
Practical Applications
Immediate Applications
The following applications can leverage the paper’s methods and findings today, using the released code and described engineering strategies.
- Bold real-time dynamic manipulation (catching/intercepting moving objects)
- Description: Run pi_0-level VLA at 30 Hz with <200 ms end-to-end reaction time to catch falling items, intercept moving parts, or time-critical manipulations (demonstrated 100% success in catching a falling pen).
- Sectors: robotics; manufacturing; logistics; consumer robotics.
- Tools/products/workflows: ROS 2 node for real-time VLA control; Dexmal’s realtime-vla repo; workflow with CUDA graphs, Triton-tuned kernels, QKV+RoPE fusion, zero-copy camera ingestion; trajectory buffer with dense nodes for smooth actuation.
- Assumptions/dependencies: RTX 4090-class GPU; stable shapes/no dynamic branches (CUDA graph); low-latency cameras (avoid >100 ms ISP/USB delays); BF16 precision; pi_0-level model and training data for the task.
- Bold conveyor belt pick-and-place on moving targets
- Description: Process every frame at 30 FPS to act on moving parts without dropping frames and without increasing latency due to missed detections; enables “pick while moving” rather than stop-and-go.
- Sectors: manufacturing; logistics; retail automation.
- Tools/products/workflows: multi-view camera setup (2–3 views) with VLA encoder; fused resizing and pinned memory; overlapped VLM+AE execution to densify trajectories; integration with industrial robot controllers.
- Assumptions/dependencies: controlled lighting and calibrated multi-view setup; consistent object appearances and training data; camera latencies under control; safety interlocks for human-in-the-loop environments.
- Bold collaboration safety reflexes (<200 ms reaction)
- Description: Use the VLA’s low-latency perception-action pipeline to trigger quick avoidance, pause, or retract when human limbs, clothing, or hazards enter a workspace.
- Sectors: robotics; workplace safety; warehousing.
- Tools/products/workflows: continuous 30 Hz image processing; simple AE-driven reflex policies (e.g., retract-to-safe); policy hooks to safety PLCs; latency budget monitoring.
- Assumptions/dependencies: robust hazard detection prompts/data; formal safety validation; reliable time-stamping and latency accounting across camera, GPU, robot controller.
- Bold real-time VLA inference engine integration for existing robots
- Description: Drop-in acceleration of pi_0-level policies via CUDA graphs and kernel fusion to meet strict reaction time budgets in current robotic systems without hardware overhauls.
- Sectors: software; robotics; system integration.
- Tools/products/workflows: packaged inference accelerator (Triton kernels; fused scalar ops; partial split-k GEMMs; pinned memory); ROS 2/ROS 1 plugins; profiling/roofline tools; synchronization overhead measurement harnesses.
- Assumptions/dependencies: fixed model architecture; inference shapes known ahead of time; GPU warming and power/clock stability; careful scheduling and buffer pinning.
- Bold academic teaching and benchmarking kits for time-critical control
- Description: Use the open-source pipeline to teach GPU inference optimization (CUDA graphs, Triton), roofline analysis, synchronization costs, and real-time robotics experiments.
- Sectors: academia; education.
- Tools/products/workflows: course labs; reproducible falling-object benchmark; roofline calculator and sync-overhead harness; side-by-side “naive torch vs. optimized” demos.
- Assumptions/dependencies: access to consumer GPU; simple robot or actuator; low-latency camera; curated training episodes.
- Bold cost-optimized multi-view perception on a single GPU
- Description: Run 2–3 camera views through VLA at 30 Hz on one RTX 4090 to cut hardware costs for multi-view setups while maintaining responsiveness.
- Sectors: computer vision; robotics; retail; inspection.
- Tools/products/workflows: tuned image resizing (custom code, ISP output sizes close to 224×224), zero-copy ingestion, fused encoder kernels; multi-view calibration pipeline.
- Assumptions/dependencies: camera drivers support desired resolutions; careful memory layouts; limited prompt length (empty or short) to preserve latency; stable KV-cache handling.
