- The paper presents a MIP-based dataflow optimization framework that systematically addresses pipeline stalls and resource constraints in CIM accelerators.
- It introduces a flexible factorization algorithm to efficiently reduce the search space while coordinating hardware resource utilization and data locality.
- Experimental results demonstrate up to 3.2× energy-delay product reduction, validating MIREDO's effectiveness across diverse DNN workloads and architectures.
MIREDO: MIP-Driven Resource-Efficient Dataflow Optimization for CIM Accelerators
Motivation and Context
The exponential growth of DNN workloads and the proliferation of edge intelligence demand highly efficient and scalable accelerator technologies. Computing-in-Memory (CIM) is recognized for its potential to minimize data movement by leveraging in-situ matrix-vector multiplications within memory arrays, substantially improving system-level energy and performance. Despite prior advancements, a persistent gap remains between peak macro-level theoretical efficiency and realized system-level performance, primarily due to suboptimal dataflow strategies and the complex interplay of architectural constraints. Existing approaches resort to empirical, heuristic, or rule-based methods, insufficient to exhaustively explore the vast design space of dataflows in multi-core CIM systems. The MIREDO framework directly addresses these limitations by systematizing dataflow optimization as a Mixed-Integer Programming (MIP) task, tightly coupling hardware resource constraints, data movement, pipeline stall phenomena, and workload characteristics.
Hierarchical Abstraction and Bottleneck Analysis
MIREDO's foundation lies in a detailed hierarchical abstraction of typical multi-core SRAM-based CIM architectures. The top-level structure consists of global buffers, a sophisticated distribution network, arrays of CIM cores, and a SIMD unit for post-processing operations.
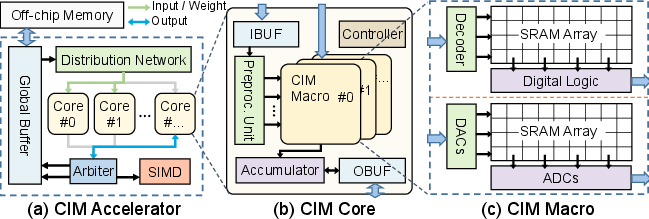
Figure 1: Hierarchical abstraction of the oriented CIM accelerator, highlighting data movement and parallelism at each architectural layer.
At the macro level, unique bottlenecks emerge due to the conflation of compute and memory modes within CIM macros, necessitating exclusive peripheral circuit usage. This architectural idiosyncrasy manifests as pipeline stalls, notably during mode switching and frequent weight reload requirements.
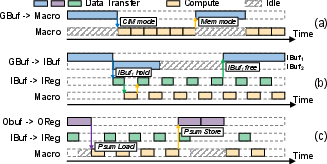
Figure 2: Representative data-transfer timelines illustrating mode-switch, throughput mismatch, and operand-synchronization stalls in CIM.
Data transfer analysis in MIREDO reveals limitations of prevailing latency models, which often adopt oversimplified assumptions (e.g., perfect latency-hiding via double-buffering). In reality, throughput mismatches, operand synchronizations, and memory hierarchy resource limitations yield significant underutilization and pipeline inefficiencies at the system level.
MIREDO systematically formulates the dataflow mapping and scheduling problem as a structured MIP. It incorporates a comprehensive set of hardware and workload parameters as constants and encodes mapping decisions as binary and one-hot variables. The MIP incorporates constraints corresponding to:
- Uniqueness of mapping (each tiling factor is mapped exactly once).
- Operand-specific loop blocking across hierarchical memory.
- Legal transfer path definitions, buffer/memory utilization, and data locality.
- Detailed architectural limitations including bus widths, memory capacities, and parallelism axes.
A central innovation is the flexible factorization algorithm, which strategically reduces the combinatorial search space by greedy merging of prime factors, preserving mapping versatility while maintaining tractability.
MIREDO also introduces an analytical, recursively defined latency model that accounts for pipeline stalls induced by buffering strategies, transfer/computation throughput mismatches, and operand synchronization effects—enabling accurate cost estimation in the MIP optimization.
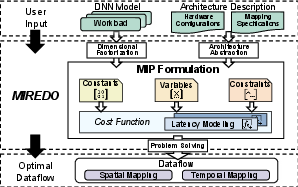
Figure 3: Overview of the proposed MIREDO framework, from model and architecture parsing to MIP-based optimization and final mapping.
The cost function in MIREDO associates the primary objective of system-level latency minimization with a secondary goal of maximizing data locality (i.e., storing operands close to compute macros). Buffering modes are treated as optimization variables—permitting the framework to dynamically explore and select between maximal-capacity, minimal-stall (single buffering) and stall-overlapped (double buffering) modes with corresponding capacity penalties.
