Rethinking Transformer Connectivity: TLinFormer, A Path to Exact, Full Context-Aware Linear Attention
Abstract: The Transformer architecture has become a cornerstone of modern artificial intelligence, but its core self-attention mechanism suffers from a complexity bottleneck that scales quadratically with sequence length, severely limiting its application in long-sequence tasks. To address this challenge, existing linear attention methods typically sacrifice model performance by relying on data-agnostic kernel approximations or restrictive context selection. This paper returns to the first principles of connectionism, starting from the topological structure of information flow, to introduce a novel linear attention architecture-\textbf{TLinFormer}. By reconfiguring neuron connection patterns, TLinFormer achieves strict linear complexity while computing exact attention scores and ensuring information flow remains aware of the full historical context. This design aims to bridge the performance gap prevalent between existing efficient attention methods and standard attention. Through a series of experiments, we systematically evaluate the performance of TLinFormer against a standard Transformer baseline on long-sequence inference tasks. The results demonstrate that TLinFormer exhibits overwhelming advantages in key metrics such as \textbf{inference latency}, \textbf{KV cache efficiency}, \textbf{memory footprint}, and \textbf{overall speedup}.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to make Transformers (the kind of AI model behind tools like ChatGPT) much faster and more memory‑friendly when they read or generate very long texts. The authors propose a model called TLinFormer that keeps the full power of attention (it still calculates exact Softmax attention, not an approximation) but makes the total work grow only in a straight line with the text length (called “linear complexity”). That means it can handle long documents more efficiently without throwing away important information.
What questions are the researchers asking?
- Can we redesign the Transformer so it processes long sequences with strictly linear cost, instead of the usual much heavier cost?
- Can we do that while still computing exact attention (no math shortcuts that hurt accuracy)?
- Can the model still “know” about the entire past context, not just a small piece of it?
- Can this design be dropped into today’s Transformer stacks easily and speed up inference (generation) while using much less memory?
How does TLinFormer work? (Simple explanation)
The problem with regular attention
In a standard Transformer, every word looks at every other word to decide what’s important. If your text has N words, that “look at everything” step costs about N×N work, which becomes very expensive for long texts.
The idea: change the “roads” between neurons
Instead of changing the math to approximate attention (which can lose accuracy), TLinFormer changes how the parts of the network are connected—like redesigning a city’s road map so traffic flows better. This keeps attention exact but routes information more efficiently.
Two windows: a magnifying glass and a notebook
Think of reading a huge book with:
- A magnifying glass over the part you’re working on now (the generation window).
- A small but smart notebook that summarizes everything you read before (the historical window).
At each step:
- The model reads and updates the “now” part (generation window).
- It uses the “notebook” (historical window) to bring in full context from the entire past.
- The past summary can be reused many times (like keeping notes), which saves time and memory.
During training, the model slides this magnifying glass forward chunk by chunk (a “sliding window”), always carrying the notebook summary of what came before.
Attention types, in plain words
Attention is like asking: “Which parts of the text should I focus on right now?”
- Self-attention: each word can look at all the words (full view).
- Causal self-attention: each word only looks at earlier words (no peeking into the future).
- Focused attention: only some positions ask the questions, but they can look over the whole past to make a smart summary (like “reporter” tokens).
- Cross-attention: the current part (generation window) asks questions to the summarized past (historical window) to pull in any needed information.
TLinFormer combines these so the current tokens talk to each other (causal self‑attention) and also consult the full past (cross‑attention to the summary), while keeping computations small and reusable.
Caching: reusing your work
“Cache” here is like keeping your notes so you don’t recompute everything every time:
- Cache miss: when things change a lot (e.g., at the start), you must do more work.
- Cache hit: most of the time during generation, you reuse the past summary and only update the small “now” part. That’s fast.
Because the historical summary stays still for many steps, TLinFormer avoids repeatedly touching the entire long past, which makes generation much faster.
What did they find?
- Exact attention with linear scaling: TLinFormer keeps the exact Softmax attention but makes the total cost grow linearly with text length, not quadratically.
- Much faster inference and better memory use: During generation, most steps are cache hits, so the model mainly updates a small window. This leads to large speedups and a dramatically smaller KV cache (the memory used to store keys and values for attention). In typical settings, the cache memory can drop by about 10× or even more compared to a standard Transformer of similar depth.
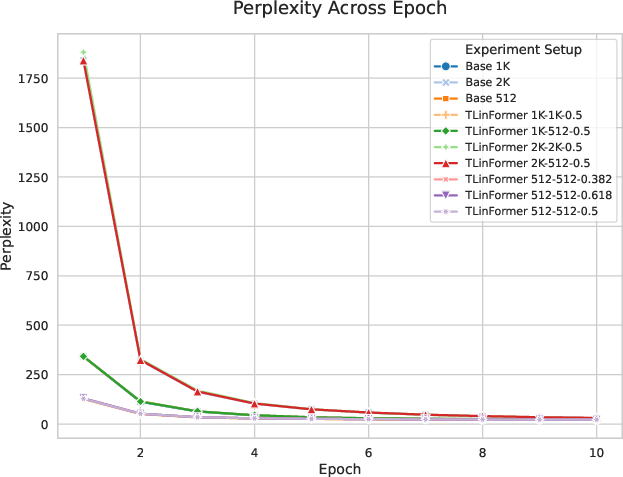
- Performance stays strong: On the WikiText‑103 dataset with a small ~41M‑parameter model:
- When TLinFormer’s “observation window” (the part it actively looks at) is the same size as the baseline model’s context, their accuracy (measured by perplexity) is almost the same.
- If TLinFormer uses a smaller window than the full sequence, there’s a small, understandable drop in accuracy because the model is forced to compress more history into a smaller summary. The authors argue this trade‑off is controlled and often worth it for the efficiency gains.
