- The paper demonstrates that applying weight decay early retains low weight norms, effectively amplifying gradient updates and enhancing generalization.
- The study introduces a decoupled weight decay approach that isolates regularization from loss gradients, stabilizing hyperparameters in adaptive optimizers like Adam.
- Experimental results across reinforcement learning and NLP tasks reveal that tailored weight decay strategies can yield computational savings and performance benefits.
Understanding Decoupled and Early Weight Decay
This essay provides an in-depth technical review of "Understanding Decoupled and Early Weight Decay" by Johan Bjorck, Kilian Weinberger, and Carla Gomes. The paper explores recent developments in the use of weight decay (WD) as a regularization technique, particularly focusing on its interaction with deep learning models and adaptive optimizers.
Overview of Weight Decay Techniques
Weight decay (WD) has been a foundational technique for regularization in neural networks, traditionally implemented as an l2 penalty added to the loss function. This paper investigates two significant observations related to WD:
- Early Weight Decay: Recent findings suggest that applying WD only in the early training stages may suffice. The paper demonstrates that early WD ensures that the network's norms remain low, retaining a regularizing effect by making gradient updates effectively larger relative to the weights.
- Decoupled Weight Decay: In contrast to traditional approaches, decoupled WD manually decays weights separately from the l2 penalty. This separation helps in situations where adaptive optimizers are used, such as Adam, preventing the mixing of gradients from the objective and the regularization term.
Temporal Dynamics of Weight Decay
The paper revisits the traditional usage of WD throughout training, emphasizing the benefits of applying it only during the initial training phase. This leads to enhanced generalization due to the maintenance of low weight norms, which in turn amplifies the effective learning rate.
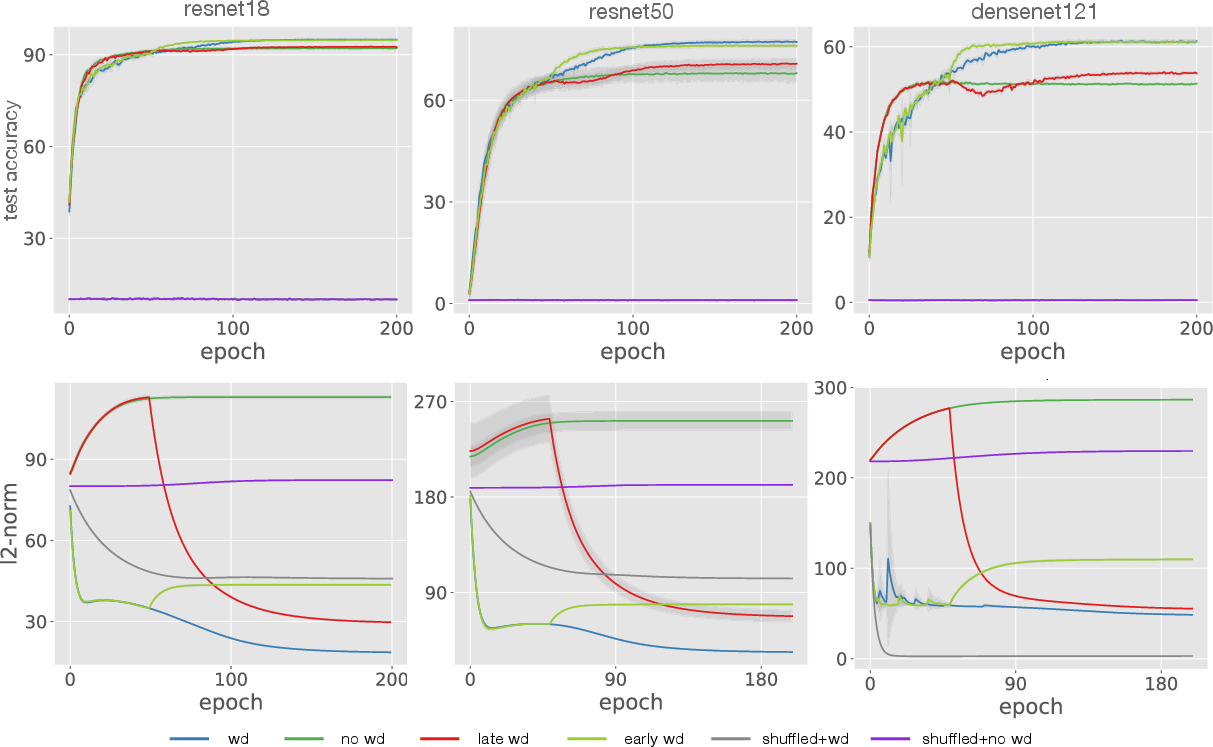
Figure 1: Application of WD remains effective when only used in early training, keeping weight norms low, as shown in experiments with shuffled labels and image datasets.