- Bold smoother control via densified AE trajectory nodes
- Description: Exploit overlapped VLM+AE streaming to produce denser trajectory nodes (up to hundreds of AE steps per second) for smoother actuation without full high-frequency sensor loops.
- Sectors: robotics; industrial automation; drones.
- Tools/products/workflows: concurrent CUDA streams for VLM and AE; circular trajectory buffers with overwrite rules; controller-side interpolation.
- Assumptions/dependencies: AE steps reuse recent KV cache; concurrency-safe buffer management; controller supports high-rate trajectory ingestion.
Long-Term Applications
These depend on further research, scaling, or engineering to mature beyond the proof-of-concept demonstrated.
- Bold Full Streaming Inference tri-loop controllers (480 Hz force/tactile + 30 Hz vision + sub-1 Hz text)
- Description: Implement the proposed architecture with a high-frequency AE reflex loop (e.g., force/tactile/motor-current input at ≥480 Hz), a 30 Hz vision loop, and a piggybacked text loop (~30 tokens/s) for reasoning/planning.
- Sectors: robotics; healthcare (surgical assist); precision manufacturing; HRI.
- Tools/products/workflows: persistent mega-kernel scheduler; streaming sensor injection into AE; gradual/auto-regressive action decoding (RTC-like); asynchronous commit of trajectory nodes; textual CoT integrated with frame encoding.
- Assumptions/dependencies: real-time sensor stacks (force/tactile/current) with microsecond latencies; rewritten AE to support gradual generation; robust fusion/update rules; strong safety envelopes and verification.
- Bold high-speed vision loops at 60–120 FPS
- Description: Double or quadruple visual loop frequencies using int8/FP8 quantization, adaptive multi-view tokenization, and next-gen GPUs (e.g., RTX 5090).
- Sectors: robotics; sports automation; AR/VR devices; autonomous systems.
- Tools/products/workflows: low-bit VLA runtimes; view-adaptive encoders; quantization-aware training; camera pipelines tuned for ultra-low latency.
- Assumptions/dependencies: acceptable accuracy under low-bit quantization; robust token-reduction without losing critical context; sufficient GPU bandwidth/compute.
- Bold 7B+ real-time VLAs for richer generalization
- Description: Scale models beyond 3B while retaining real-time inference (leveraging higher bandwidth GPUs and further kernel superoptimization) to improve generalization in complex, cluttered, or deformable-object tasks.
- Sectors: robotics; research; complex manipulation; service robots.
- Tools/products/workflows: advanced kernel libraries (fused gated layers, multi-level superoptimizers like Mirage/Neptune); memory planners; cross-stream schedules.
- Assumptions/dependencies: enough HBM bandwidth (e.g., 1.79 TB/s on RTX 5090); stable inference shapes; greater training data breadth; energy/thermal budgets.
- Bold embedded and edge deployments (Jetson-class, accelerators)
- Description: Port and tailor the real-time VLA pipeline to edge accelerators for mobile platforms (AMRs, drones, prosthetics), balancing power and latency.
- Sectors: robotics; wearables; UAVs; IoT.
- Tools/products/workflows: operator fusion targeting edge hardware; mixed-precision policies; hardware-aware scheduling; lightweight multi-view ingestion.
- Assumptions/dependencies: lower compute/bandwidth; stricter power envelopes; possibly reduced model sizes or aggressive quantization; new camera/sensor integration.
- Bold multi-sensory AE with tactile/visual-tactile fusion
- Description: Integrate tactile arrays and force sensors directly into AE for high-frequency action chunking and reflexes (grasp stabilization, slip detection, deformable manipulation).
- Sectors: robotics; food handling; surgical assist; delicate assembly.
- Tools/products/workflows: tactile drivers with microsecond latency; sensor-to-token encoders; learned fusion rules; policy training on high-frequency demonstrations.
- Assumptions/dependencies: large-scale, high-frequency data collection; safe and interpretable reflex behaviors; robust sim-to-real transfer.
