- The paper introduces Cautious Weight Decay (CWD) that selectively applies decay based on sign alignment between optimizer updates and parameters.
- It offers a one-line modification made to optimizers like AdamW, Lion, and Muon with proven convergence via Lyapunov analysis.
- Empirical results show that CWD accelerates convergence and reduces validation loss across various model scales and tasks.
Cautious Weight Decay
The paper "Cautious Weight Decay" introduces a sophisticated optimizer modification technique that can be directly applied to well-known optimizers—such as AdamW, Lion, and Muon—without any need for additional hyperparameters or intricate tuning. This modification, termed Cautious Weight Decay (CWD), selectively applies weight decay based on the alignment of signs between optimizer updates and parameters, aiming to enhance convergence and performance in various training scenarios.
Introduction and Motivation
Optimization algorithms underpin the efficiency of training large scale models in deep learning. Among existing optimization strategies, decoupled weight decay, employed in optimizers like AdamW, is a prevalent approach that enhances training stability by adding a decay to parameters directly, preventing interference from adaptive learning rates. However, traditional decoupled decay does not consider the directional alignment of parameter updates and decay terms, potentially hampering optimization performance in non-convex landscapes.
Cautious Weight Decay Methodology
CWD advances the concept of weight decay by introducing a sign-based condition that restrictively applies decay only when the parameter and optimizer update directions agree. This one-line amendment is both optimizer-agnostic and effortlessly incorporated without increasing computational overhead. The sign-based conditional operation ensures that parameters are only adjusted towards minimization efficiently without being inadvertently counteracted by opposing directional decay.
Theoretical Insights
The introduction of CWD provides both theoretical assurances and practical benefits. By leveraging Lyapunov analysis, the paper demonstrates that CWD can integrate seamlessly into existing optimization frameworks, ensuring unbiased optimization that targets the unaltered loss function while maintaining stability. In specific scenarios, such as over-parameterized models, CWD allows trajectories to glide along stationary manifolds, effectively steering optimizations towards local Pareto-optimal solutions based on parameter magnitude minimization.
Convergence Analysis
A key highlight of the paper is its detailed convergence analysis. Provable convergence is established for CWD in continuous-time limits and discrete settings across several optimizers, which faithfully preserve original objective functions. In contrast to standard weight decay, this approach ensures that stationary points reflect genuine optima under non-convex settings, thus resolving potential biases introduced by traditional decoupled weight decay methods.
Empirical Results
Empirical validation across diverse datasets demonstrates the practical impact of CWD. Experiments encompass large-scale Transformer-based LLMs and ImageNet classification tasks, revealing consistent improvements in convergence speed and accuracy.
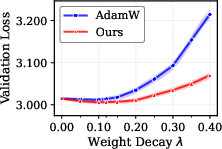
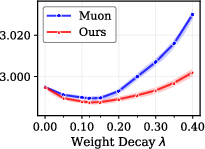
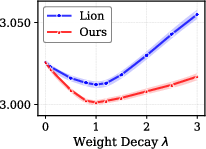
Figure 1: Final validation loss vs. weight decay coefficient λ for 338M models trained on C4 under Chinchilla scaling, showcasing CWD's superior performance.
Moreover, the consistent reduction in evaluation loss across various model scales, including 338M, 986M, and 2B parameters, underscores CWD's effectiveness (Figure 2). It is particularly noteworthy that CWD outperforms traditional decay strategies across the board, irrespective of model size or optimizer variant.
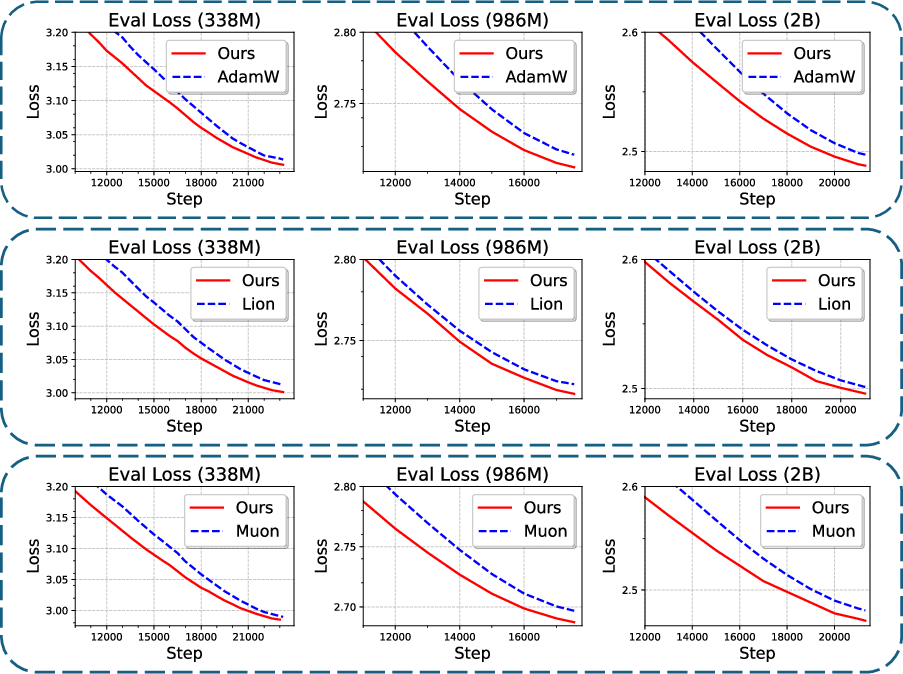
Figure 2: Evaluation loss across scales for models trained with AdamW, Lion, and Muon on the C4 dataset.
Analysis and Implications
The introduction of CWD incorporates not only theoretical robustness but also practical efficiency that does not require altering existing hyperparameter settings. This enables CWD to be a drop-in enhancement for existing optimizers, effectively compatible with large-scale, compute-optimal models without necessitating further hyperparameter tuning.
Practical Applications
In practice, CWD's selective decay mechanism translates into accelerated convergence, reduced final validation losses, and increased model robustness. The method's ability to consistently lower gradient norms (Figure 3) highlights its potential to stabilize training dynamics, a significant consideration in training very large models where gradient variability often presents challenges.
Figure 3: Comparison of gradient norms using RMS normalization across different model sizes, illustrating CWD's efficacy.
Conclusion
Cautious Weight Decay represents an innovative and practically applicable extension to standard decoupled decay methods. It enables optimizers to achieve improved performance through enhanced stability and efficient parameter trajectory exploration, without the necessity for additional hyperparameter tuning. As such, CWD stands as a significant contribution to optimization strategies in deep learning, promising both theoretical and empirical advantages for future model training endeavors and large-scale applications.