- The paper introduces a novel taxonomy for discrete audio tokenization, detailing encoder-decoder architectures, quantization techniques, training paradigms, and streamability.
- It benchmarks tokenizers on reconstruction quality and downstream tasks like ASR and TTS, emphasizing the trade-off between signal fidelity and semantic content.
- Findings highlight the role of semantic distillation in enhancing speech language modeling and suggest future research directions to optimize multimodal audio systems.
Discrete Audio Tokens: More Than a Survey!
Introduction
The paper "Discrete Audio Tokens: More Than a Survey!" presents a comprehensive analysis of discrete audio tokenization methods, primarily focusing on their application across three domains: speech, music, and general audio. Unlike traditional continuous representations, discrete audio tokens offer a more compact and efficient means to encode audio data, facilitating their integration into multimodal models like LLMs. This survey introduces a novel taxonomy for discrete audio tokenization based on encoder-decoder architecture, quantization techniques, training paradigms, streamability, and application domains, which provides a unified comparison across various benchmarks.
Taxonomy of Audio Tokenizers
The proposed taxonomy of discrete audio tokenizers focuses on several critical dimensions:
- Encoder-Decoder Architecture: Models employ a variety of architectures including convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformers to encode audio signals into latent representations (Figure 1). These embeddings are then quantized into discrete tokens, reconstructed into audio waveforms by decoders. This component is crucial as it dictates how well the model can capture the necessary audio features.
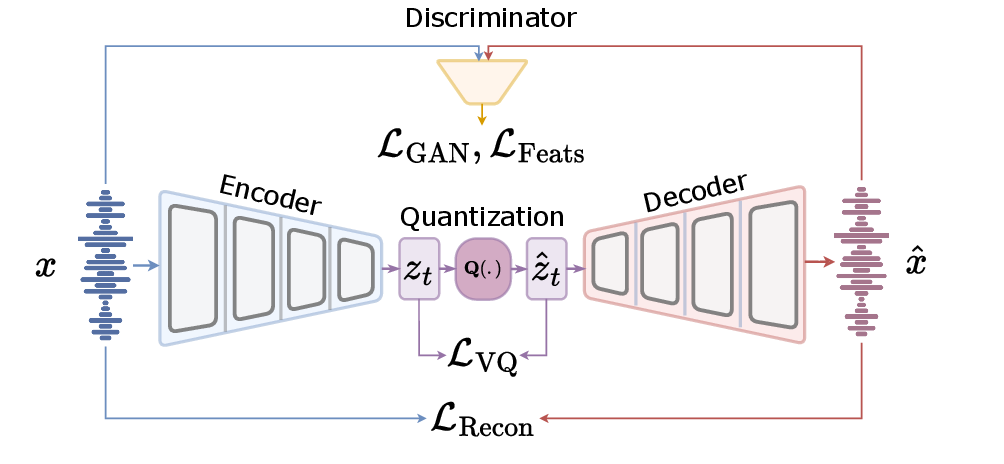
Figure 1: Overall architecture of a standard audio tokenizer.
- Quantization Technique: Methods such as Residual Vector Quantization (RVQ), Single Vector Quantization (SVQ), and K-means clustering are employed, each with its trade-offs. RVQ, prevalent due to its ability to refine residuals iteratively, supports high-fidelity audio output through layered quantization.
- Training Paradigms: The paper discusses two primary training strategies — separate (post-training) and joint (end-to-end). Joint training integrates all components, optimizing for the overall task, while separate training independently optimizes the quantizer post-training, often leveraging pre-trained models.
- Streamability and Domain Focus: Audio tokenizers may be tailored for specific domains (such as speech-only models) or designed to generalize across multiple audio types, with architecture and system constraints considered to support real-time applications where necessary.
