- The paper introduces a dual-path semantic-acoustic audio tokenizer and detokenizer that efficiently compresses speech at ultra-low bitrates while preserving intelligibility.
- It employs a multistage training strategy using convolution, transformer, and LSTM layers to achieve real-time, high-quality speech synthesis.
- Empirical evaluations show superior performance in metrics like WER, PESQ, and STOI, establishing a new benchmark for speech large language models.
LongCat-Audio-Codec: An Advanced Audio Tokenization Framework for Speech LLMs
Overview
The paper "LongCat-Audio-Codec: An Audio Tokenizer and Detokenizer Solution Designed for Speech LLMs" (2510.15227) introduces LongCat-Audio-Codec, an innovative audio processing framework optimized for Speech LLMs. Leveraging a decoupled semantic-acoustic architecture and multistage training methodologies, it achieves exceptional low-bitrate compression while maintaining high speech intelligibility.
LongCat-Audio-Codec encodes speech at an ultra-low frame rate of 16.67 Hz, with a bitrate ranging from 0.43 kbps to 0.87 kbps, demonstrating the codec's robust trade-off between efficiency and quality. This document provides an authoritative essay on its architecture, design challenges, rationale, and empirical evaluations.
Architectural Design
Tokenizer Architecture
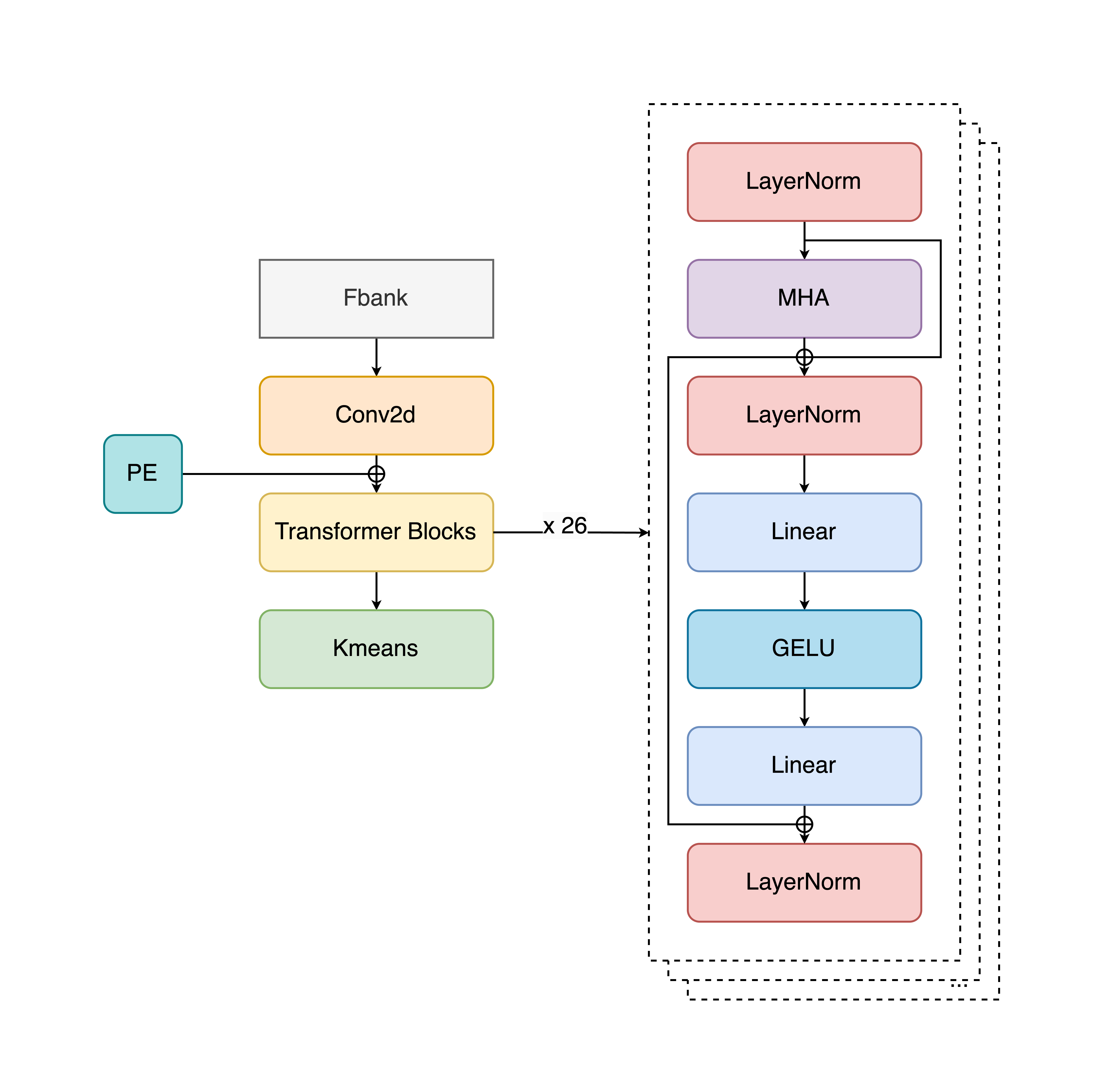
The LongCat-Audio-Codec employs a dual-path semantic-acoustic tokenizer to mitigate limitations inherent in using pure acoustic or semantic tokens alone. This configuration optimally preserves both fine-grained acoustic features and high-level semantic content.
