Every Attention Matters: An Efficient Hybrid Architecture for Long-Context Reasoning
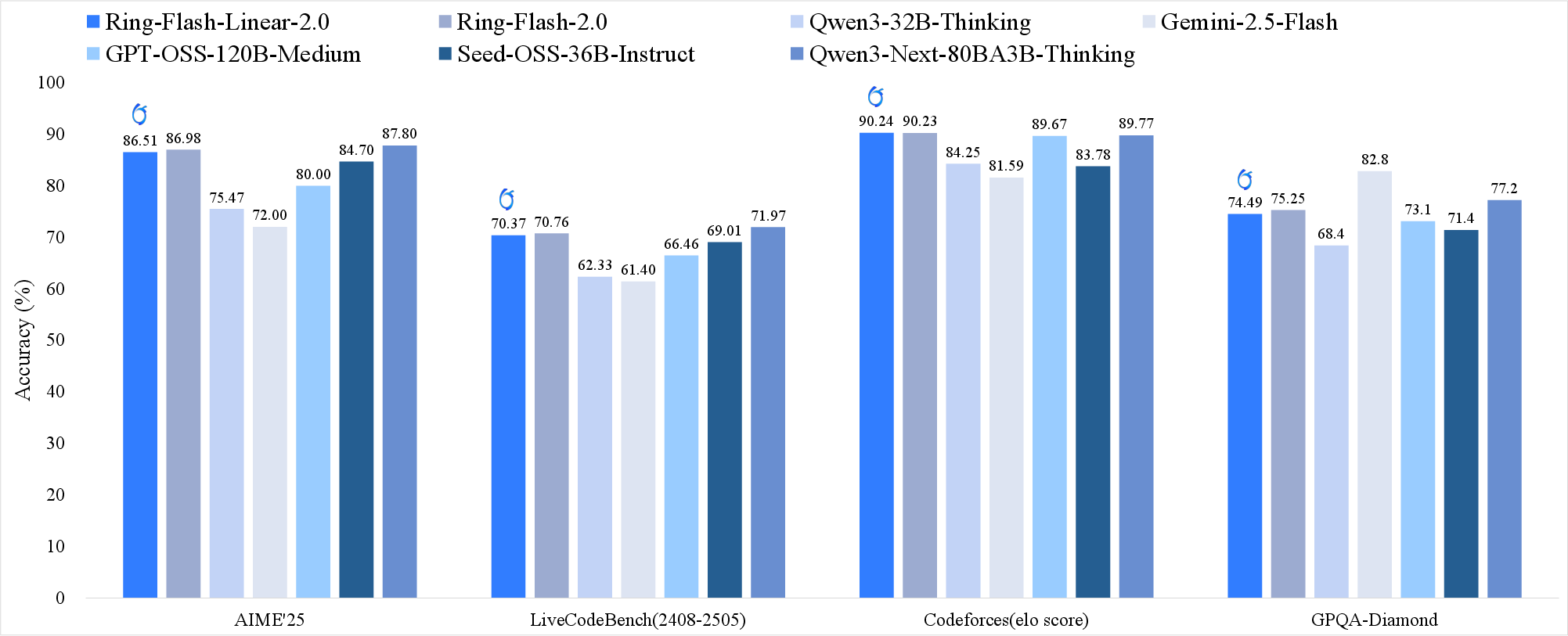
Abstract: In this technical report, we present the Ring-linear model series, specifically including Ring-mini-linear-2.0 and Ring-flash-linear-2.0. Ring-mini-linear-2.0 comprises 16B parameters and 957M activations, while Ring-flash-linear-2.0 contains 104B parameters and 6.1B activations. Both models adopt a hybrid architecture that effectively integrates linear attention and softmax attention, significantly reducing I/O and computational overhead in long-context inference scenarios. Compared to a 32 billion parameter dense model, this series reduces inference cost to 1/10, and compared to the original Ring series, the cost is also reduced by over 50%. Furthermore, through systematic exploration of the ratio between different attention mechanisms in the hybrid architecture, we have identified the currently optimal model structure. Additionally, by leveraging our self-developed high-performance FP8 operator library-linghe, overall training efficiency has been improved by 50%. Benefiting from the high alignment between the training and inference engine operators, the models can undergo long-term, stable, and highly efficient optimization during the reinforcement learning phase, consistently maintaining SOTA performance across multiple challenging complex reasoning benchmarks.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces two new AI LLMs, Ring-mini-linear-2.0 and Ring-flash-linear-2.0, designed to read and reason over very long inputs (like huge documents or long chains of thought) without becoming slow or expensive to run. The key idea is a “hybrid” attention system that mixes two ways of focusing on text: a fast method called linear attention and a powerful method called softmax attention. By choosing the right balance between the two, the models stay smart while becoming much more efficient.
What is the paper trying to achieve?
The researchers set out to:
- Build LLMs that handle very long context windows (up to 128,000 tokens) efficiently.
- Keep strong reasoning performance while cutting the cost of running the models.
- Find the best mix (“ratio”) of linear attention and softmax attention.
- Speed up both training and inference (the process of generating answers).
- Make reinforcement learning (RL) training stable by fixing a hidden problem where the training system and the inference system don’t behave exactly the same.
How did they do it?
The basic idea: attention as “focus”
When an AI reads text, “attention” is how it decides which earlier words matter for the current word it’s writing. Think of attention like scanning your notes: softmax attention carefully compares the current word to all previous words (very thorough, but slow when the text is long). Linear attention keeps a clever running summary, so it doesn’t have to compare everything to everything (much faster when the text is long).
- Softmax attention: great quality, but its cost grows very fast as the text gets longer.
- Linear attention: much cheaper for long texts and uses a fixed-size memory, but on its own can be less accurate for some tasks (like retrieving specific information from far back).
The hybrid design
The models stack several linear attention layers followed by one softmax attention layer, repeating this pattern. This way, most layers are fast, and the softmax layers “refresh” the model’s ability to capture precise relationships.