- Bold text-augmented real-time assistants
- Description: Use the ~30 tokens/s piggybacked textual stream for natural-language guidance, step-by-step reasoning, and continuous human interaction alongside real-time control.
- Sectors: service robots; education; maintenance; telepresence.
- Tools/products/workflows: multimodal prompts; sub-1 Hz task updates; speech-to-text front-ends; on-the-fly CoT integrated with action generation.
- Assumptions/dependencies: reliable alignment between text reasoning and control; guardrails against unsafe textual instructions; latency-aware UX design.
- Bold standards and certification for latency-aware HRI
- Description: Establish metrics and tests (frame-drop rates, end-to-end reaction time, trajectory commit latency) for certifying time-critical robot behaviors.
- Sectors: policy; safety; procurement; compliance (e.g., ISO/ANSI).
- Tools/products/workflows: standardized reaction-time benchmarks; audit logs and latency budgets; procurement checklists; reporting templates.
- Assumptions/dependencies: stakeholder consensus; mapping to existing standards; transparent measurement toolchains; privacy and data-handling compliance.
- Bold data and evaluation pipelines for dynamic, time-critical tasks
- Description: Curate large-scale datasets of dynamic scenes (moving targets, handovers, slips) with precise timing labels and sensor streams; create new benchmarks beyond static manipulation.
- Sectors: academia; industry R&D.
- Tools/products/workflows: synchronized multi-sensor capture (video, force, tactile); timing ground truth; open evaluation suites; real-time simulators.
- Assumptions/dependencies: hardware for synchronization; standardized annotation; community adoption; coverage of edge cases (lighting, occlusions, multi-agent).
Glossary
- Action Expert (AE): The action-generation subnetwork in a VLA, specialized for decoding actions from multimodal context. "AE is modeled through flow matching~\cite{lipman2022flow} to produce the prediction of action chunking."
- Ahead-Of-Time (AOT) compilation: Compiling computations before execution to reduce runtime overhead. "There are several Ahead-Of-Time (AOT) or Just-In-Time (JIT) compilation techniques available."
- Auto-regressive decoding: Sequential generation where each output depends on previously generated outputs. "as if we are doing auto-regressive decoding."
- BF16 (bfloat16): A 16-bit floating-point format used to accelerate tensor-core compute with acceptable precision. "For one BF16 GEMM operation of dimension , the lower-bound is as follows:"
- CUDA graph: A CUDA feature that records and replays kernel launch sequences to eliminate CPU launch overhead. "we find the simplest and most effective way is to use the CUDA graph mechanism."
- CUDA stream: An ordered sequence of CUDA operations that can run concurrently across multiple streams. "If we create two CUDA streams and push the AE kernels in parallel to the VLM using older KV cache"
- cuBLAS: NVIDIA’s GPU-accelerated BLAS library providing high-performance matrix operations. "The default pytorch implementation of matmul goes to cuBLAS, which dispatches to compiled cutlass kernels according to the matrix dimensions."
- CUTLASS: NVIDIA’s templated CUDA primitives for implementing high-performance GEMM and related kernels. "The default pytorch implementation of matmul goes to cuBLAS, which dispatches to compiled cutlass kernels according to the matrix dimensions."
- FlashAttention: An IO-aware attention kernel that reduces memory traffic via tiling and operator fusion. "FlashAttention~\cite{dao2022flashattention} uses tiling to reduce the number of memory I/O between HBM and SRAM and fuses softmax with matmul through a repair computation."
- FlashDecoding: An attention strategy for long-context inference that partitions computation to reduce KV movement and speed decoding. "FlashDecoding~\cite{dao2023flash} proposes a long-context inference strategy that partitions attention into two reduction kernels, reducing KV memory movement and improving auto-regressive decoding efficiency."
- Flow matching: A generative modeling technique that learns continuous flows to map noise to data. "AE is modeled through flow matching~\cite{lipman2022flow} to produce the prediction of action chunking."
