- The paper introduces hybrid linear attention architectures that integrate full and linear attention layers to enhance recall performance while maintaining efficiency.
- The study empirically analyzes gating mechanisms, hierarchical recurrence, and controlled forgetting, highlighting their roles in optimizing model performance.
- The analysis reveals that optimal linear-to-full attention ratios enable models to achieve Transformer-level recall with reduced computational costs.
Systematic Analysis of Hybrid Linear Attention
This essay provides a detailed examination of the paper titled "A Systematic Analysis of Hybrid Linear Attention" (2507.06457). The paper presents an empirical comparison of hybrid linear attention architectures against their linear and full-attention counterparts, focusing on various performance metrics, including language modeling and recall capabilities.
Introduction to Linear and Hybrid Attention Models
Linear attention mechanisms emerged as a promising approach to reduce the quadratic complexity associated with Transformer architectures, offering an alternative with O(L) complexity. Despite their efficiency, linear models often exhibit limitations in recall performance, prompting the development of hybrid architectures. These combine linear and full attention layers to leverage the benefits of both approaches, striving to match the performance of traditional Transformers while maintaining computational efficiency.
Generations of Linear Attention Mechanisms
Linear attention models have evolved through three distinct generations:
- Gated Vector Recurrence (Generation 1): This generation utilizes a single vector as a hidden state, updated through element-wise operations with learned gates.
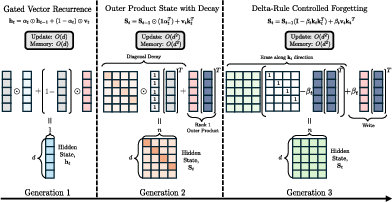
Figure 1: Three 'generations' of linear-attention state updates. Generation 1 (left): Gated Vector Recurrence keeps a single vector ht∈Rd.
- Outer-Product State with Decay (Generation 2): Extends the hidden state to a matrix, with updates performed through outer products and decay mechanisms.
- Delta-Rule Controlled Forgetting (Generation 3): Introduces a forgetting mechanism by erasing stale content and updating with new associations using a rank-1 dense transition.
The paper evaluates hybrid models by incorporating full-attention layers within linear attention architectures. It systematically analyzes various linear-to-full attention ratios, revealing insights into how these hybrids perform across different tasks.
Effects of Linear-to-Full Attention Ratios
The study finds that language modeling performance remains stable across different hybrid ratios, whereas recall capabilities significantly benefit from increased full-attention layers.
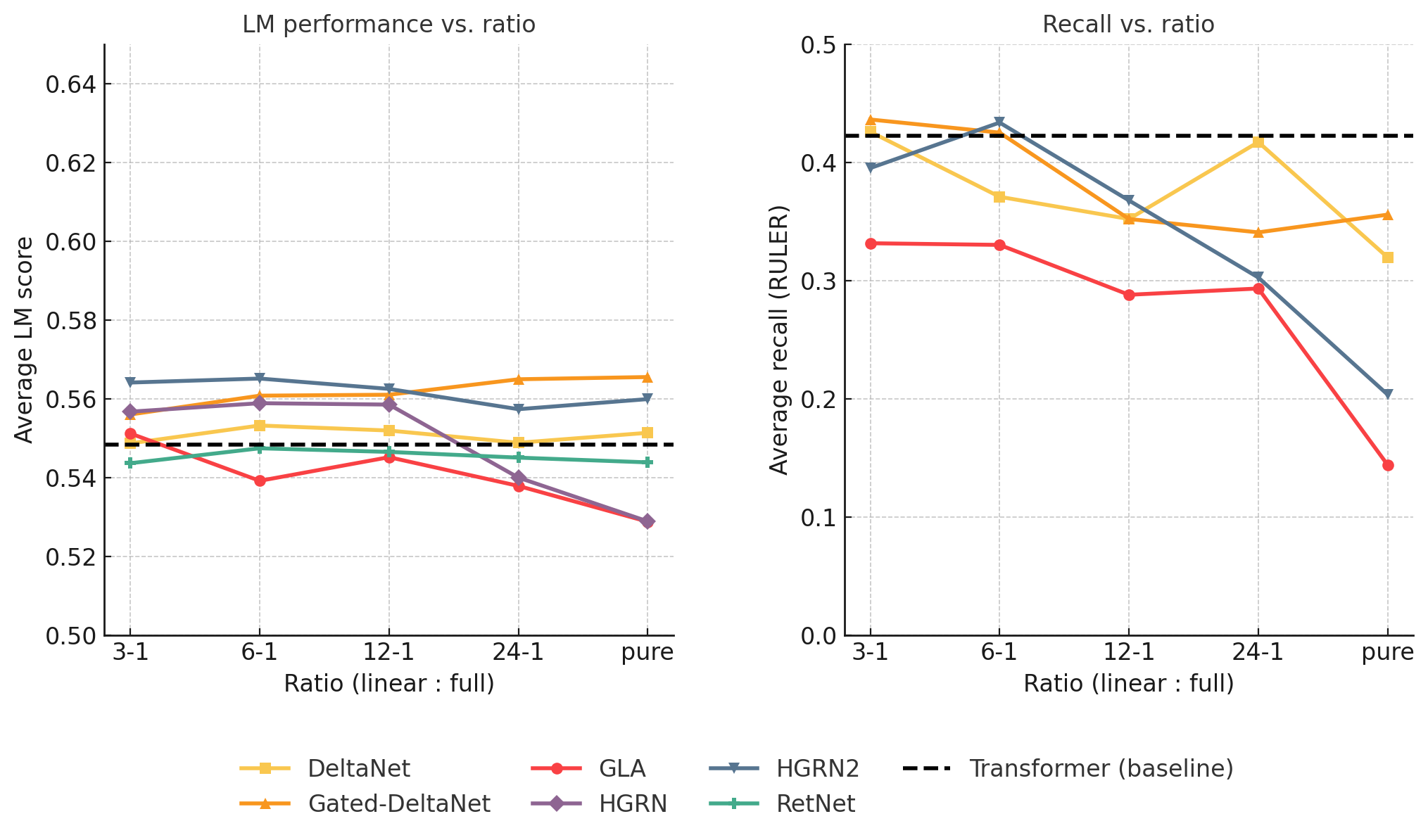
Figure 2: Language performance and recall performance tasks are averaged and compared over varying ratios.
Key Findings
- Gating Mechanisms: Selective gating, as seen in models like GatedDeltaNet and HGRN-2, is crucial for preventing the catastrophic overwriting of information, thereby enhancing recall performance.