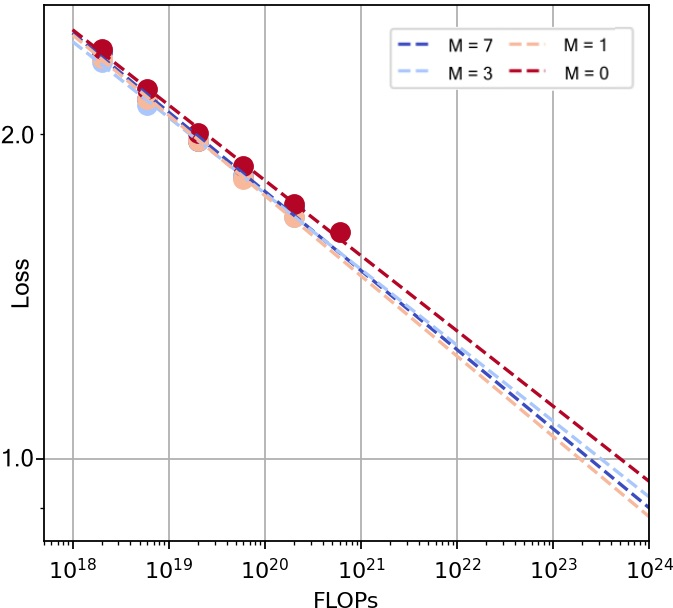
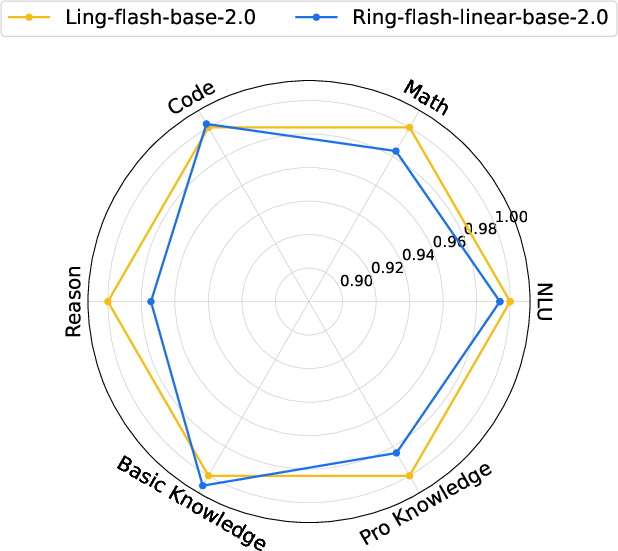
- For the big model (Ring-flash-linear-2.0), they chose 7 linear attention layers followed by 1 softmax attention layer (called M=7).
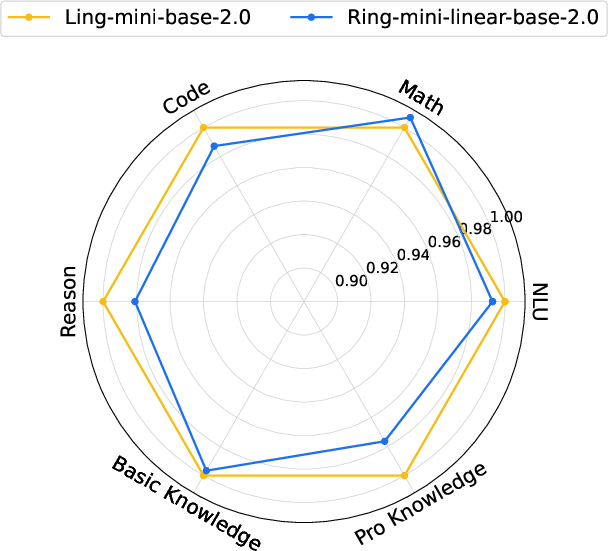
- For the smaller model (Ring-mini-linear-2.0), they chose 4 linear layers followed by 1 softmax layer (M=4).
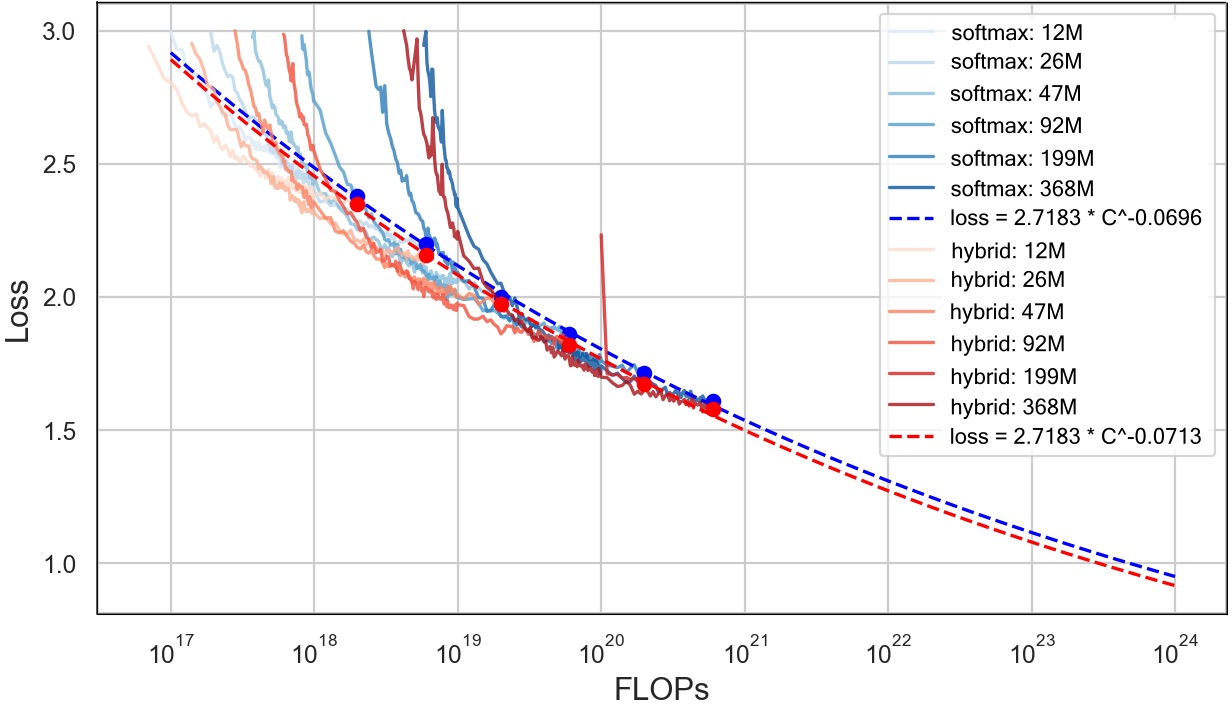
- They picked these ratios by testing “scaling laws” (curves that show how performance improves with more training) and found the hybrid consistently beats pure softmax models for the same compute budget.
Mixture-of-Experts (MoE): using the right specialist
The models use a sparse Mixture-of-Experts design: instead of one big brain doing everything, they have many “expert” sub-networks, and only a few are activated at a time. This saves compute, like asking just the right specialists for each sentence rather than all of them. The paper optimizes this system to keep speed and stability high.
Making everything faster: kernels and low-precision math
They improved the code that runs on GPUs by “fusing” steps together so data doesn’t get moved around unnecessarily. Think of it like combining several small cooking steps into one efficient recipe to save time.