Decoder Architecture
The audio detokenizer is optimized for streaming and low-latency operations, using LSTM and convolution layers to ensure real-time, high-quality speech synthesis (Figure 3). This design significantly reduces computational complexity compared to diffusion-based approaches.
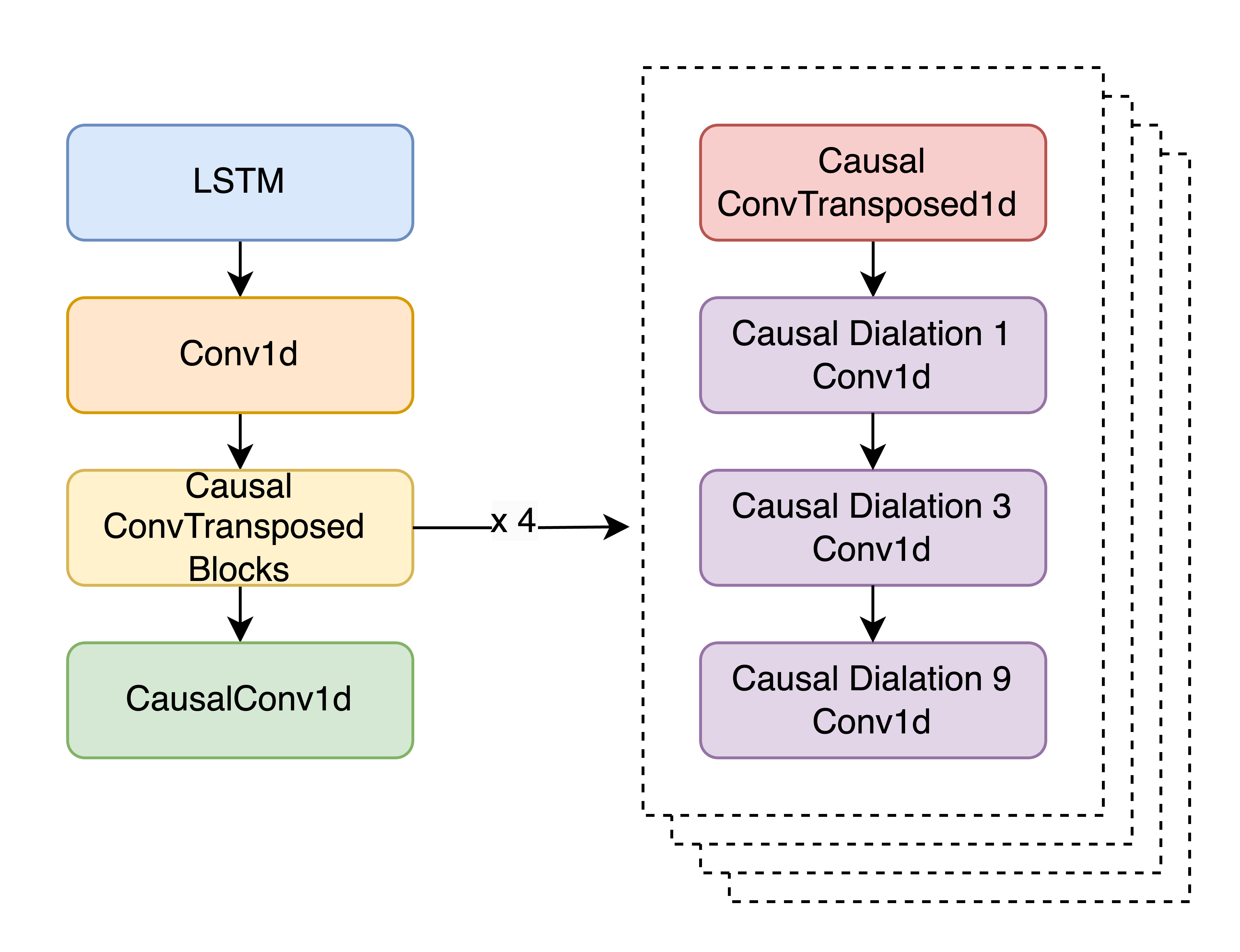
Figure 3: Architecture of detokenizer (decoder).