The evaluation of the analytical model demonstrates a mean accuracy of 95.5% against cycle-accurate hardware simulation, validating its ability to closely predict complex real-system pipeline behavior.
Experimental Validation and Results
The MIREDO framework is validated on various DNN workloads, including quantized ResNet-18 inference on ImageNet, and diverse hardware setups. Comparisons include a ZigZag-inspired heuristic and a standard Weight-Stationary (WS) mapping (built atop the same MIP formulation for fairness).
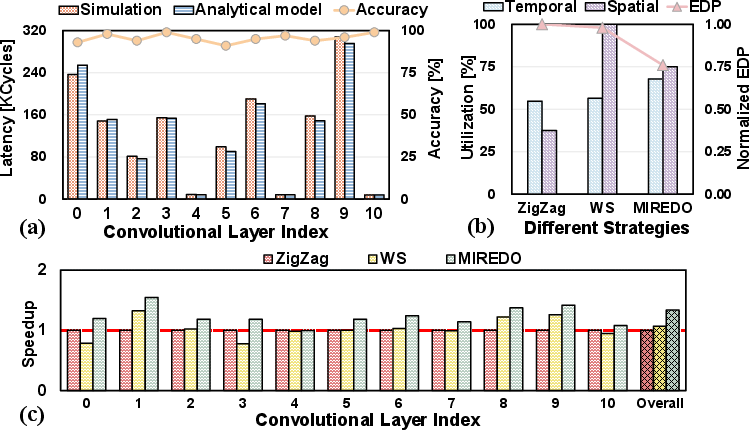
Figure 4: MIREDO performance evaluation—(a) analytical model validation, (b) macro utilization and EDP tradeoff, (c) per-layer and overall speedup relative to baselines.
Key findings include:
- Up to 3.2× Energy-Delay Product (EDP) reduction over the best non-MIREDO baselines.
- MIREDO consistently outperforms WS and heuristic methods, particularly in resource-constrained scenarios and for layers with complex data reuse requirements.
- Substantial improvements emerge from MIREDO's ability to coordinate temporal/spatial mapping, buffer utilization, and operation overlap for diverse DNN layers.
Broader evaluation across configurations demonstrates MIREDO's robustness and adaptability to varying macro arrays, core counts, and buffer sizes.
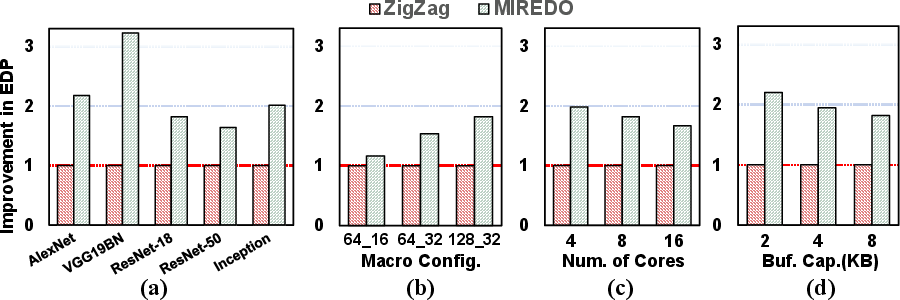
Figure 5: Performance comparison of MIREDO across various DNN models and hardware configurations, showing consistent EDP reduction and efficient resource usage.
Implications, Extensions, and Future Directions
The results indicate that mathematical programming-based approaches, when underpinned by precise hardware abstractions and latency prediction, can close the previously persistent gap between macro-level efficiency and end-to-end system throughput for CIM accelerators. By explicitly capturing architectural and data transfer constraints, the MIREDO methodology provides a basis for scalable, extensible optimization across future generations of CIM architectures—including those with heterogeneous memory hierarchies, variable-precision arithmetic, and non-volatile device integration.
The integration of MIREDO-style dataflow optimization may be extended to dynamic, workload-adaptive runtime schedulers, automated compiler toolchains, and co-design flows where hardware parameters themselves are tunable variables in the global DNN-CIM optimization loop. Further exploration into stochastic or reinforcement learning-enhanced solvers, potentially leveraging MIREDO's MIP core as a subroutine or teacher, is a plausible future direction.
Conclusion
MIREDO represents a rigorous, scalable approach to dataflow optimization for CIM accelerators. Through a comprehensive MIP-based methodology, hierarchical hardware abstraction, and analytical modeling of architectural bottlenecks, MIREDO achieves up to 3.2× EDP improvement across heterogeneous DNN workloads and hardware configurations. The framework's adaptability and extensibility position it as a valuable tool in advancing the efficiency of next-generation in-memory computing systems and edge intelligence platforms.