They also use FP8 (a compact number format) for faster math during training and carefully manage when to use higher precision (like FP32) to avoid errors piling up.
Training recipe
They didn’t start from scratch. They:
- Continued pre-training from strong base models to restore general language skills.
- Extended the context window (first 4K, then 32K, then 128K).
- Fine-tuned with supervised data (SFT) for math, coding, science, logic, and general tasks.
- Trained with reinforcement learning (RL) to push reasoning ability higher.
Fixing RL instability: training vs inference mismatch
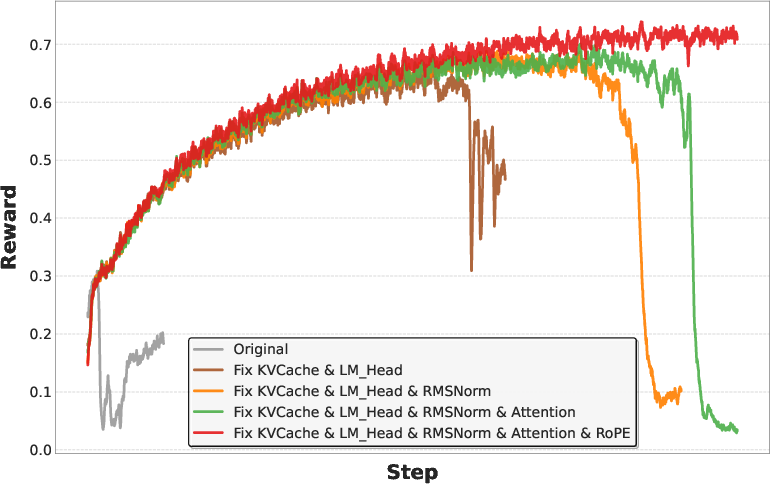
They discovered a key problem: the way the model is run during training and the way it is run to produce answers (inference) can differ slightly in how certain parts are implemented (like attention, normalization, and the final softmax). These small differences can stack up, especially with long outputs and MoE routing, and make RL unstable.
So they aligned the two systems step-by-step:
- Ensured the exact same precision for critical parts (e.g., FP32 for accumulated states and final softmax).
- Used deterministic and consistent operations for MoE routing and attention.
- Verified outputs layer-by-layer until training and inference matched closely.
Once aligned, RL training became stable and more effective.
What did they find, and why does it matter?
- Huge efficiency gains:
- Inference cost drops to about 1/10 compared to a 32B dense model.
- More than 50% cheaper than their earlier Ring series.
- Training efficiency improved by up to 50% using their FP8 operator library (called “linghe”).
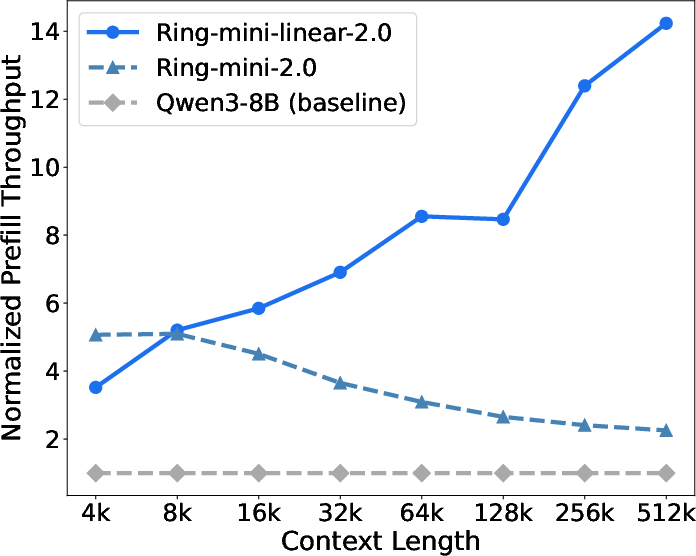
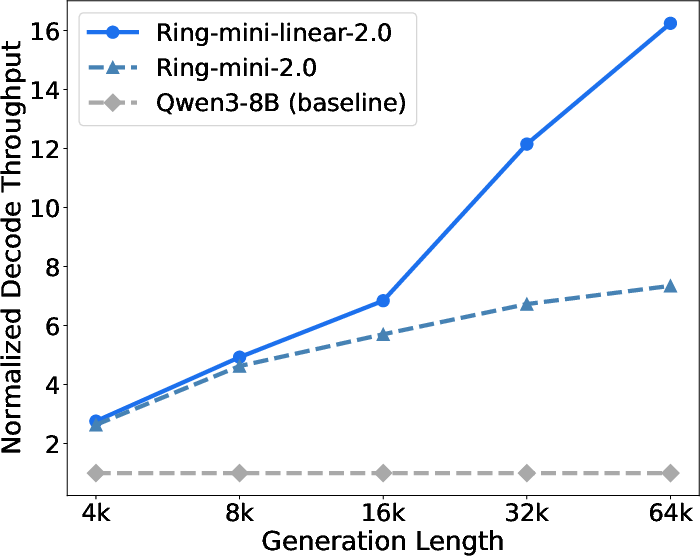
- Faster long-context processing:
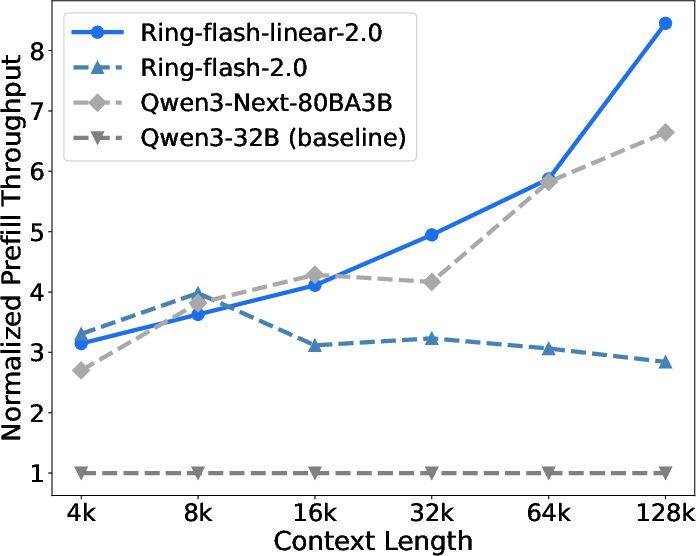
- Prefill (reading the prompt) becomes 2.5× faster than their softmax-only Ring models once the context is longer than 8K, and over 8× faster at 128K.