- Full Streaming Inference: A concurrent, continuous execution paradigm that overlaps VLM and AE to achieve multi-rate control loops. "We term this line-of-thought the Full Streaming Inference paradigm, as illustrated in Fig.~\ref{fig:framework}."
- GEMM (General Matrix-Matrix Multiplication): Core dense linear algebra operation at the heart of transformer inference. "There are 24 GEMM-like operations and associated scalar operators in total."
- GELU (Gaussian Error Linear Unit): A smooth activation function commonly used in transformer FFNs. "The feature is multiplied by two different weights and the results are combined as ."
- HBM (High Bandwidth Memory): On-package memory delivering very high throughput, often the bandwidth bottleneck. "calculation of the HBM bandwidth and tensor core cycles."
- Image Signal Processor (ISP): Camera hardware pipeline that performs tasks like demosaicing and resizing before the host receives frames. "we observe that most camera ISP support many different output resolutions."
- Just-In-Time (JIT) compilation: Compiling computations at runtime to optimize dynamically shaped workloads. "There are several Ahead-Of-Time (AOT) or Just-In-Time (JIT) compilation techniques available."
- Kernel-launch overhead: The CPU and driver cost of dispatching many small GPU kernels. "leave significant performance penalties from kernel-launch overhead and repeated global-memory movements."
- KV cache: Stored key/value tensors from prior tokens or frames, reused to accelerate attention. "only the KV caches are passed to the AE"
- Mixture-of-Experts (MoE): An architecture that routes inputs to specialized expert subnetworks to improve capacity/efficiency. "AE is coupled with the VLM backbone through the mixture-of-expert (MoE) architecture~\cite{shazeer2017moe}."
- PaliGemma: A 3B-parameter multimodal VLM combining SigLIP vision encoder and Gemma LLM. "VLM backbone is initialized with PaliGemma~\cite{beyer2024paligemma}"
- Pinned memory: Page-locked host memory enabling faster, asynchronous CPU-GPU transfers. "Copying data back and forth between CPU and GPU requires pinned memory for optimal performance."
- RMS norm (RMSNorm): A normalization technique that scales activations by their root-mean-square, often with fused affine. "The first is to fuse the affine parameters in the RMS norm layer~\cite{zhang2019rms} into the subsequent linear layer."
- RoPE (Rotary Positional Embeddings): Position encoding that rotates query/key vectors to encode relative positions. "We can also fuse RoPE~\cite{su2024rope} operation into the matrix multiplication"
- Roofline model: A performance model bounding runtime by the max of compute and memory limits. "The basic approach is the “roofline” model, which lower bounds the time of a computation by the maximum of doing all memory operations and all compute operations."
- SigLIP: A vision encoder trained with a sigmoid loss for contrastive image-text pretraining. "It is composed of a vision encoder SigLIP~\cite{zhai2023siglip} with 400M parameters"
- SiLU: A smooth activation function also known as Swish, often used in modern networks. "right before SiLU operation~\cite{elfwing2018silu}."
- Split-K (K-dimension splitting): Parallelizing a GEMM by partitioning along the reduction (K) dimension to improve SM utilization. "The second is , which can be partitioned to the 128 SMs using block and split-2 partition in the K dimension."
- Tensor cores: Specialized GPU units for high-throughput mixed-precision matrix math. "calculation of the HBM bandwidth and tensor core cycles."
- Triton: A DSL and compiler for writing high-performance GPU kernels with tile-level control. "We manually tuned the tiling strategies using a Triton implementation"
- Vision-Language-Action (VLA): A model class that maps visual and textual inputs to actions for robotic control. "In this paper, we show how to run -level multi-view VLA at 30Hz frame rate"
- Vision-LLM (VLM): The perception-and-language backbone that encodes images and text into representations. "From the perspective of model architecture, it mainly includes two parts: vision-LLM (VLM) and action expert (AE)."
- Zero-copying: Avoiding extra memory copies by sharing buffers between producer and consumer directly. "Using zero-copying to handle camera frames reduces latency."
Collections
Sign up for free to add this paper to one or more collections.