A pivotal contribution is the introduction of a scale-invariant metric to capture the effects of early WD on the sharpness of network minima. This measure, which is invariant to weight scaling, offers insights into the relationship between sharpness and generalization, filling gaps left by traditional sharpness metrics.
Decoupled Weight Decay in Adaptive Optimizers
The inefficacy of standard WD when used with adaptive optimizers like Adam is attributed to the interaction between gradient scaling and the l2 regularization. The paper illustrates how decoupled WD sidesteps these issues by avoiding the gradient signal mix in Adam's buffers.
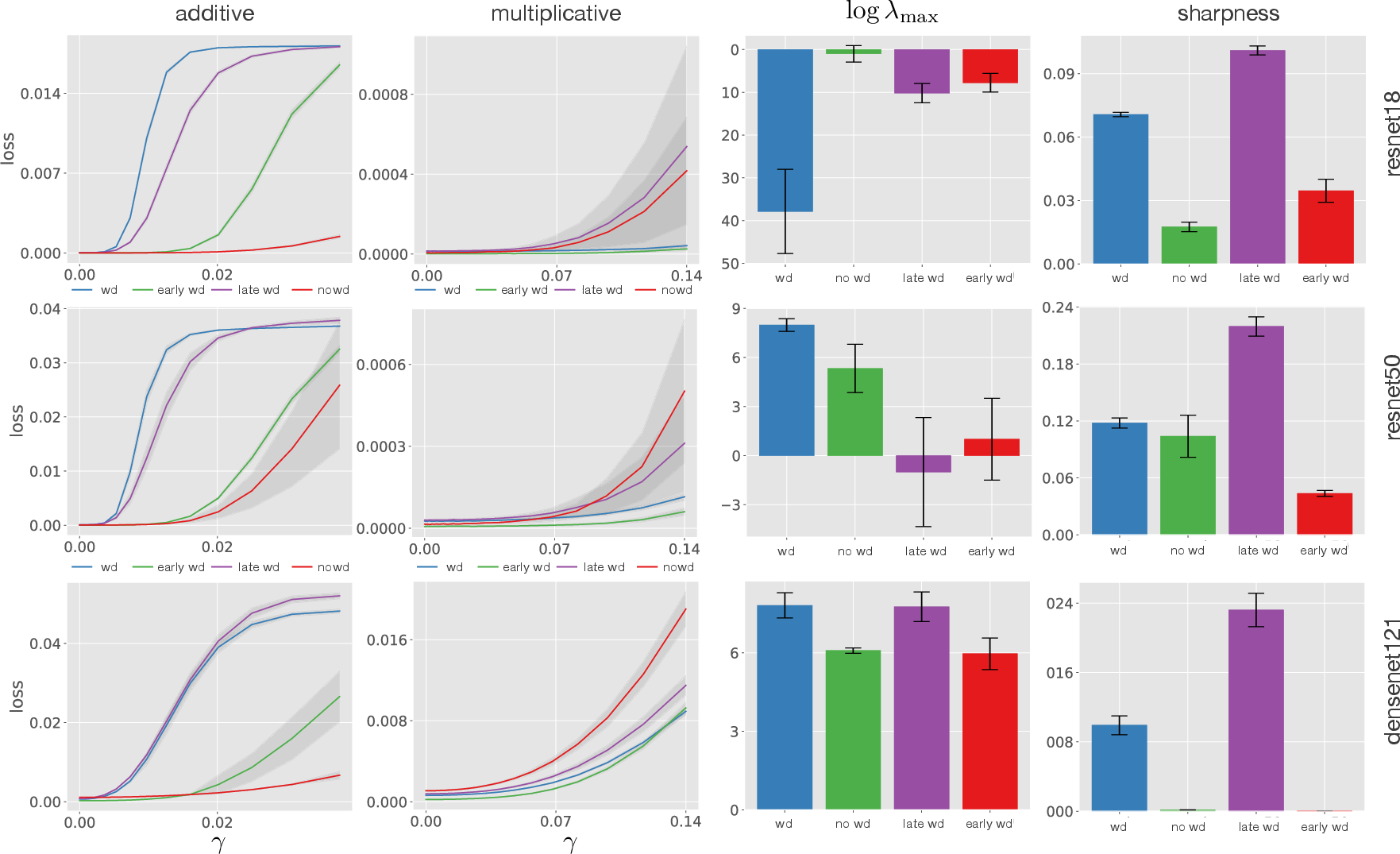
Figure 2: Learning curves illustrating the improved performance of decoupled WD across various Atari games, contrasting with standard WD.
Experiments in both reinforcement learning (RL) and NLP underline the practical value of decoupled WD. The paper's findings suggest that while decoupled WD may not always offer superior absolute performance compared to finely-tuned l2 regularization, it provides enhanced hyperparameter stability.