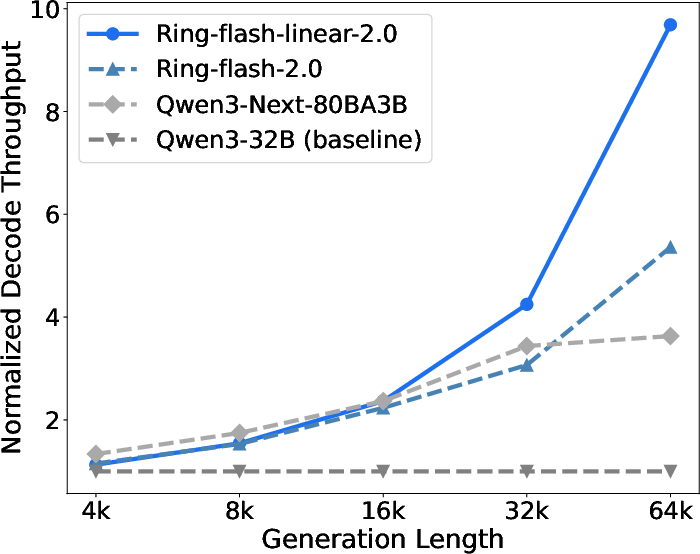
- Decode (writing the answer) becomes 2× faster at long lengths and over 10× faster than some baselines.
- Strong, stable reasoning:
- The hybrid approach matches or beats pure softmax models in retrieval and long-context tasks.
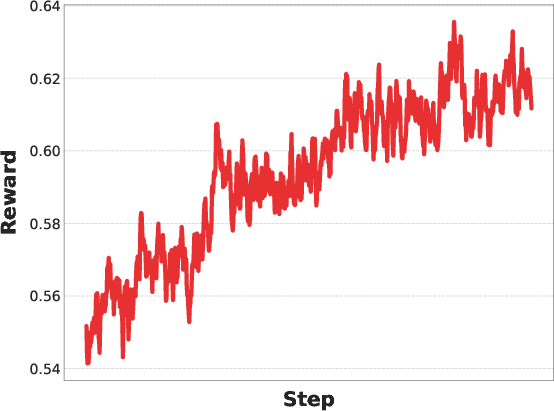
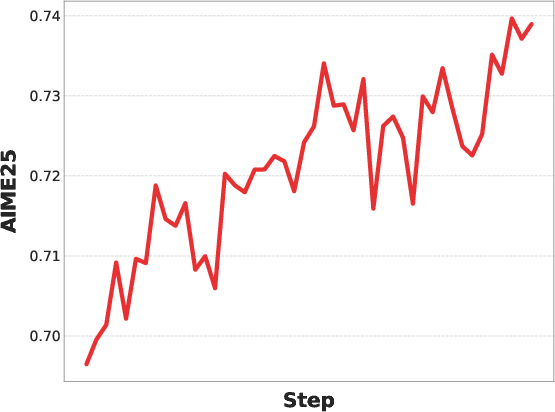
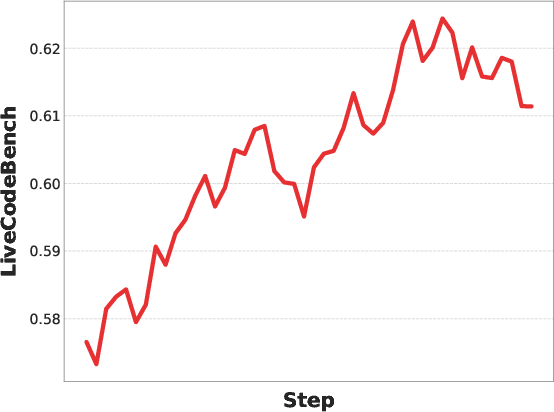
- After careful RL alignment, training stops “collapsing,” and rewards and test scores steadily improve.
- Works with modern inference stacks:
- They integrated their faster linear attention kernels into popular serving systems (SGLang and vLLM).
- They added speculative decoding (the model “guesses ahead” to generate faster), even for linear attention, by supporting tree-shaped attention masks.
In short, the models stay smart but get much cheaper and faster, especially for very long inputs.
What could this change?
These models make advanced long-context reasoning more practical in real-world apps:
- Agents that need to read long logs or plan over many steps can do so faster and cheaper.
- Coding assistants can handle big codebases more smoothly.
- Research helpers can digest long papers or documents without hitting speed or memory limits.
- RL-based training for reasoning models becomes more reliable, which could keep pushing performance forward.
By sharing two open models (Ring-mini-linear-2.0 and Ring-flash-linear-2.0) and the techniques behind them, this work helps the community build AI systems that are both powerful and efficient, especially when the “context” (the amount of text the model considers) gets very large.
Key terms in simple words
- Attention: How the model decides which earlier words matter now.
- Softmax attention: A thorough method that compares everything, great quality but slow for long texts.
- Linear attention: A faster method that keeps a compact summary, excellent for long inputs.
- Hybrid attention: Mixing linear and softmax layers to get speed and quality.
- KV cache/state: The model’s memory of what it has read; linear attention keeps this small and fixed.
- Mixture-of-Experts (MoE): Many specialist mini-models; only a few are used per token to save compute.
- Prefill vs decode: Prefill is reading the prompt; decode is generating the answer.
- FP8/FP32: Different number formats; FP8 is faster but lower precision; FP32 is slower but very accurate.
- Kernel fusion: Combining multiple GPU steps so data moves less and runs faster.
- Reinforcement learning (RL): Training with rewards to improve how the model reasons and decides.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, written to guide concrete future research.
- Lack of long-context accuracy evaluations to substantiate retrieval/extrapolation claims (e.g., LongBench, RULER, Needle-in-a-Haystack, LV-Eval), especially at 32K–128K contexts and beyond.
- No ablation or sensitivity analysis on the hybrid attention ratio and grouping (e.g., varying M, softmax layer placement), task- and length-specific effects, or whether adaptive/learnable scheduling of softmax vs. linear attention would outperform fixed patterns.
- Lightning/linear attention math is under-specified: missing a formal stability/expressivity analysis, error bounds vs. softmax attention, and proofs or diagnostics for degradation modes (e.g., retrieval or local feature fidelity).
- Head-wise power-law decay is reported to reduce LM loss, but there is no quantitative downstream ablation to characterize sensitivity, optimal schedules, or potential failure modes across domains (math, code, NLU).
- Partial RoPE (half dimensions) is adopted without a thorough study of its impact on long-context extrapolation, multilingual robustness, sequence periodicity, or tasks that rely on fine-grained positional cues.
- KV/state memory “cost analysis” is shown only qualitatively; missing wall-clock measurements, absolute bandwidth/bytes moved, and memory footprints across GPUs (A100/H100/H800/H20), sequence lengths, and concurrency levels.
