- The paper introduces linguistic confidence (LC) by employing hedging language to naturally express uncertainty and proposes a lightweight mapper to convert these expressions into confidence scores.
- The methodology features a novel dataset and evaluation through metrics like ECE and AUROC, demonstrating improved calibration and discriminability compared to traditional approaches.
- Fine-tuning with LoRA further refines LC, underscoring its potential to enhance trust and reliability in human-AI interactions.
Can LLMs Express Uncertainty Like Humans?
Introduction
The paper "Can LLMs Express Uncertainty Like Human?" (2509.24202) explores the critical aspect of expressing uncertainty in LLMs. Given their widespread application in domains such as education, healthcare, and law, the importance of reliable confidence estimation is paramount. The paper addresses the challenges posed by current methods: hidden logits, computational expense of multi-sampling, and the unnatural delivery of numerical uncertainty. It advocates for 'Linguistic Confidence' (LC), where models utilize hedging language, aligning closer with human communication.
Background and Motivation
Existing approaches to LLM uncertainty estimation either require inaccessible internal logits or resort to computationally intensive sampling techniques. Verbalized numerical scoring, although direct, deviates from natural communication. The paper revisits LC as a promising alternative. It introduces a diverse dataset and a lightweight mapping technique for converting hedging language into pragmatic confidence scores—a strategy with minimal computational cost and significant scalability.
The study emphasizes the significance of calibrating machine responses through LC, thereby facilitating enhanced trust and accuracy in human-AI interactions.
Methodology
The research consists of several key contributions:
- Dataset Construction: The authors compile a novel dataset of hedging expressions with human-annotated confidence scores, allowing for robust evaluation of LLM confidence mapping capabilities.

Figure 1: An illustration of the benchmark building process.
- Lightweight Mapper: They propose a near-zero-cost mapper to translate hedging language into confidence scores, bypassing the expensive API costs associated with commercial LLMs.
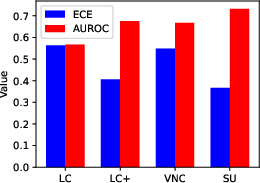
- Comprehensive Evaluation: The study systematically analyzes LC across state-of-the-art LLMs and various QA benchmarks, highlighting both calibration (ECE) and discriminability (AUROC).
- Fine-tuning Framework: An innovative framework is suggested to enhance LC reliability through supervised fine-tuning, further refining LLM's capacity to convey uncertainty naturally.
Results
The empirical results reveal several insights:
Discussion and Implications
The paper underscores the transformative potential of LC in aligning LLM responses with human expectations of uncertainty. It suggests that hedging language not only enhances user trust but also offers a computationally efficient alternative to traditional confidence estimation methods. The research sets the stage for future exploration into more nuanced LC mappings and diversifying applications to multimodal and reasoning contexts.
Ultimately, the findings advocate for increased attention to human-centered approaches in AI system design, with LC serving as a viable path towards more transparent and trustworthy AI interactions.
Conclusion
This study presents strong evidence that LLMs, when guided appropriately, can express uncertainty in ways that resonate with human communication habits. The advancements in datamapping and fine-tuning methodologies bolster the effectiveness of LC, paving the way for more human-aligned AI systems that can be deployed in sensitive and decision-critical applications. Further research is anticipated to expand these findings, enriching the dialogue between AI systems and their human users.