- Hierarchical Recurrence: Models with hierarchical structures, such as HGRN-2, significantly benefit hybrid architectures by providing multi-timescale context management.
- Controlled Forgetting: The delta-rule approach of controlled forgetting, as implemented in GatedDeltaNet, helps manage state crowding, improving overall recall performance.
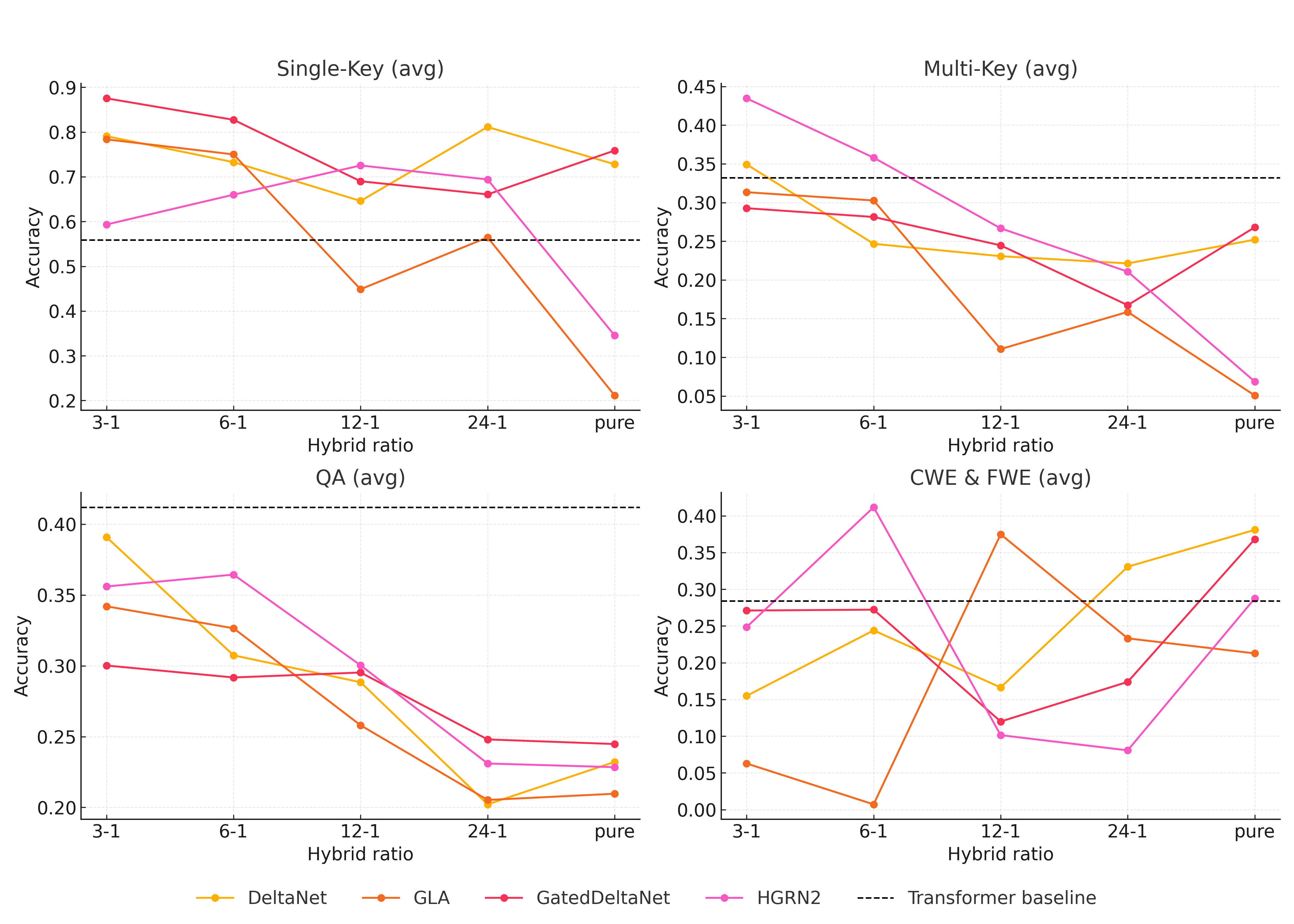
Figure 3: RULER sub task results based on ratio. RetNet and HGRN model families are omitted as their recall benchmark results were insignificant.
The paper explores the Pareto front of performance vs. efficiency, highlighting that hybrid models can achieve Transformer-level recall with substantially reduced KV cache sizes. The study emphasizes that balancing the architectural components is more critical for hybrid efficacy than standalone model performance.
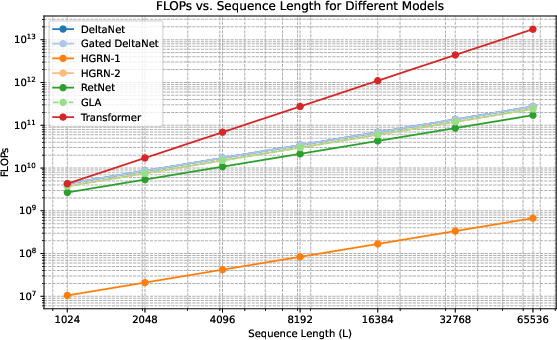
Figure 4: Relationship between the sequence length and the number of FLOPs required by different token mixers. Note that the HGRN-2 and GLA overlap, see analysis in the text.
Conclusion
The systematic exploration of hybrid linear attention models reveals that architectural choices significantly influence hybrid effectiveness, particularly in recall-dominated tasks. The study suggests that practitioners focus on optimizing gating, recurrence hierarchies, and forgetting mechanisms to strike an optimal balance between performance and computational efficiency.
While the findings provide clear guidelines for constructing efficient hybrid models, extending this analysis to larger model scales and more diverse datasets presents an exciting avenue for future research.