- KV cache precision requirements (FP32 accumulation) are flagged, but the memory/performance trade-offs are not quantified at scale (e.g., d, number of heads, per-layer footprint, throughput hit for 128K contexts).
- Throughput results are normalized; absolute tokens/sec, latency distributions, and end-to-end throughput under realistic batching/packing (and fair hardware/config parity across baselines) are not provided.
- Speculative decoding with tree masks is introduced, but there is no evaluation of acceptance rates, quality impacts, end-to-end latency under realistic arrival patterns, or comparison against best-in-class speculative strategies; SGLang integration is still pending.
- MTP layers are included in architecture but disabled in some inference measurements; the quality/latency trade-offs of MTP (on and off), and its interaction with long-context decoding and RL, remain unexplored.
- Training–inference alignment is described module-by-module, yet there is no released tooling or protocol to automate activation-level alignment, verify determinism, or generalize the procedure across engines (Megatron/FSDP ↔ vLLM/SGLang) and hardware.
- PPO “rollout vs. training probability” usage is discussed, but a comprehensive algorithmic ablation (reward models, KL control, off-policy baselines, temperature/top‑p settings, clip ranges) is missing to isolate alignment effects from RL hyperparameters.
- MoE routing strategy (auxiliary-loss-free, sigmoid routing) lacks diagnostics: expert load balancing metrics, token drop/overflow rates, variance across sequence lengths, and tail behaviors under long CoT outputs.
- Data transparency is insufficient: pretraining corpus composition, deduplication, filtering, and contamination checks for evaluation benchmarks (e.g., AIME/Olympiad/LCB) are not documented; impacts on reported scores are unknown.
- Safety and reliability are under-evaluated: beyond de-noising/de-toxification, there is no systematic red-teaming or metrics on harmful content, hallucination, calibration, refusal behavior, or domain safety (e.g., medical/legal).
- Function Calling improvements are claimed, but standardized FC metrics (precision/recall of arguments, tool-call correctness, robustness to schema drift) and comparisons to strong baselines are absent.
- Cost claims (1/10 inference cost vs. 32B dense; >50% vs. Ring originals; 50% training efficiency gain) lack a detailed, reproducible cost model (hardware type, energy, batch sizes, concurrency, memory limits) and cross-hardware generalization.
- Fixed hybrid scheduling (M linear + 1 softmax per group) is used; open whether content-, task-, or length-conditioned dynamic placement (e.g., learned controllers or routing between attention types) can further improve quality/efficiency.
- Long-context capability is primarily demonstrated via throughput; there is no accuracy/robustness study on long‑document tasks (multi-hop QA, long‑range code refactoring, long agent plans) or error profiles over increasing context.
- Integration details with vLLM/SGLang (e.g., PagedAttention compatibility, packing, fragmentation, kernel portability) are not benchmarked under high concurrency or multi-tenant workloads.
- Reproducibility gaps: exact training/finetuning/RL hyperparameters (seeds, LR schedules, optimizer states, regularization), dataset splits, and checkpoint selection criteria are not fully disclosed; ablation scripts are not provided.
- Impact of design choices like Grouped RMSNorm (vs. standard RMSNorm) on convergence, cross-parallel settings, and potential communication/computation trade-offs is not empirically analyzed.
- Generalization to non-reasoning tasks (NLU, dialogue, knowledge-heavy domains) is only briefly summarized; systematic coverage, failure analyses, and domain-specific trade-offs are missing.
- Portability and maintenance of fused kernels (LingHe/Flood) across CUDA/Triton versions, drivers, and diverse GPU stacks are not discussed; testing/verification suites are not provided.
Practical Applications
Immediate Applications
Below we summarize concrete, deployable use cases enabled by the paper’s hybrid linear–softmax attention architecture, FP8 kernel stack, and training–inference alignment, along with sectors, potential tools/workflows, and feasibility notes.
- Long-context enterprise assistants over large knowledge bases
- Sectors: software, enterprise IT, legal, finance, consulting
- What: Deploy 128K-context chat/agent systems that ingest entire handbooks, wikis, policies, and multi-year email/thread histories with lower cost (up to ~10× cheaper vs dense 32B; 2.5–8× throughput gains at 128K context per paper).
- Tools/workflows: vLLM or SGLang serving with fused linear-attention kernels; RAG pipelines tuned for long prefill; Hugging Face models Ring-mini-linear-2.0 and Ring-flash-linear-2.0.
- Assumptions/dependencies: Best gains appear beyond 8K tokens; requires GPUs with kernel support (H20/H800 class) and the provided fused kernels; data governance for sensitive corpora.
- Repository-scale coding copilots and build/debug agents
- Sectors: software engineering, DevOps
- What: Code generation, refactoring, and multi-file reasoning across monorepos without chunking fragmentation; improved long decode throughput for test-time scaling in code synthesis and repair.
- Tools/workflows: Integration into IDE agents; CI “PR reviewer” agents; SGLang/vLLM backends; speculative decoding for structured code generation (tree masks).
- Assumptions/dependencies: Accurate tool-use/function calling datasets (paper provides re-synthesized FC SFT); structured decoding relies on tree-mask-compatible kernels now implemented.
- Contract, filing, and policy analysis at document scale
- Sectors: legal, finance, compliance, insurance, public sector
- What: End-to-end review and comparison of 102–103 page contracts/prospectuses/regs with fewer passes and lower KV-cache costs; improved retrieval/extrapolation vs pure softmax (hybrid ratio design).
- Tools/workflows: Batch/offline pipelines using Flood (offline inference) with speculative decoding for low-concurrency tasks; compare versions, clause extraction, risk summaries.
- Assumptions/dependencies: Quality depends on domain SFT/RL; privacy/compliance controls for sensitive PII; hybrid tuning retains retrieval quality.
- Scientific literature discovery and synthesis
- Sectors: academia, biotech/pharma R&D
- What: Ingest entire review corpora or multi-paper evidence sets in one context, summarize methods/results, map contradictions, and propose follow-ups.
- Tools/workflows: Long-context prefill (128K), RAG with citation tracking; reasoning-focused RL-stabilized models.
- Assumptions/dependencies: Correct citation/linking needs domain-validated prompts/guardrails; access to paywalled content must be licensed.
- Customer support copilots with persistent memory
- Sectors: customer service, SaaS, telecom, e-commerce
- What: Use multi-session histories and full product knowledge to resolve cases faster and reduce escalations; longer contexts improve continuity without heavy vector-store lookups.
- Tools/workflows: CRM integrations; low-latency decode with speculative decoding for tool calls; guardrails for PII handling.
- Assumptions/dependencies: Data retention policies; SOC2/GDPR constraints; prompt governance.