- Results were stable across different window settings, showing the design is robust.
- Plug‑and‑play design: You can stack TLinFormer blocks like normal Transformer layers.
Why this matters: It shows you don’t have to choose between speed and correctness—TLinFormer keeps exact attention while scaling efficiently.
Why is this important?
- Longer context on the same hardware: You can process much longer documents, code, audio, or videos without running out of memory.
- Faster responses: Autoregressive generation (writing one token after another) becomes much faster because most steps reuse cached summaries.
- No approximations needed: TLinFormer keeps the original attention math, so it avoids the accuracy losses that some “efficient” methods suffer.
- Practical and flexible: It can be swapped into existing Transformer setups and tuned by changing window sizes to balance accuracy and speed for your task and hardware.
Final takeaway
TLinFormer rethinks the Transformer’s “road map” so information flows efficiently: the model keeps a reusable summary of the past and focuses attention where it matters now. This delivers exact, full‑context attention with strictly linear cost, faster generation, and much lower memory use. It opens the door to training and running powerful long‑context models on more affordable hardware, and it can be adopted in today’s Transformer pipelines with minimal disruption.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable gaps for future work:
- Formal definition and proof of “full context awareness”
- Precisely define what “full context-aware” means under fixed-size historical windows and provide a theorem (or counterexample) showing whether TLinFormer can simulate full NxN attention or only approximate it, including conditions and limits.
- Quantify how information loss accumulates through repeated compress–integrate cycles across layers and window slides.
- Clarify the “exact attention” claim
- Specify in what sense attention is “exact”: it appears exact only within the active (windowed) operations rather than matching full-softmax over the entire past. Provide a formal equivalence or a bound on deviation from standard full attention.
- Missing specification of the compression mechanism
- Detail how the historical context is “compressed” in Focused Attention: How are the query positions chosen (fixed indices, strided sentinels, learned latents, pooling, or a learned router)? Is the compression learned end-to-end, and how is its capacity controlled?
- Provide ablations comparing different compression strategies and their impact on retrieval fidelity and perplexity.
- Windowing and sliding policy are under-specified
- Precisely define W_oh (historical window), W_og (generation window), stride S, and update rules on window slide. Include pseudocode for training and inference, especially the cache invalidation/refresh steps at boundaries.
- Analyze boundary effects: performance degradation near window edges, cold-start cost after sliding, and whether information “drift” occurs over many slides.
- Complexity analysis needs complete, reproducible derivations
- Several equations contain missing symbols and dangling terms; provide the full derivations with all variables defined, including attention head count, per-head dimensions, and constants absorbed in C0 and C1.
- Extend analysis to training-time backpropagation (FLOPs and memory), not only forward/inference. Include the cost of gradients through cross- and focused-attention and the impact of activation checkpointing.
- Empirical efficiency evidence is incomplete
- Report actual wall-clock speedups, tokens/sec, latency-per-token, and memory usage across a range of sequence lengths and batch sizes, with and without cache hits, and over multiple GPUs.
- Compare against strong efficiency baselines (e.g., FlashAttention-2/3, paged attention/vLLM, Mamba/SSMs, Recurrent Memory Transformers, Compressive Transformer, BigBird/Longformer) under compute- and memory-matched settings.
- Limited evaluation scope and scale
- Move beyond a 41M-parameter model on Wikitext-103-v1: test larger models (e.g., 0.5B–7B+) and longer contexts (e.g., 32K–1M tokens).
- Include long-range retrieval benchmarks (e.g., Needle-in-a-Haystack, LRA, PG19, multi-hop QA) to substantiate “full context-aware” claims.
- Evaluate domain transfer (code, books/copyright-free long narratives, scientific/math corpora) and generative quality under extreme lengths.
- Robustness and stability under forced compression
- Characterize optimization stability, gradient flow, and convergence with varying compression ratios, depths H, and window splits. Report failure modes (e.g., recency bias, catastrophic forgetting of early tokens).
- Study sensitivity to learning rate schedules, dropout, layernorm placements, and residual weighting between causal self-attn and cross-attn in the generation path.
- Positional information under compression
- Specify and evaluate how positional encodings (absolute, rotary, ALiBi, learned) are preserved through compression and how positional distance is represented in the historical summary.
- Analyze degradation of retrieval accuracy as a function of token distance.
- Memory and cache model validation
- Empirically validate the KV cache memory ratio 1/(H+2) across hardware and implementations, including fragmentation and framework overhead (e.g., torch.cat costs, allocator behavior).
- Provide a bandwidth/IO model explaining when static historical caches dominate speed and when generation-window recomputation becomes the bottleneck.
- Integration and kernel support
- Describe kernel-level implementations (custom CUDA, Triton) needed to realize the claimed cache friendliness; show performance with and without specialized kernels.
- Detail how TLinFormer can be “plug-and-play” within standard Transformer codebases given its dual-path (history/generation) topology and window bookkeeping.
- Theoretical justification via compressed sensing requires validation
- The use of n > C log N intuition for language sequences is speculative; empirically test how small the historical window can be before task performance collapses, and estimate information-retention curves vs. window size.
- Automatic window scheduling
- Develop content-aware or learned policies to adaptively allocate W_oh and W_og per sequence or layer, and measure trade-offs between accuracy and efficiency versus fixed splits.
- Reproducibility details are insufficient
- Release code, training scripts, seeds, exact optimizer settings (schedule, betas, weight decay), token budgets, and checkpoints to enable independent verification.
- Provide the missing figures and appendices referenced in the text (e.g., full complexity derivation, inference analysis plots).
Collections
Sign up for free to add this paper to one or more collections.