Design Challenges and Solutions
Text-Speech Multimodal Integration
The codec balances cross-modal understanding with efficient speech generation, exploiting semantic layers and acoustic details to enhance contextually-aware language modeling.
Model Capacity Alignment
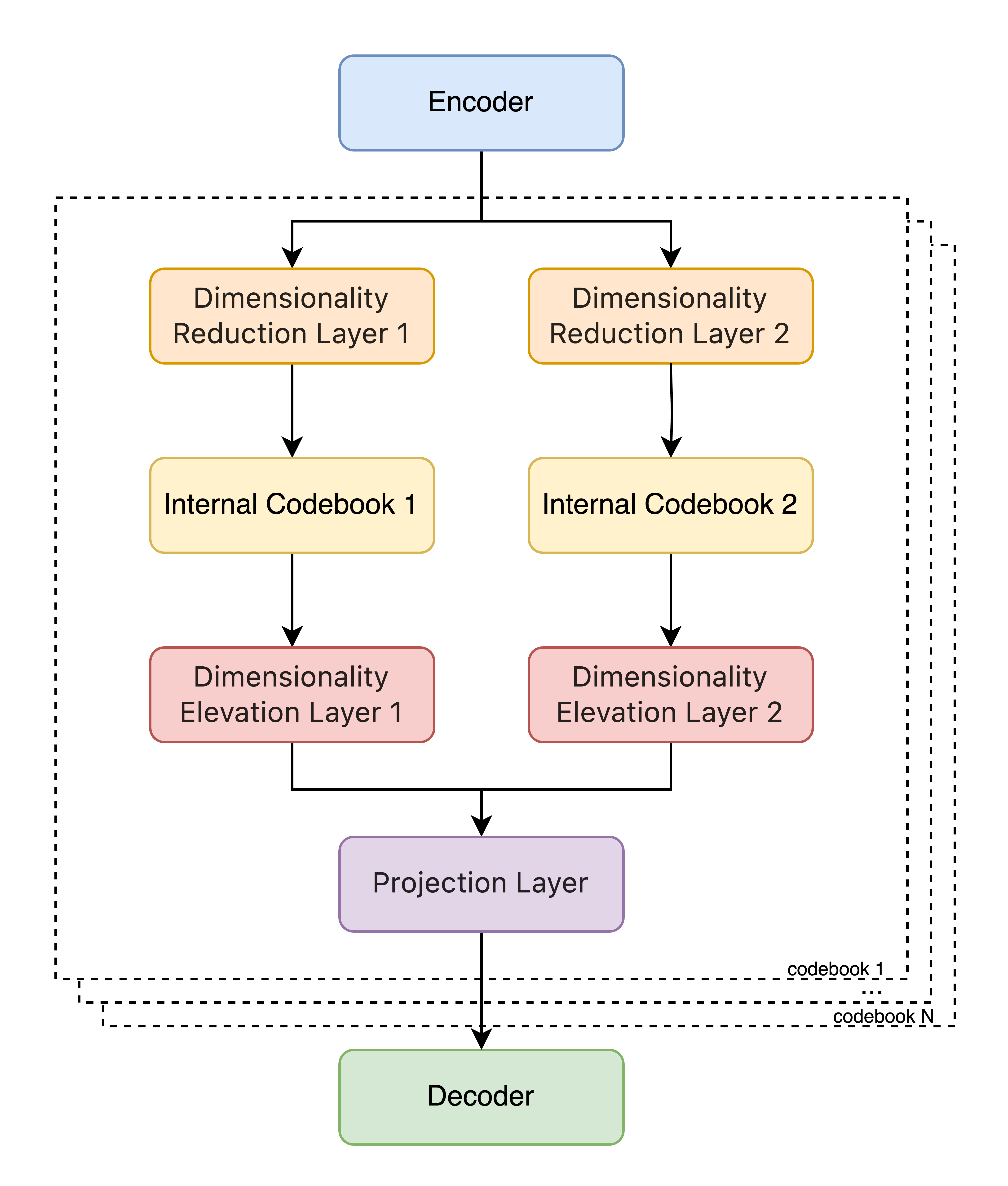
The architecture addresses differences in token density between modalities, leveraging multiple codebooks to optimize the balance between model capacity and information preservation. This ensures the model's autoregressive processes remain efficient without sacrificing intelligibility.
Training Strategy
A multistage training strategy is employed:
- Encoder Pretraining: Exposes the model to diverse data to generalize its tokenization capacity.
- Decoder Training: Utilizes high-quality data to refine audio synthesis, improving fidelity and stability.
- Targeted Fine-Tuning (optional): Adjusts decoder parameters for speaker specificity or confined scenario performance.