- Cost-efficient on-prem or private-cloud LLM serving
- Sectors: regulated industries (healthcare, finance), government, defense
- What: Lower I/O and KV-cache pressure enable practical on-prem deployments with fewer GPUs for 16B/104B models; better throughput under long contexts and long generations.
- Tools/workflows: vLLM/SGLang serving; ring-linear models; GPU scheduling for mixed prefill/decode loads.
- Assumptions/dependencies: Requires deployment of fused kernels; performance tuned for NVIDIA H20/H800-like hardware profiles.
- Faster small-batch, structured, or tool-use inference
- Sectors: agent platforms, automation, LLMops
- What: Tree-mask-capable linear attention enables speculative decoding for structured outputs (function calling, JSON schemas), improving latency for low-concurrency traffic.
- Tools/workflows: Flood offline inference now; planned SGLang port; lookahead integration.
- Assumptions/dependencies: Tree-mask kernels must be used; schema/tool catalogs must be curated.
- Stable RL post-training for reasoning models
- Sectors: AI labs, enterprise model builders, education
- What: Adopt training–inference alignment procedures (precision, kernels, determinism for RMSNorm, RoPE, KV cache, MoE routing) to prevent collapse and enable long-horizon on-policy PPO with rollout probabilities.
- Tools/workflows: Module-by-module activation checks; FP32-critical ops (KV accumulation, lm_head softmax); stable top-k routing; consistent attention backends (e.g., FlashAttention).
- Assumptions/dependencies: Requires access to both training and serving stacks to align numerics; benefits grow with longer outputs and MoE models.
- Cost-effective MoE training with FP8 fusion
- Sectors: AI platform teams, cloud providers
- What: Use LingHe FP8 operator library and fused kernels to boost throughput (reported +50% or higher), enabling more experiments per dollar on MoE reasoning models.
- Tools/workflows: FP8 quantization fusion (SiLU→Linear), state-aware recompute, fused router ops; WSM scheduler with checkpoint merging.
- Assumptions/dependencies: FP8-friendly GPUs; careful calibration to avoid quantization-induced regressions; compatibility with Megatron/FSDP pipelines.
- Long-log analytics and anomaly narratives
- Sectors: cybersecurity, SRE/observability, energy/grid ops
- What: Summarize multi-day logs or telemetry sequences (tens of thousands of tokens) and produce causal narratives or playbooks with lower compute cost than dense attention.
- Tools/workflows: Streaming prefill; hybrid attention for strong retrieval/extrapolation; integration with SIEM/SOC tools.
- Assumptions/dependencies: Data privacy; alignment for domain terms; robust prompt templates for chronological reasoning.
- Education: longitudinal tutoring and feedback
- Sectors: education technology
- What: Track student progress over semester-long histories in a single context; provide scaffolded feedback with consistent voice and memory.
- Tools/workflows: LMS integrations; 128K prefill; structured rubrics via speculative decoding.
- Assumptions/dependencies: Consent/FERPA-compliant data use; bias/safety audits; domain-tuned SFT.
- Open-source adoption and experimentation
- Sectors: academia, startups, OSS community
- What: Immediate use of Hugging Face models for research on long-context scaling, hybrid ratios (M=4/7), and RL stability techniques; reproducible kernel baselines.
- Tools/workflows: inclusionAI/Ring-mini-linear-2.0, inclusionAI/Ring-flash-linear-2.0; linghe kernels; flood; vLLM/SGLang backends.
- Assumptions/dependencies: Environment parity for deterministic alignment; careful ablations to replicate scaling-law findings.
Long-Term Applications
The following opportunities are plausible extensions that need further research, scaling, productization, or ecosystem maturation before broad deployment.
- Longitudinal clinical decision support over full EHR timelines
- Sectors: healthcare
- What: Reason over years of notes, labs, imaging summaries, and meds in a single pass to generate differential diagnoses and care plans.
- Dependencies: Strict privacy/security; clinical SFT/RL with adjudicated labels; FDA/CE regulatory pathways; robust hallucination controls; hospital IT integration.
- Continuous compliance and risk intelligence at enterprise scale
- Sectors: finance, insurance, public sector
- What: Always-on agents scan evolving regulations, filings, and internal policies to maintain control mappings and alert on drift/conflicts.
- Dependencies: Up-to-date corpora; auditable reasoning traces; policy-aware RAG; strong retrieval guarantees; hybrid attention tuning for retrieval-heavy workloads.
- Autonomous software engineering with multi-agent, long-horizon RL
- Sectors: software, robotics (sim-to-real toolchains)
- What: Coordinated agents plan, implement, test, and deploy features across large codebases with stable on-policy RL using rollout probabilities.
- Dependencies: Benchmarks and reward models for complex objectives; safe tool invocation; training–inference alignment standardized across toolchains.
- High-fidelity planning and control with sequence reasoning
- Sectors: robotics, operations research, supply chain, energy
- What: Long-horizon plan synthesis using hybrid attention to maintain global context at lower cost; policy refinement with aligned RL.
- Dependencies: Tight integration with simulators and safety verifiers; latency constraints in control loops; hardware acceleration for linear attention in edge devices.
- Personalized lifelong assistants with secure memory
- Sectors: consumer, productivity, education
- What: Private assistants that remember multi-year calendars, notes, projects, and preferences without frequent retrieval thrashing.
- Dependencies: On-device/edge-friendly inference; encryption and access controls; trustworthy memory editing and redaction; UI/UX guidelines.
- Green AI policies and procurement standards for efficient attention
- Sectors: policy, sustainability, cloud providers
- What: Encourage adoption of linear/hybrid attention and FP8 training to reduce energy per token, set reporting norms for attention KV/I-O footprints.
- Dependencies: Agreed metrics; third-party audits; hardware vendor support for efficiency counters; lifecycle carbon accounting.
- Hardware–software co-design for linear attention and FP8
- Sectors: semiconductors, cloud hardware
- What: Architect ASICs/accelerators prioritizing state-accumulation patterns (constant-size KV) and fused quantization kernels.
- Dependencies: Stable operator specs; widespread model adoption; compiler/runtime support (Triton-like) for fused paths; ROI vs general-purpose GPUs.
- Standardized training–inference alignment protocols
- Sectors: AI infrastructure, MLOps
- What: Cross-framework specs for numerics (epsilon, precision), deterministic operators (stable top-k), and activation parity tests to prevent RL collapse.
- Dependencies: Community buy-in; reference test suites; vendor cooperation (inference engines, libraries); CI pipelines for alignment checks.
- Safer, faster structured decoding ecosystems
- Sectors: agent platforms, fintech/healthtech
- What: Tree-mask-capable linear attention for a wide array of schema-constrained outputs (APIs, EDI, HL7/FHIR, XBRL) with low latency.