Implications and Conclusions
The paper highlights several implications for practitioners. It recommends early WD for datasets with strong generalization characteristics and endorses decoupled WD where adaptive optimization is prevalent. The consideration of dataset-specific norm growth suggests that practitioners tailor WD strategies to dataset generalization properties.
Furthermore, potential computational savings are discussed, with strategies like applying WD intermittently without performance detriment (stuttered WD), showcasing the potential for resource optimization in training large-scale models.
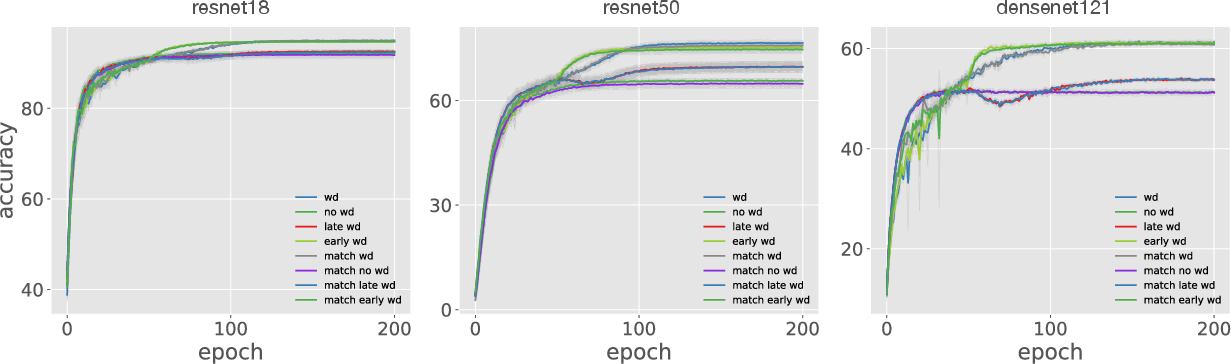
Figure 3: Demonstrates savings from applying WD every 128 updates with no performance loss across multiple datasets.
The overall contributions of this paper refine our understanding of WD's role in training dynamics and offer actionable insights for effectively incorporating WD in deep learning pipelines, thereby improving both the generalization and efficiency of trained models.