Empirical evaluations demonstrate LongCat-Audio-Codec's superior performance across a range of metrics, including WER, PESQ, and STOI. The codec excels in low-bitrate scenarios, maintaining intelligibility while surpassing many traditional codecs in reconstruction quality when semantic information is included.
Figure 4: Speaker similarity improvement by Stage 2 and Stage 3.
Moreover, experiments highlight the potential of fewer codebooks in maintaining robust performance, with detailed results showcasing competitive intelligibility and acoustic metric scores even at constrained bitrates (Figure 5).
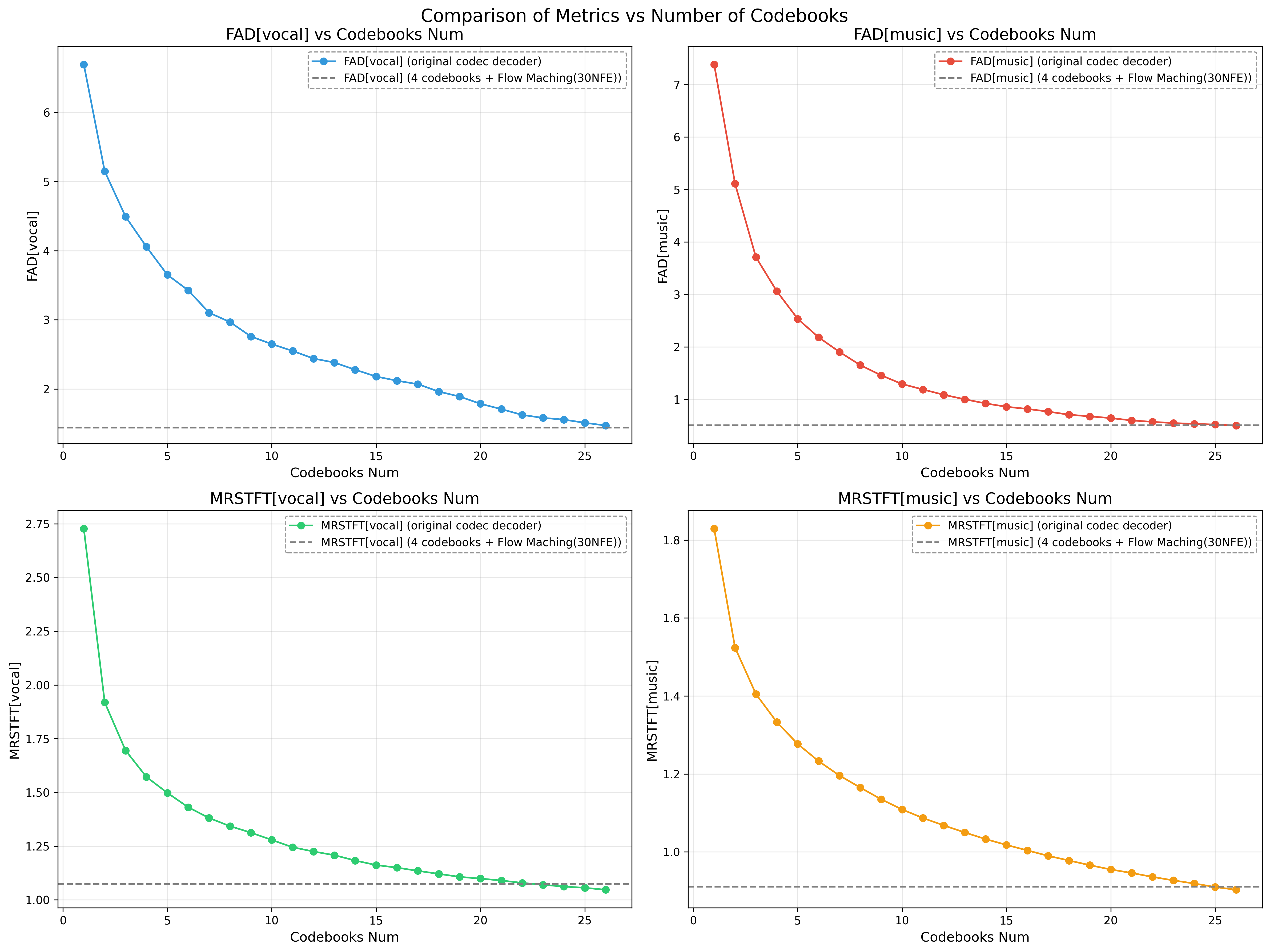
Figure 5: Potential of few codebooks.
Conclusion
LongCat-Audio-Codec establishes a new benchmark in audio tokenization for speech LLMs, balancing token efficiency with uncompromised quality. While currently designed for speech applications, future iterations aim to extend beyond current input duration limitations and enhance adaptations for music and sound effects. The modular training architecture and adaptive codebook configuration promise significant flexibility and scalability in evolving multimodal AI scenarios.