- Dependencies: Broader support in serving stacks; formal schema validation; adversarial prompt defenses; domain-grounded rewards.
- Curriculum- and schedule-free scaling strategies at ultra-long contexts
- Sectors: AI research
- What: Extend WSM checkpoint merging and hybrid attention scaling laws to 256K–1M token contexts without quadratic cost explosions.
- Dependencies: New datasets with very long dependencies; memory-stable optimizers; robust decay/attenuation (head-wise decay) tuning at scale.
- End-to-end document intelligence suites
- Sectors: enterprise software, legal-tech, tax/accounting
- What: Full workflows—ingest, normalize, analyze, compare, draft, and file—powered by long-context models with MoE efficiency.
- Dependencies: Vertical-specific evaluation; human-in-the-loop review; redaction and lineage tooling; integration with e-signature and DMS systems.
- Real-time telemetry narratives at the edge
- Sectors: IoT, automotive, aerospace
- What: On-device summarization and anomaly reasoning over long time windows with constrained KV footprint.
- Dependencies: Edge accelerators with FP8/linear kernels; thermal/power envelopes; incremental model updates; safety certifications.
Glossary
- Ablation studies: Controlled experiments that remove or vary components to isolate their impact on performance. "we conducted extensive scaling law experiments and ablation studies to determine the final design."
- Activation-ratio MoE: The fraction of experts or parameters activated per input in a Mixture-of-Experts model; lower ratios reduce compute and memory. "Ring-linear incorporates a 1/32 activation-ratio MoE architecture,"
- Auxiliary-loss-free approach: Training MoE without the typical auxiliary balancing loss, relying on routing strategies to distribute tokens. "an auxiliary-loss-free approach~\citep{wang2024auxiliary} combined with a sigmoid routing strategy,"
- BF16: A 16-bit floating-point format (bfloat16) offering wide exponent range at reduced precision, often used for efficient training. "outputting results in FP32 (forward) or BF16 (backward)."
- Chinchilla's methodology: A scaling-law framework that fits power-law relationships between data, parameters, FLOPs, and loss to find optimal training trade-offs. "Following Chinchilla's methodology~\citep{hoffmann2022training}, we establish power-law relationships between training FLOP budget and the training loss."
- Context window: The maximum number of tokens the model can consider at once for attention and generation. "we progressively extend the context window of the models from 4K to 32K and finally to 128K,"
- Decode throughput: The rate (tokens per second) at which a model generates output tokens during the decoding phase. "decode throughput denotes the number of output tokens generated per second at a batch size of 64."
- DeltaNet: A linear-attention-based architecture designed to improve efficiency in long-sequence processing. "Approaches such as Mamba~\citep{gu2024mamba}, Gated Linear Attention~\citep{yang2023gated}, and DeltaNet~\citep{yang2024parallelizing} have been introduced,"
- FLOP budget: The total number of floating-point operations allocated or measured for training, used in scaling-law analyses. "we establish power-law relationships between training FLOP budget and the training loss."
- FlashAttention: An optimized attention kernel/algorithm that reduces memory movement and accelerates softmax attention. "e.g., FlashAttention~\citep{dao2022flashattention}."
- FP8: An 8-bit floating-point format enabling faster GEMM and reduced memory traffic with appropriate quantization. "by leveraging our self-developed high-performance FP8 operator library--linghe,"
- FSDP: Fully Sharded Data Parallel; a training paradigm that shards model parameters, gradients, and optimizer states across devices. "training (e.g., Megatron, FSDP) and inference (e.g., vLLM, SGLang) frameworks."
- GEMM: General Matrix–Matrix Multiplication, a core linear algebra operation heavily used in neural network layers. "Compared to BF16 GEMM, FP8 GEMM offers significantly improved computational speed."
- Gated Linear Attention: A linear attention variant that introduces gating to modulate attention contributions, improving expressivity. "Approaches such as Mamba~\citep{gu2024mamba}, Gated Linear Attention~\citep{yang2023gated}, and DeltaNet~\citep{yang2024parallelizing} have been introduced,"
- GQA (Grouped Query Attention): An attention variant that groups queries to reduce KV cache size and computation while preserving performance. "each layer group consisting of linear attention blocks and a Grouped Query Attention (GQA) block."
- Grouped RMSNorm: Performing RMSNorm locally per group/rank to avoid cross-device reductions under tensor parallelism. "Grouped RMSNorm"
- Head-wise Decay: Per-attention-head decay coefficients applied to linear-attention states to control temporal influence or forgetting. "using a power-law decay rate for the head-wise decay, as opposed to a linear decay rate, resulted in a reduction of approximately 0.04 in the training LM loss."
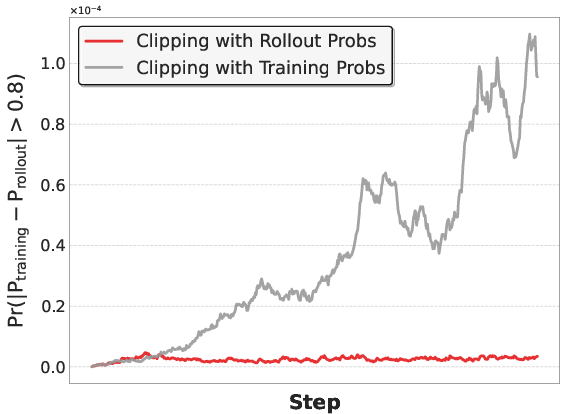
- Importance sampling: A technique in RL to reweight samples based on probability ratios between policies to reduce bias. "where the true rollout sampling distribution is used for importance sampling weighting."
- KV cache: The stored key/value tensors used during autoregressive generation to avoid recomputing attention over past tokens. "requires Key-Value (KV) cache storage that scales linearly with sequence length."
- Knowledge forgetting: The phenomenon where continued training causes a model to lose previously acquired knowledge or skills. "which may be attributed to the knowledge forgetting problem~\citep{ibrahim2024simplescalablestrategiescontinually} during the continued pre-training process."
- Lightning Attention: A specific implementation of linear attention enabling recurrent prediction with constant KV cache. "we employ Lightning Attention~\citep{qin2023transnormerllm} as the specific implementation of linear attention."
- Linear Attention: An attention mechanism with time/memory complexity that scales linearly with sequence length and constant state memory. "To address these challenges, research on Linear Attention has progressed rapidly."
- Lookahead: An inference acceleration framework enabling advanced decoding strategies. "integrating it with our previous work lookahead~\citep{zhao2024lookaheadinferenceaccelerationframework}."