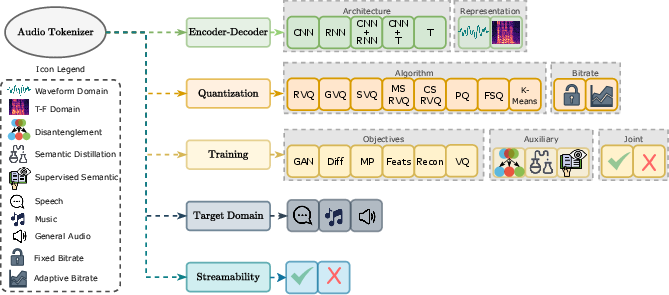
Figure 2: Taxonomy of audio tokenizers based on encoder-decoder architecture.
Benchmark Evaluation
Benchmarked across a variety of tasks, including reconstruction, generative modeling, and acoustic language modeling, discrete audio tokens exhibit varied performance.
- Reconstruction Quality: High bitrate tokenizers generally offer better signal fidelity, essential for tasks like audio transmission where quality is crucial. However, the survey reveals that reconstruction quality alone is not indicative of downstream task effectiveness, emphasizing the need for a balance between signal fidelity and semantic content retention.
- Downstream Performance: The evaluation across discriminative tasks (e.g., automatic speech recognition, ASR) and generative tasks (e.g., text-to-speech, TTS) indicates that semantic tokenizers, particularly those using semantic distillation, often outperform purely acoustic models in semantic tasks due to their ability to preserve phonetic content within tokens.
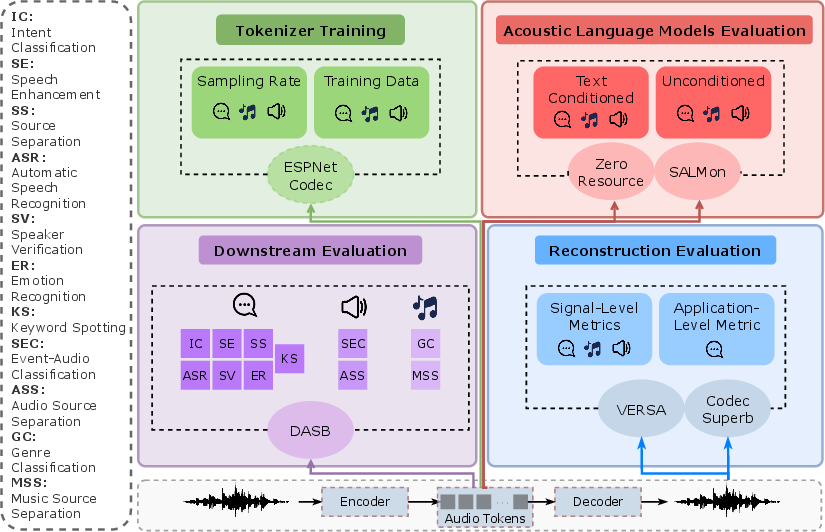
Figure 3: Overview of our empirical study, covering three domains: speech, music, and general audio.
Speech Language Modeling
Speech language modeling (SLM) using discrete tokens has gained attention for its ability to model joint distributions of speech segments, offering robust performance in both unconditional and text-conditioned environments. Testing via benchmarks like ZeroSpeech and SALMon affirms that semantically distilled tokens effectively capture phonetic intricacies facilitating semantic tasks. Nonetheless, challenges remain in balancing acoustic detail and linguistic abstraction, particularly for complex generative tasks.
Conclusion
Discrete audio tokens present a pivotal shift in audio representation, enhancing the efficiency and capability of audio processing systems. The comprehensive evaluation provided in the paper highlights both the potential and current limitations of discrete audio tokenizers. Future research directions include improving domain adaptability, optimizing semantic and acoustic fidelity trade-offs, and developing unified benchmarks for consistent evaluation. The findings underscore the promising role of discrete tokens in advancing multimodal AI systems, signifying an evolution in how audio data is approached and leveraged in deep learning architectures.