- Megatron: A large-scale training framework (Megatron-LM) used for efficient distributed training of transformer models. "compare with the native blockwise FP8 mixed-precision training method provided by Megatron~\footnote{https://github.com/NVIDIA/Megatron-LM}"
- MHA (Multi-Head Attention): The standard transformer attention that computes multiple attention heads and combines them for expressivity. "Traditional architectures such as MHA~\citep{vaswani2017attention}, GQA~\citep{ainslie2023gqa}, MQA~\citep{shazeer2017outrageously} and MLA~\citep{liu2024deepseek}"
- MLA: A KV-efficient attention variant (as used by DeepSeek) optimizing memory access during decoding. "Existing approaches, such as GQA~\citep{ainslie2023gqa} and MLA~\citep{liu2024deepseek}, similarly aim to improve decoding efficiency by optimizing KV cache memory access."
- MoE Router: The component in Mixture-of-Experts that assigns tokens to experts, often sensitive to precision and determinism. "MoE Router: The baseline approach requires casting hidden states to FP32 before computing the router,"
- MQA (Multi-Query Attention): An attention variant that shares keys/values across multiple queries to reduce memory and compute. "Traditional architectures such as MHA~\citep{vaswani2017attention}, GQA~\citep{ainslie2023gqa}, MQA~\citep{shazeer2017outrageously} and MLA~\citep{liu2024deepseek}"
- Multi-Token Prediction (MTP): Layers that predict multiple future tokens per step to improve decoding efficiency or training signals. "Multi-Token Prediction (MTP) layers,"
- On-policy: RL assumption that the data used for updates is sampled from the current policy being optimized. "Such training-inference disparity undermines the theoretical assumption of on-policy,"
- Partial-RoPE: Applying Rotary Position Embeddings to only a subset of dimensions to balance efficiency and performance. "QK-Norm, Partial-RoPE, and other advanced techniques."
- Pipeline parallelism (PP): Distributing sequential layers across devices to increase throughput and fit larger models. "pipeline parallelism (PP)=6, virtual pipeline parallelism (VPP)=2,"
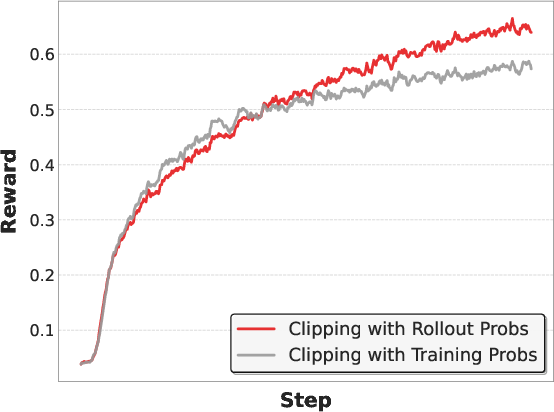
- PPO clip: The clipping mechanism in Proximal Policy Optimization that stabilizes updates by limiting probability ratio changes. "Comparison of PPO clip using rollout probabilities versus training probabilities."
- Prefill throughput: The rate (tokens per second) of processing the input prompt before generation in batched or single-request scenarios. "Prefill throughput refers to the number of input tokens processed per second at a batch size of 1,"
- QK-Norm: Normalization applied to queries and keys to stabilize attention computations. "These include expert granularity, the shared-expert ratio, attention balance, an auxiliary-loss-free approach~\citep{wang2024auxiliary} combined with a sigmoid routing strategy, Multi-Token Prediction (MTP) layers, QK-Norm, Partial-RoPE, and other advanced techniques."
- QKV projection: Linear projections that produce query, key, and value tensors from input hidden states. "Specifically, the QKV projection in each Linear Attention layer is converted to MHA by expanding parameters along the head dimension,"
- Quantization Fusion: Fusing quantization into neighboring kernels (e.g., activations) to reduce I/O and latency. "Quantization Fusion: Quantizaiton layers are usually placed after activation or normalization layers."
- RMSNorm: Root Mean Square Layer Normalization, a normalization technique avoiding mean subtraction to stabilize training. "To avoid the all-reduce operations required by a standard RMSNorm layer"
- RoPE (Rotary Position Embedding): A position encoding method applying complex rotations to Q/K vectors for relative positional awareness. "we applied the RoPE operation (which was applied to only half of the dimensions)."
- Rollout probabilities: Policy probabilities computed during inference rollouts, used for importance sampling or PPO updates. "After systematic training-inference alignment, using rollout probabilities instead of recomputed training probabilities yields higher rewards"
- Scaling law: An empirical relation (often power-law) between model/training scale and performance used to guide design. "we conducted extensive scaling law experiments and ablation studies to determine the final design."
- SGLang: An optimized LLM inference engine supporting advanced attention kernels and serving modes. "we developed a set of optimized fused linear attention kernels and integrated them into both SGLang and vLLM for the Ring-linear models."
- Softmax Attention: Traditional attention computing normalized similarity weights via softmax, with quadratic complexity in sequence length. "the computational complexity of traditional Softmax Attention grows quadratically with sequence length,"
- Speculative decoding: An inference technique that drafts tokens with a fast model or branch and verifies them to accelerate generation. "we introduced speculative decoding tailored for hybrid linear models,"
- State memory: The recurrent state maintained by linear attention across timesteps, with constant space complexity. "and the space complexity of state memory becomes constant."
- State-aware recompute: A recomputation strategy that outputs only the necessary quantized states (e.g., x or xT) to reduce overhead. "State-aware recompute: We further optimized fine-grained recomputation."
- Stable top-k: Deterministic selection of the top-k elements to avoid discrepancies across training and inference. "the non-stable torch.topk function must be replaced with a stable implementation."
- Tensor parallelism (TP): Splitting tensors (e.g., model layers) across devices to parallelize compute and fit larger models. "tensor parallelism (TP) of 2,"
- Triton kernel: A custom GPU kernel written in Triton for high-performance, fused operations. "This allows us to use only one Triton kernel"
- vLLM: A high-throughput LLM serving framework with efficient KV management and batching. "we developed a set of optimized fused linear attention kernels and integrated them into both SGLang and vLLM for the Ring-linear models."
- Virtual pipeline parallelism (VPP): Creating virtual pipeline stages to balance workload and improve utilization in pipeline-parallel training. "virtual pipeline parallelism (VPP)=2,"
- Warmup-Stable-Decay (WSD): A learning-rate schedule with an initial warmup, a stable phase, and a decay period. "the standard Warmup-Stable-Decay (WSD) learning rate scheduler~\citep{hu2024minicpmunveilingpotentialsmall}"
- Warmup-Stable-Merge (WSM): A decay-free learning-rate strategy that merges mid-training checkpoints to emulate decay effects. "with the Warmup-Stable-Merge (WSM) scheduler~\citep{tian2025wsmdecayfreelearningrate}."
Collections
Sign up for free to add this paper to one or more collections.

